I have added several links about MRC before, but wanted to read the OpenAI paper for myself.
0 Abstract
tail latency dominates performance of synchrounous pretraining jobs
MRC (Multipath Reliable Connection) = new RDMA-based transport and a bit of UET, packet spraying, adaptive LB based on ECN, out-of-order memory placement, select ack and packet trimming to mitigate incast. RDMA: only support write and write-with-immediate
multi-plane clos -> >100k in 2-tier, high switch radix
static source routing SRv6, bypass failures
1 Intro
solution needs: LB, incast, handle link and fabric failures gracefully
disable dynamic routing!, only static paths with SRv6
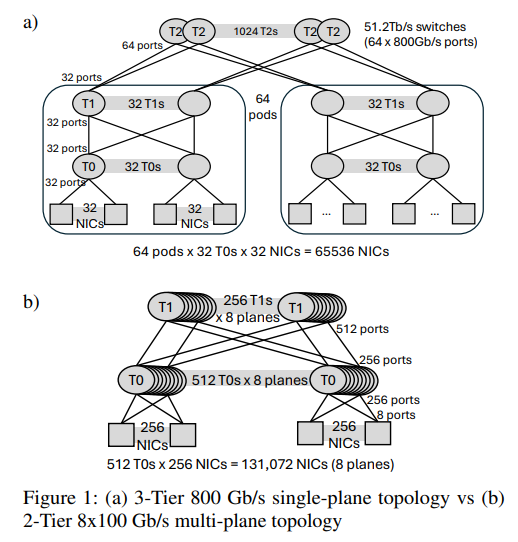
2 Multi-plane topology co-design
T0=TOR, 64x800G. Use 8x100G instead -> 8 planes of T0. TO connects to 256 NIC and 256 T1 (spines) -> total 131072 GPUs in 2-tier
many advantages: latency, more nodes reachable in 1 hope, less cost and power (2-tier only), less impact link failure
problems: survice link and nic port failures. load all network planes and LB all many paths!
2.1 MRC overview
extends RoCEv2 + UET features (multi-path)
- each packet has the RDMA virt address and remote key -> receiving nic can write at arrival, no matter order.
- each packet has an entropy value EV (32 bits) Sender rotates the EV for each packet -> LB (packet spraying)
- PFC disabled (it doesnt work with so many possible paths)
- fast selective retransmissin = Selective-ACK.
- under incast -> packet trimming = packet is not dropped, reaches destination, destination triggers NACk = retranmission Each EV corresponds to a specific path on a specific network plane
For each EV, MRC keeps a few bits of state about path health. ECN used but disabled in the last hop to the receiver -> ECN acts as LB signaling (different
MRC senders do not coordinate when choosing their EV sets)
When packet lost, EV path is stopped then MRC sends background probes to verify, if enough probes succedd -> EV resurrected
2.2 Static SR
difficult to maintain large ECMP sets. MRC avoids failed paths, then dynamic routing re-routes -> changes ECMP -> disturb LB => disable dynamic routing
How to map EVs to network paths? In the MRC nic, at QP startup a set of EVs are chosen, bits in each EV directly embed the path choice available at each hop in the network.
SRv6: use microsegment ID (uSID), where destination ipv6 is 32b prefix followed by a seq of 16b uSIDs each corresponding to a specific switch along the path. Each swith left-shifts the uSID part of address. Switch has a static forwarding table, configured when installed, rarely changed. uN forwarding is done at line rate.
MRC packets are ipv6 in ipv6 encapsulated. outer dst = srv6 path, inner dst = dst nic
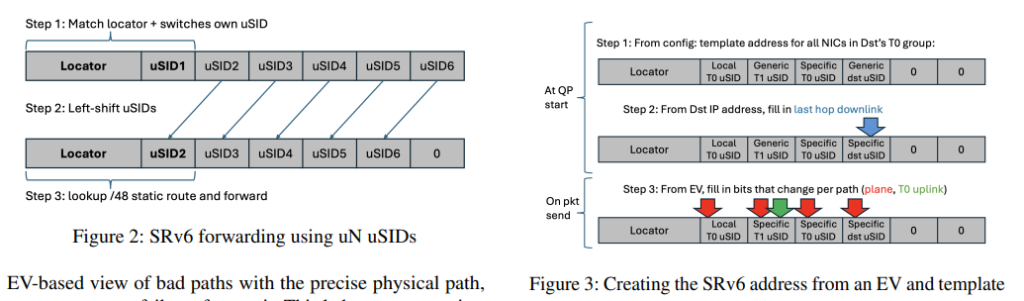
2.3 Mapping EVs to SRv6 address
with srv6, ev is not hashed by switches, but sill needs to be carried in data packets so received can echo it. SRv6 address can’t be echoed because it is erasedd by the shiffiting process during forwarding
algo mapping between EV and its SRv6 address.
*** COMPLEX need to review last part
2.4 Choosing working paths
On QP startup, MRC must select a set of EVs, each mapping to a unique path on a specific plane. EVs are equally split across the planes, then randomly selects a subset of path within each plane. No necessary to use Clustermapper to set denylists for failed T0-T1 links.
*We have to rum-up large training jobs slowly to avoid destabilizing the power grid.
On the reverse path:
Reverse path: many QPs are unidirectiona at any instant. Keep small reserve EV set for control packets, with at least one EV per plane. Each RTT that the QP is acive inbound but generates no outbound traffic, the receiver send an EV prbe packet using a randomly chosen EV. If the probe is acked the reverse EV for that plane is set to the probe’s EV. If data traffic is sent, the reverse EV is updated from data SACKs instead of needing EV probes.
3 Operations
With MRC, Most network failures dont require quick reactions from netops. Link-failures and flapping links between T0-T1 can be ignored!!! MRC spreads traffic across enough paths that when a link used by a QP flaps, only a very small number of packets per QP are lost, and the corresponding EV is removed. The missing pacet is selectvily retransm on a different path. MRC maps paths out when they drop, and only brings back when enough probes succedd over time -> less coordination with netops
Can reboot T1 switch easily. NIC-T0 and T0 switches are more problematic -> After link drop, remapping all the EVs fro the many QPs in use is not instant. MRC uses a port state bitmap in SACK packets to notify remote QP endpoints that the port is down, so they also remap their EVs to avoid the failed plane. This takes a few seconds.
CLustermapper agent running on all cluster nodes together probe every link in the network every ms!! This check NIC-T0 links and T0 switches. Agent send probes source-routed to the T0 and back to the same agent. Each agent also probes a subset of T1 switches, so all T0-T1 links are probed. ICMP probes are handled by CP, so low frequency. With SRv6, the switch treats a probe like another data traffic, by DP -> higher frequency.
4 Inter-plane Loading
Keep all planes evenly loaded <- when MRC maps an EV out of its active set, it replaces it with one from the same plane -> aovid false incast at destination
5 Experiments
flows: T0-local or cross-T1
5.1 Training Results
- Link flaps almost no impact -> low priority at operations level
- NIC-TO links does affect performance, but most events are transient and job recover full speed quickl.
optical transceiver glitch in T0. NIC and Switch dont match the time when the port was down. Still job didnt crash and fully recover. This is rarer that individual link flaps. - T1 switch reboot: QP packet lost only at T1 failure. reboot took 2 minutes and no impact during reboot as all QP wer mapped out of the bad path. throughput largely unaffected.
- NIC transceiver are SPOF, they flap, but rarely. A different optical design might avoid this issue.
5.2 Testbed results (MRC in different NICs: mellanox cx-8, amd pollara, broadcom thor ultra)
5.2.1 p2p communicatio performance – cluster B
cx-8. t0-local and cross-t1 = aprox 770Gbps (96% theorical peak bw)
t0-local 5.09 us and cross-t1 6.54 us (extra switch hop). High latency effect only short-message, negligible for large
5.2.2 MRC response to link down and flap events – Cluster B
less 1 sec interruptions during failure detection . MRC detecs link down event and rebalances EV across remaining planes and updates link0state btmap in SACK packets to notify remote endpoint.
T0-T1 failures have a substantially smaller impact than nic-t0 failures, because MRC sprays packets from each QP across a large number of paths.
5.2.3 MRC behavior with T0/T1 switch failured – cluster B
T0 switch failure -> bw drops 100Gps. MRC failure handling is driven by end2end path availability rather than specific location or type of underlying fabric fault -> swithc-level failures manifest a predictable reduction of usable path diversity, preserve app progress and maintein stable throughpput
T1 switch failure -> no degradation is observer. QP are sprayed across a large number or paths and sufficient alternative EVs remain available to sustain lost of capacity.
5.2.4 Robustness to path-level packet loss
Introducing errors in a EV, caused it to get inactivated and activate another “spare” EV
5.2.5 Load balancing accross EVs
Upon detection of congestion via ECN, MRC triggers traffic distribution to rebalance load across the available EVs. MRC can effectively rebalance traffic across EVs in repspomse to dynamic load changes.
5.2.6 NCCL collective execution at scale
sendrecv benchmark: 92GBps in 42k GPUs
5.2.7 Comparison with RoCE
MRC 1QP sparying across 256 paths achieves better performanc that RoCE with 16 QPs
At 1% loss, RoCE is not usable. The same for MRC because the induced lost affected all planes.
For all message sizes MRC outperforms RoCE but the differnce is greater in the regime that is bw-bound (larger message size)
At smaller message size, the collective is more latency-bound
At bigger message size, the collective is more bandwidth-bound
5.2.8 Collateral Damange (Incast)
Configuring DCQCN properlyis very hard because it is traffic pattern specific to the point some hyperscalers have disabled it.
6 Related Work
Load balancing effectiveness is defined by distribution granularity: per flow, per subflow and per packet.
RocE2 uses per-flow ECMP. Per-packet load balancing (or packet spraying) has been proposed for CLOS networks to reduce amounf of state per (virtual) path -> use ECN or similar
Multipath TCP: must keep state per subflow. Used by Google Falcon to replace RoCE2 in Nic
MRC changes RoCE2 to enable packet-level load balancing, selective retrans and improve reliability in multi-plae networks: its target deployment is best-effort (lossuy) networks that support packet trimming.
MRC is similar to UltraEthernetTransport (to replace RoCE2)
7 Conclusion
MRC is designed to LB a multi-plane network by spraying each QP across all planes and many paths in each plane, performing fine-grain active LB and routing around failures. Disabled dynamic routing, use SRv6 source routing with static routes in the switch