Some months ago I read about containerlab (and here). It looked like a very simple way to build labs quickly, easily and multi-vendor. I have used in the past gns3 and docker-topo for my labs but somehow I liked the documentation and the idea to try to mix cEOS with FRR images.
As I have felt more comfortable with the years with Arista and I had some images in my laptop, I installed the software (no mayor issues following the instructions for Debian) and try the example for a cEOS lab.
It didnt work. The containers started but I didnt get to the Arista CLI, just bash CLI and couldnt see anything runing on them… I remembered some Arista specific processes but none was there. In the following weeks, I tried newer cEOS but no luck always stuck in the same point. But at the end, never had enough time (or put the effort and interest) to troubleshoot the problem properly.
For too many months, I havent had the chance (I can write a post with excuses) to do much tech self-learning (I can write a book of all things I would like to learn), it was easier cooking or reading.
But finally, this week, talking with a colleague at work, he mentioned containerlab was great and he used it. I commented that I tried and failed. With that, I finally find a bit of interest and time today to give another go.
Firstly, I made sure I was running the latest containerlab version and my cEOS was recent enough (4.26.0F) and get to basics, check T-H-E logs!
So one thing I noticed after paying attention to the startup logs, I could see an warning about lack of memory in my laptop. So I closed several applications and tried again. My lab looked stuck in the same point:
go:1.16.3|py:3.7.3|tomas@athens:~/storage/technology/containerlabs/ceos$ sudo containerlab deploy --topo ceos-lab1.yaml
INFO[0000] Parsing & checking topology file: ceos-lab1.yaml
INFO[0000] Creating lab directory: /home/tomas/storage/technology/containerlabs/ceos/clab-ceos
INFO[0000] Creating docker network: Name='clab', IPv4Subnet='172.20.20.0/24', IPv6Subnet='2001:172:20:20::/64', MTU='1500'
INFO[0000] config file '/home/tomas/storage/technology/containerlabs/ceos/clab-ceos/ceos1/flash/startup-config' for node 'ceos1' already exists and will not be generated/reset
INFO[0000] Creating container: ceos1
INFO[0000] config file '/home/tomas/storage/technology/containerlabs/ceos/clab-ceos/ceos2/flash/startup-config' for node 'ceos2' already exists and will not be generated/reset
INFO[0000] Creating container: ceos2
INFO[0003] Creating virtual wire: ceos1:eth1 <--> ceos2:eth1
INFO[0003] Running postdeploy actions for Arista cEOS 'ceos2' node
INFO[0003] Running postdeploy actions for Arista cEOS 'ceos1' node
I did a bit of searching about containerlab and ceos, for example, I could see this blog where the author started up successfully a lab with cEOS and I could see his logs!
So it was clear, my containers were stuck. So I searched for that message “Running postdeploy actions for Arista cEOS”.
I didnt see anything promising, just links back to the main container lab ceos page. I read it again and I noticed something in the bottom of the page regarding a known issue…. So I checked if that applied to me (although I doubted as it looked like it was for CentOS…) and indeed it applied to me too!
$ docker logs clab-ceos-ceos2
Failed to mount cgroup at /sys/fs/cgroup/systemd: Operation not permittedSo I started to find info about what is cgroup: link1, link2
First I wanted to check what cgroup version I was running. With this link, I could see that based on my kernel version, I should have cgroup2:
$ grep cgroup /proc/filesystems
nodev cgroup
nodev cgroup2
$ ls /sys/fs/cgroup/memory/
cgroup.clone_children memory.kmem.tcp.limit_in_bytes memory.stat
cgroup.event_control memory.kmem.tcp.max_usage_in_bytes memory.swappiness
cgroup.procs memory.kmem.tcp.usage_in_bytes memory.usage_in_bytes
cgroup.sane_behavior memory.kmem.usage_in_bytes memory.use_hierarchy
dev-hugepages.mount memory.limit_in_bytes notify_on_release
dev-mqueue.mount memory.max_usage_in_bytes proc-fs-nfsd.mount
docker memory.memsw.failcnt proc-sys-fs-binfmt_misc.mount
machine.slice memory.memsw.limit_in_bytes release_agent
memory.failcnt memory.memsw.max_usage_in_bytes sys-fs-fuse-connections.mount
memory.force_empty memory.memsw.usage_in_bytes sys-kernel-config.mount
memory.kmem.failcnt memory.move_charge_at_immigrate sys-kernel-debug.mount
memory.kmem.limit_in_bytes memory.numa_stat sys-kernel-tracing.mount
memory.kmem.max_usage_in_bytes memory.oom_control system.slice
memory.kmem.slabinfo memory.pressure_level tasks
memory.kmem.tcp.failcnt memory.soft_limit_in_bytes user.slice
As I had “cgroup.*” in my “/sys/fs/cgroup/memory” it was confirmed I was running cgroup2.
So how could I change to cgroup1 for docker only?
It seems that I couldnt change that only for an application because it is parameter that you pass to the kernel in boot time.
I learned that there is something called podman to replace docker in this blog.
So at the end, searching how to change cgroup in Debian, I used this link:
$ cat /etc/default/grub
...
# systemd.unified_cgroup_hierarchy=0 enables cgroupv1 that is needed for containerlabs to run ceos....
# https://github.com/srl-labs/containerlab/issues/467
# https://mbien.dev/blog/entry/java-in-rootless-containers-with
GRUB_CMDLINE_LINUX_DEFAULT="quiet systemd.unified_cgroup_hierarchy=0"
....
$ sudo grub-mkconfig -o /boot/grub/grub.cfg
....
$ sudo reboot.Good thing that the laptop rebooted fine! That was a relief 🙂
Then I checked if the change made any difference. It failed but because it containerlab couldnt connect to docker… somehow docker had died. I restarted again docker and tried container lab…
$ sudo containerlab deploy --topo ceos-lab1.yaml
INFO[0000] Parsing & checking topology file: ceos-lab1.yaml
INFO[0000] Creating lab directory: /home/xxx/storage/technology/containerlabs/ceos/clab-ceos
INFO[0000] Creating docker network: Name='clab', IPv4Subnet='172.20.20.0/24', IPv6Subnet='2001:172:20:20::/64', MTU='1500'
INFO[0000] config file '/home/xxx/storage/technology/containerlabs/ceos/clab-ceos/ceos1/flash/startup-config' for node 'ceos1' already exists and will not be generated/reset
INFO[0000] Creating container: ceos1
INFO[0000] config file '/home/xxx/storage/technology/containerlabs/ceos/clab-ceos/ceos2/flash/startup-config' for node 'ceos2' already exists and will not be generated/reset
INFO[0000] Creating container: ceos2
INFO[0003] Creating virtual wire: ceos1:eth1 <--> ceos2:eth1
INFO[0003] Running postdeploy actions for Arista cEOS 'ceos2' node
INFO[0003] Running postdeploy actions for Arista cEOS 'ceos1' node
INFO[0145] Adding containerlab host entries to /etc/hosts file
+---+-----------------+--------------+------------------+------+-------+---------+----------------+----------------------+
| # | Name | Container ID | Image | Kind | Group | State | IPv4 Address | IPv6 Address |
+---+-----------------+--------------+------------------+------+-------+---------+----------------+----------------------+
| 1 | clab-ceos-ceos1 | 2807cd2f689f | ceos-lab:4.26.0F | ceos | | running | 172.20.20.2/24 | 2001:172:20:20::2/64 |
| 2 | clab-ceos-ceos2 | e5d2aa4578b5 | ceos-lab:4.26.0F | ceos | | running | 172.20.20.3/24 | 2001:172:20:20::3/64 |
+---+-----------------+--------------+------------------+------+-------+---------+----------------+----------------------+
$ sudo clab graph -t ceos-lab1.yaml
INFO[0000] Parsing & checking topology file: ceos-lab1.yaml
INFO[0000] Listening on :50080... After a bit, it seems it worked! And learned about an option to show a graph of your topology with “graph”
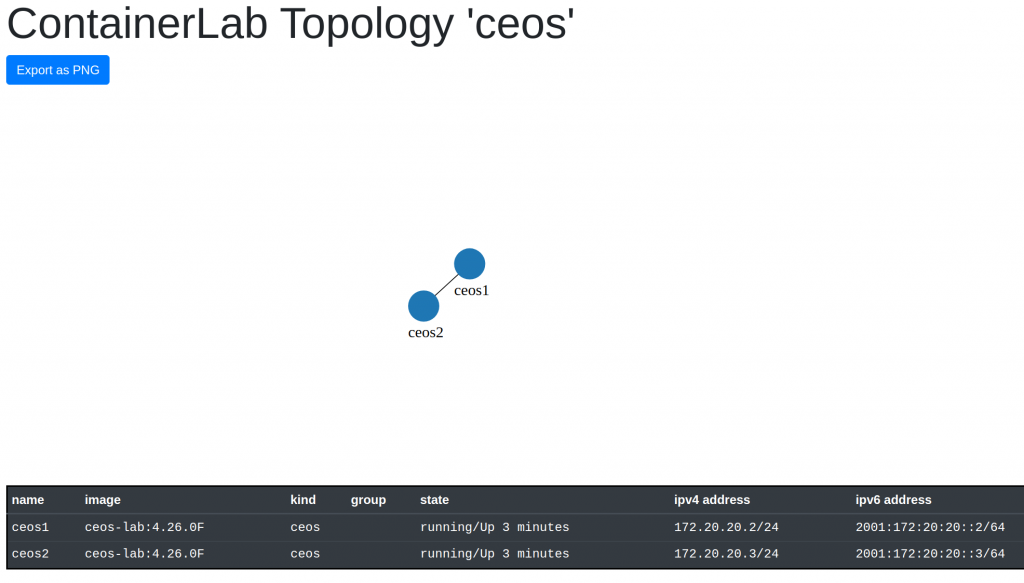
I checked the ceos container logs
$ docker logs clab-ceos-ceos1
....
[ OK ] Started SYSV: Eos system init scrip...uns after POST, before ProcMgr).
Starting Power-On Self Test...
Starting EOS Warmup Service...
[ OK ] Started Power-On Self Test.
[ OK ] Reached target EOS regular mode.
[ OK ] Started EOS Diagnostic Mode.
[ *] A start job is running for EOS Warmup Service (2min 9s / no limit)Reloading.
$
$ docker exec -it clab-ceos-ceos1 Cli
ceos1>
ceos1>enable
ceos1#show version
cEOSLab
Hardware version:
Serial number:
Hardware MAC address: 001c.7389.2099
System MAC address: 001c.7389.2099
Software image version: 4.26.0F-21792469.4260F (engineering build)
Architecture: i686
Internal build version: 4.26.0F-21792469.4260F
Internal build ID: c5b41f65-54cd-44b1-b576-b5c48700ee19
cEOS tools version: 1.1
Kernel version: 5.10.0-8-amd64
Uptime: 0 minutes
Total memory: 8049260 kB
Free memory: 2469328 kB
ceos1#
ceos1#show interfaces description
Interface Status Protocol Description
Et1 up up
Ma0 up up
ceos1#show running-config interfaces ethernet 1
interface Ethernet1
ceos1#
Yes! Finally working!
So now, I dont have excuses to keep learning new things!
BTW, these are the different versions I am using at the moment:
$ uname -a
Linux athens 5.10.0-8-amd64 #1 SMP Debian 5.10.46-4 (2021-08-03) x86_64 GNU/Linux
$ docker -v
Docker version 20.10.5+dfsg1, build 55c4c88
$ containerlab version
_ _ _
_ (_) | | | |
____ ___ ____ | |_ ____ _ ____ ____ ____| | ____| | _
/ ___) _ \| _ \| _)/ _ | | _ \ / _ )/ ___) |/ _ | || \
( (__| |_|| | | | |_( ( | | | | | ( (/ /| | | ( ( | | |_) )
\____)___/|_| |_|\___)_||_|_|_| |_|\____)_| |_|\_||_|____/
version: 0.17.0
commit: eba1b82
date: 2021-08-25T09:31:53Z
source: https://github.com/srl-labs/containerlab
rel. notes: https://containerlab.srlinux.dev/rn/0.17/
My concern is, how this cgroup1 will affect other applications like kubernetes?
BTW, I have the same issue with containerlab as with docker-topo, when I use “Alt+Home(left arrow)” my laptop leave X-Windows and gets to the tty!!!