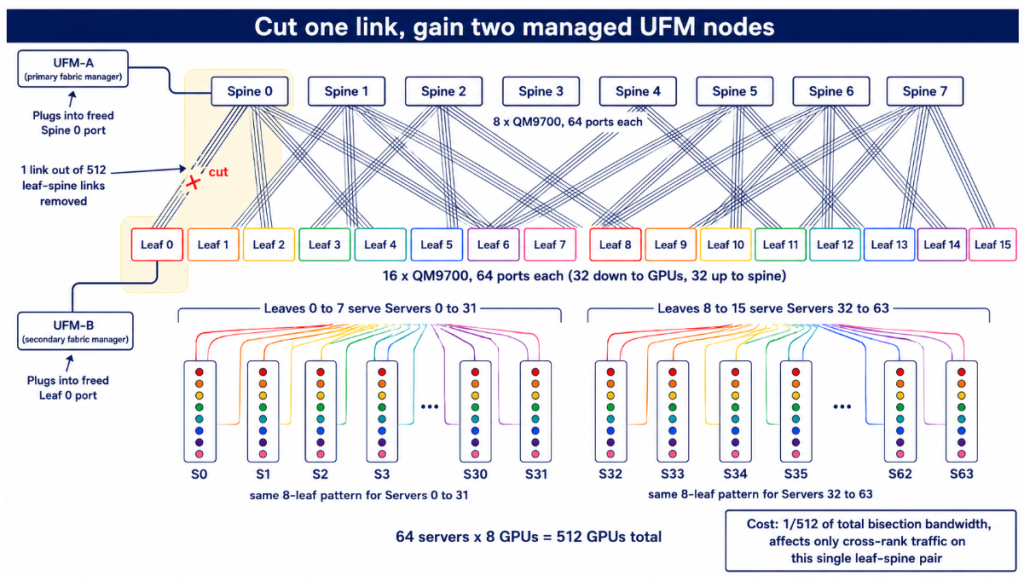
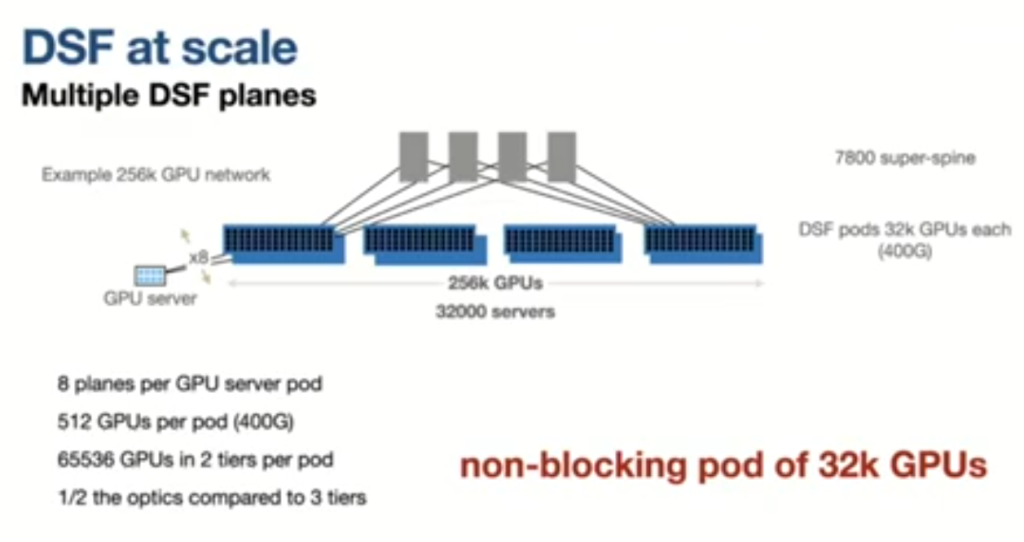
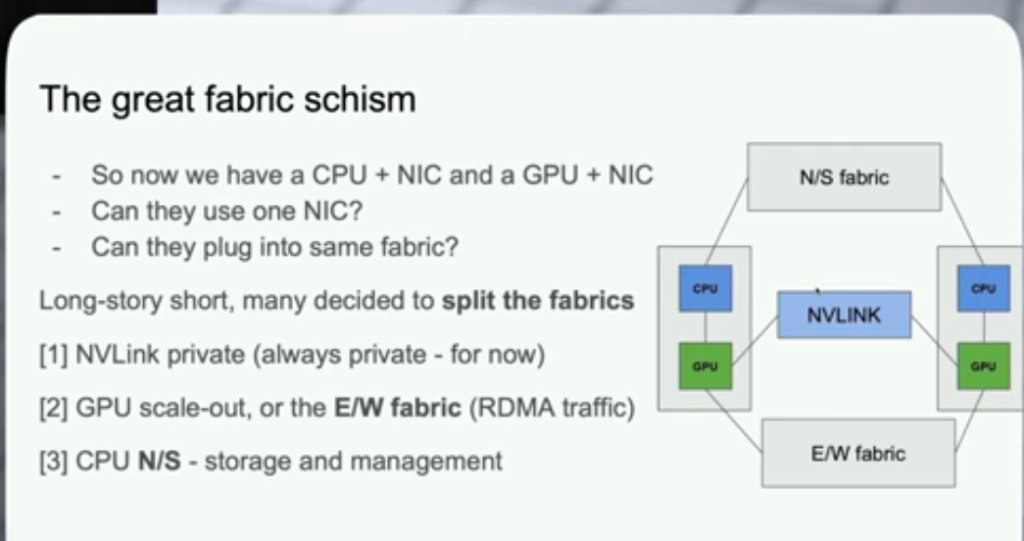
JNCIP-SP
JN0-664
https://www.juniper.net/us/en/training/certification/tracks/service-provider-routing-switching/jncip-sp.html
Advanced Junos Service Provider Routing On-Demand – DONE
Junos Layer 2 VPNs On-Demand
Junos Layer 3 VPNs On-Demand
https://jlabs.juniper.net/vlabs
=========================================
Advanced Junos Service Provider Routing On-Demand
=========================================
OSPF for SP
============
ip protocol 89
DR in ethernet segment: highest priority (def 128), highest RID.
P2P dont need DR: save 40s wait time
packet types:
hello: fomr and maintain adj
DB descriptor: header info for contents of LSDB
LS request: request copy of neighbor LSA
LS update: advertise LSA into network
LS ack: ack, ensure reliable floodingof LSAs
States: Down, Init, 2Way, ExStart, Exchange, loading, full
Areo0, ABR: genreate LSA3 from areaX into area0 and viceversa.
add lo0.0 into ospf
set routing-options router-id LO.IP !!!!! must be unique
if lo0 has several ips
set protocols ospf area 0.0.0.0 interface LO.IP.x (instead of interface name)
LSA types:
max age: 1h, need refresh 3000sec
LSA1 router: sent by each router to describe its links and status
LSA2 network: sent by DR
LSA3 summary: sent by ABR to describe routers from area into another
LSA4 ASBR summary: sent by ABR to describe ASBR
LSA5 external: sent by ASBR to describe routers external to ospf
LSA7 NSSA: sent by ASBR in an NSSA to describe external router
LSA9,10 opaque: TE
LS update packet: 24b OSPF header, 4b (num of LSAs), variable: LSA header (20b), LSA data (var), repeat
LSA header 20b
LS age: 2b –
Options: 1b – E=external, P=NSSA
LS type: 1b –
LS ID: 4b – very vary…
Adv Router: 4b – RID of originator
LS seq nu: 4b – increases with each change
LS checlsum: 4b
Length: 2b
LSA1 Router: > show ospf database router extensive
- = generated the LSA
cost: cost of sending out packer in the interface
bits: V virtual link 0x4
E by ASBR 0x2
B by ABR 0x1
Link ID: far side of the link
MT = multi topology link type link ID Link Data
1 p2p neighbors RID local router interface IP
2 transit DR interface IP local router interface IP
3 stub Network subnet mask
4 virtual neighbors RID local router interface IP
LSA2 Network: > show ospf database network extensive
ID: IP of DR in the segment
Adv Router: DR lo
attachced router: RID of each router attached
LSA3 Summary: > show ospf databse netsummary extensive
ID: IP advertised
Adv Rtr: RID of advertising router
LSA4 ASBR summary: > show ospf database asbrsummary extensive
Area: 0.0.0.0 (sent to this adjacent area)
ID: RID of ASBR
Net mask: no meaning
Adv Rtr: RID of advertising router
LSA5 External: > show ospf database external extensive (not stored as part of any area)
generated ASBR
E bit: type external metric: type1: add metric to ASBR, type2: only add external metric
ID: IP advertised
Adv Rtr: RID of advertising router
LSA7 NSSA: > show ospf database nssa extensive
generated by ASBR in NSSA. Has area scope, not advertised to other areas (as lsa7), the ABR will transate to lsa5. Other routers in the area get the lsa7. If there are several ABR in the NSSA, the hightest RID does the lsa7->5 translation. doesnt require lsa4
lsa7 format is identical to lsa5. only diff, lsa7 uses FWd addr: can be the RID of the originater or the connected IP to reach it
only nssa-capable routers can interpret type7.
LSA9 Graceful restart – link local scope
LSA10 MPLS TE – are scope
OSPF DB protection
SPF: candidate db, tree db and LSDB
you can’t block lsa flooding, just use “set protocols ospf import X” to block external routes in the routing table
before hold-down (5sec default) timer triggers, junos does three runs of SPF.
spf-options delay x = def 200ms between topology change and SFP run
spf calculation order: Intra-A (E1 cost=3), Inter-A, External E1, External E2,
metric = ref bw / link bw
overload: set metric 65535 in all ospf links -> device can be put in maintenance
authentication: none (default), simple, md5
show ospf interface detail
ospfv3 (ipv6)
ospfv2 (ipv4 -> protocols ospf3 realm ipv4-unicast) + GR + Auth + ipv6
interfaces MUST have family inet6 !!!
diff: ipv6 uses link-local addresses to originate packets, auth done at ipv6 layer
options fiel expanded, lsa format changes: new lsa and remaining) IA LSA
LSA Function LS type Description Like ospfv2
1 0x2001 router lsa lsa1 router
2 0x2002 net lsa lsa2 network
3 0x2003 InterA-prefix lsa lsa3 summary
4 0x2004 InterA-router lsa lsa4 asbr summary
5 0x4005 AS-Externa lsa lsa5 external
6 0x2006 Group Memb lsa lsa6 multicast
7 0x2007 type-7 lsa lsa7 nssa
8 0x2008 link lsa none
9 0x2009 IntraA-prefix lsa lsa1 + lsa2
U bit: unknow: 0 -> link local scope / 1 -> flood
S2 S1 – flooding scope
0 0 link-local
0 1 area
1 0 AS
1 1 reserved
Advance OSPF for SP
shrinking LSDB – route summarization, areas
Stub: lsa1,2,3. no lsa4,5
totally stub: lsa1,2 and just one lsa3 (default route) no lsa4,5
NSSA: lsa1,2, just lsa7 as default. ????????/
totally nssa: lsa1,2, ??????
-Stub: not flooding lsa4,5 by ABR. ABR inject default route (in junos needs to be done manually)
no virtual-links
set protocols ospf area 1 stub [default-metric 10 (this only in ABR to advertise default route)] All other routers just need stub
interface xx
-totally stub= stub + “no-summaries”: lsa1,2 and just one lsa3 (default route – manual config)
no virtual links
only in ABR of Totally Stub your configure this. Other routers just need “stub”
set protocols ospf area 1 stub no-summaries [default-metric 10]
interface xx
** E-bit must match for OSPF adj to form
-NSSA: asbr injecs LSA7 in NSSA. ABR transforms lsa7 into lsa5 in are0. nssa receives a default route (no-summaries) (as lsa7!) from ABR.
no virtual-links
set protocols ospf area 1 nssa (in all routers) [default-lsa default-metric 10 (only in ABR! as lsa7)]
[no-summaries – with above -> uses lsa3 as default – only ABR]
interface xx
no-nssa-abr: if ABR connected to several NSSA, and want to disable export lsa7 into nssa
** if several ABR in same are, the highest RID, floods LSA from areaX to area0
-Totally NSSA: stub + no-summaries. ABR doesnt inject lsa3 from area0. ASBR injects lsa7 into NSSA. ABR converts lsa7->5 into area0
no virtual-links
-route summarization: done in ABR,summarize lsa1,2 as a lsa3 into area0. Because ABR forwars lsa1,2 from areaX to area0.
set protocols ospf area 1 area-range IP/20 [strict (no type3 is generated for this summary in area0)]
interface xxx.0
- for NSSA, the ABR summarize all lsa7 as one lsa5 into area0
set protocols ospf area 1 nssa area-range IP/20 [strict]
interface xxx.0
Multi-Area Adj
in ABR. each multi-area adj is a lsa1 p2p. No lsa3 advertised over multi-area adj. one adj is primary (only one!), and the other secondary
set protocols ospf area 0 interface ge-0/0/0.0
area 10 interface ge-0/0/0.0 secondary
show ospf interface
interf State Area
ge-0/0/0.0 BDR 0
ge-0/0/0.0 pTp 10
show ospf neighbor -> shows 2 adj in ge-0/0/0.0 !!
Virtual-Link
control-plane only. between ABR
set protocols ospf area 0 virtual-link neighbor-id RID-R1 transit-area 0.0.0.10
interface ge-0/0/0.0 interface-type p2p
show ospf interface/neighbor -> vl-xxxx
External reachability ?????
deafult export policy: reject
set policy-options policy-statement redis-static term static from protocol static then external type 1 accept
set protocols ospf export redis-static
prefix-limits: 32b — when reached, routers gets “overload” change metric to all prefixes
set protocols ospf prefix-export-limit x
ospf mutual redistribution !!!
ospf import policu !!!!!
LSDB: show ospf database
Tree DB: show ospf route
inet.0: show route protocol ospf
Troubleshooting OSPF
adj issues
down,
init: neighbo discover
2way: idem
exstart exchan loading: lsdb sync
full:
init to 2way issus: interface type match, network mask, hello/dead interval, area type, area number, auth, RID different, fw issue
2way stuck: priority both 0?, same IP?, MTU?
show ospf interface X detail
show ospf statistics | find errors
set protocols ospf traceoptos flag error detail, hello detail
lsdb issues
duplicate RID -> continuos SPF runs
broken area0: use virtual-links
routing issues
suboptimal
instability
show route protocol ospf: computed routes and attributes
show ospf route
show ospf database
IS-IS
by ISO (OSPF by IETF – TCP/IP)
Connectionless Network Service CLNS / CNLO. Single AS
PDUs = ISIS packets
ES = End System = host
IS = routers
L1: route within an area or towards L2 system
L2: route between areas and towards other ASs
L1/L2 (ABR): sets the attached bit in the L1 PDUs = it can reach L2
L1 routers create default route for InterArea prefixes, witch points to the closest L1/L2 router
Net = 49.xxxx.yyyy.yyyy.yyyy.zz
area sys id selector
(lo.ip) 00
L2 routers connect areass. L1 router dosnt connect to another area. L2 routers are BB
LS PDU format
id lenght: 6b
pdu type: 18=l1 20=l2
max area address = 3b
2xversion!
Variable: PDU headers and TLV
pdu length, remaining lifetime, lsp id (unique!: system id + circuit id + lsp number), seq nu, checksum, IS type bits, TLVs (variable)
ciruit id – 0x01 for lo and p2p
LS flooding: files remaining lifetime: 3b: default: 20minutes
ATT bit: attachment bit – it IS connected to another area
OL bit: overload bit – if LSDB is overloaded (in maintenance mode)
IS type: l1 = -0x1 / l1l2 = 0x3
ISIS Messages:
hello: neighbor discovery, build, maintain adj: LAN hello (L1, type15 – l2 – type16), p2p hello. Hello reg 3s default
circuit type (l1,l2,l1l2), source ID (sysid), hold time, pdu length, priority (for DIS election), LAN ID (sysid or dis + 1b)
LS PDU: sent as result of network change, during adj formation, response to seq nu pdu.
identify adj, describe state adj, describe reachable address
PSNP: Partial Sep Num PDU. Maintain LSDB sync. ack in p2p, request copy lsp on broadcast. contains specific header for lsp acked or req-ed
CSNP: Complete Seq Num PDU. periodically in p2p. only by dis in broadcast. header info for all lsp
TLV: type, length, value
tlv1: area address (of l0). Sent via l1 and l2 i
tlv2: IS neighbor metrics. delay/expense/error metric: S bit =1 , I/E and metric bits = 0.
tlv10: authentication
tlv22: extended IS reach (TE). It has SubTLV
tlv128: ipv4 prefix, mask, metrics from the local router
tlv129: protocols supported (ipv4,6)
tlv130: ip external info (coming from policies)
tlv132: ip interface address (
tlv134: TE IP RID
tlc135: ext ip reachability ( for TE). for larger metric values
tlv137: dynamic hostname mapping
tlv232: ipv6 support
tlv236: ipv6 support
ADJ
l1 router never adj with l2 router
l1 adj, same area ID
l2 adj, diff area ID
DIS election: 0 (never)-127 priority (higher better). for l1 and l2 (can be the same). In hello pdu
no backup DIS. there is preemption. non-DIS created adl with all others.
pseudo-node: DIS acts as representative and advertises it to all attached router (broadcast network). Pseudo-node hast cost 0
set interfacces ge-0/0/1 unit 0 family inet address IP
iso
lo unit 0 family inet address IP1
iso address 49.area_ip.00
- by default all interface are l1/l2
- default metric is 10 (for lo is 0)
set protocols isis interface ge-0/0/1.0 level 1 disable [metric x]
lo.0 level 2 disable
reference-bandiwth 1g
show isis interface [detail]
show isis adjacency [detail] (SNPA = mac of next hop)
show isis spf log [detail]
show isis statistics
show isis route
show isis database extensive
ISIS flooding
LS PDU flooding scocpes: L1 stay in its area. L1L2 routes inject L2 in different areas
show isis database -> there is a lsdb for l1 and another for l2
you can see the DIS in the output -> router_ID.02-00
SPF algo: LSDB -> candidate DB -> tree DB -> RIB
set protocols isis spf-delay (def 200ms) delay between back-to-back SPFs
Partial Route Calculation = PRC – enabled by default and can’t be disabled
isis floods LSPDUs to all neighbors by default => no great for mesh topologies -> create mesh-group to avoid the flooding
isis wide metrics
tlv2,128,130 uses 6b -> max metric=63
tlv22,135 -> large metric: 16 777 215 (32b)
set protocols isis level x wide-metrics-only
auth: only in hello. l1, l2 or interface. none, simple, md5.
overload bit: for maintenance. can be scheduled time
csnp interval: DIS sends CSNPs on a LAN every 10s.
user-defined import policies are not allowed
export: ok (beware of routing loops when multiple redistribution points exist
l1l2 isis multilevel area = ospf nssa with no summaries
*l1l2 border is a natural route boundary
- l2 routes are not advertised into l1 by default
- external l1 routes are not advertised to l2 by default -> route leaking to modify this. Using “wide-metrics-only” eliminates internal/external distinction
set policy-options policy-statement external-l1-summary term X from protocol aggregate route-filter IP/22 exact
to level 2
then accept
term y from route-filter IP/22 longer
to level 2
then reject l1l2 attached routers set the attached-bit in their l1 LSPDU
- l1 routers install a locally generated 0/0 def route to the closest l2 attached router (disable with ignore-attached-bit)
default interface enabled for l1/l2.
loopback is always passiv, no need to disable anything
- l1 links: between the same area
l2 links: between differnt areas
attached bit = generate default
route leaking and summarization: 1) create agg route, 2) create policy 3) export policy into isis
Troubleshooting
adj
family iso, level mismatch, ip subnet mismatch (overlap is ok), MTU 1492 and match (init state stuck!!), auth, passive, p2p vs broadcast, same system-id cause issues! -> frequent spf runs!
down
new: sent hello
two-way: received hello
init: LSDB sync
up
routing
narrow vs wide metric, lo0 advertised, route summerization (int vs ext), route leaking,
show isis interface
statistics
overview
adjacency
hostname
spf log
database [extensive] | find TLVs
level x hostname extensive | match PREFIX/MASK
set protocols isis traceoptions file isis flap error detail flag hello send receive detail
BGP
path vector protocol
ibgp: full-mesh, no changes anything (nh)
ebgp: changes aspath and nh
4096b max
19b min
idle: all refused
connect: wait for tcp to complete
active: initiates tcp
opensent: tcp completed, waits for open message
openconfirm: waits for a keepalive (moves to establs) or notif message (moves to idle)
established: exchange update, notification, keepalive
bgp update: nlri, origin, aspath, NH, additional
hold = 3xkeep/hello (def.30) -> 90s
notification: when error is deteccted
refresh: inform peer to resend all routes
hidden routes: reject by import policy, nh issues (fix: next-hop-self or igp passive in external link), as-path issus
show route hidden extensive
path selection
nh exist, +LP, -ASpath, -Origin, -MED, ebgp>ibgp, -IGP metric, -cluster , -rid, -peer_ip
LB
multipath -> ignores rid and peer-id
ebgp: multihop if not directly connected !! (ttl def = 64!)
set policy-option policy-statement LB then load-balance per-packet
set routing-option forwarding-table export LB
hash-key family inet XXX (default only l3)
show route forwarding-table matching IP/MASK
set routing-options router-id IP-lo
autonomous-system ASN
GTMS: BGP Generalized TTL Security Mechanism: used in BGP single hop. drops any packet lower than max ttl
needs to create firewall policy and apply input interface!!
GR: graceful restart. negotiated between peers
End-of-RIB markers sent for each NLRI. Notifies the neighbor that all current routing info was sent
Local router defers path selection alg until the marker is received
set routing-options graceful-restart
autonomous-system ASN loops X
allow IP_RANGE -> not needed to set each neighbor manually
as-override
local-as [x private]
remove-private
Policy
RIB-in: before applying policies. rejected are showing with “hidden”.
show route receive-protocol bgp PEER_IP
RIB-local (inet.0): after routing best path decision. only single best bgp path. only active are advertised. you can advertise more than best with ‘add-path’ (good in RR!!!). ‘advertise-inactive’ to advertise the best bgp although is not best in rib (ie: ospf/isis to same destination is better)
show route protocol bgp source-gateway PEER-IP
RIB-out: after export policy
show route advertise-protocol bgp PEER_IP
Attributes
WK-mandatory: in every bgp update, undertstood by all – ASpath, Origin, NH
WK-discre: not in every bgp update, undertstood by all – LP
Opt-trans: transmitted even if not understood (communities)
Opt-notrans: no transmite even if not understood (MED)
LP: def 100. only iBGP. set exit AS. Cold potato: keep traffic in your network as long as possible. Hot potato: handover traffic to carriers asap
MED: set entry AS, among same AS peer
ASPATH: junos, before advertising, if neighbor AS is already in ASPATH, it drops advertisiment
2B: priv 64512-65534
4B: xx.yy (old: 0.y) priv: 1.y – 65535.65535
[] = standard ASPATH
{} = AS set – group os AS where order is not important
() = confederantion
Aggregation: ??
CE) show route (without any manipulation)
AS path 65001 (65002 65003) I Aggregator: 65001 (as of the aggregator) nh_ip from pe
PE) set routing-optoins aggregate route 192.168.0.0/23 as-path atomic-aggreate => removes the as from the contributing paths in the aggreate (ie: 192.168.0.0/24 from other ASn) -> the output says “atomic”
PE) set routing-options aggregate route 192.168.0.0/23 as-path aggregator 65002 10.0.1.1 => cha
regex in aspath
term: asn or asn path ( . == single asn !!!)
operator: | = or ie: 1024|1025
– = range ie: 1024-2685
. = any asn
() = empty as path
^ = start
$ = end
? = 0 or 1
- = 1 or +
- = 0 or +
{m,n} at least m repetions, at most n repetiions
set policy-options as-path NAME regex
as-path-group -> define list of regex evaluated as logical OR
show route receive-protocol bgp IP aspath-regex “.* ASN”
Origin: WK-mandatory
installed by the originating. I (Internal – learned by IGP – 0), E (External – from EGP – 1 ), ? (Incomplete=2) I > E > ?
anything in inet.0 is Internal
MED: optional-nontran => Med is not passed between ASs. Less med is better
affects inbound traffic from other AS (several links with same neighbor AS !!!!)
routes redistrib into bgp, will have MED = metric of original route
set protocols bgp path-selecction “always-compare-med” -> compare MED for the same prefix coming from different ASs
set protocols bgp group X neighbor IP metric-out Y ( yY = MED value)
Communities: opt-trans
wellknow communities have global meaning.
no-export: routes must be distributed within the confederation or AS, but not further
no-advertise: routers must not be advertised to other bgp peers
no-export-subconfed: routes must not be advertised to eBGP confined to sub-AS
informational, action, LP, other: communities
4b: 2b=asn + 2b=value (AS:number)
extendended:
4b asn: as.as:number or asL:number
“:” = all communities regex
nontransit AS only advertise local-routes
set policy-options community COMM_NAME members COMMUNITY/regex (multiple communities is with AND !!)
set policy-options policy-statement TEST term X then community add/delete/set COMM_NAME
regex in community are character based !!! (different form AS path that match a whole ASN)
show route community *:20 [terse|detail]
show route community-name COMM_NAME [detail]
[a-z] = range
(a,b,z) = list values
“((56)|(78)):” – AS is 56 or 78 – ie: 56:100, 78:65000 “56:(2.)” – AS is 56 and value starts with 2 – ie: 56:234, 56:2, 56:222
“:(.[579])” – Any AS and values ends with either 5,7, or 9 – ie: 213:5, 78:2347, 34:65009
“((56)|(78)):(2.*[2-8])” – AS is 56 or 78, value starts with 2 and ends with any value between 2-8 – 56:22, 56:21197, 78:2678
Route-Reflector rfc4456
ibgp full-mesh <- not added as-path for loop preventaion -> escale issue n2 problem
route-reflector: can readvertise ibgp prefixes -> loop prevention: cluster-list (similar to as-path) and originator-id (1st router to inject route in RR network)
set protocols bgp group int-peers type interal local-addres IP cluster IP neighbor X neighbor Y
If you have 2xRR: shall you use the same cluster-id for both or different?
- same cluster-id -> reduces number routes stored
- diff cluster-id -> duplicated info -> more spacce but more resilience
clients do only ibgp to RR
full-mesh between RR !!! (normal ibgp, just need cluster-id)
“no-client-reflect” in RR: stop unnecesary adverts
*be sure RR only change NH for ebgp peers
off-path: better since virtual-RR
Optimal RR (ORR)
Juniper supports only ORR optimal BGP path selection based on client perspective use OSPF/ISIS – virtual only
suboptimal RR solutions
- hierarchical RR: RR close to clients but limits where to deploy
- “add-path”: reduces benefit of RR as additional route info is introduced -> more BGP update churns
- VRF + unique RDs per peering router
- use tunnels
- use ORR: RR anywhere, solves hot potato, no changes in BGP RR clients, can worh with add-path.
set protocols bgp group NAME optimal-route-reflectoin ipg-primary IPv4 (from one of the clients so its IGP metric is used for selecting best path)
rfc3345 oscillation
solutions: 1 always compare med > set protocols bgp path-selection always-compare-med
2 add-apth > set protocols bgp family inet unicast add-path receive; send prefix-policy NAME path-count 6s
Confederation
considered legacy!
limitations: no possilbe to migrate to/from a confederation setup withou a complete bgp shutdown
no scalable in regard to services and AF
each sub-as still need full-mesh ibgp, private asn
between sub-as, ebgp.
confederation as-path: it appears as a single iBGP as-path
set routing-options autonomous-system 65000
confederation 201 members [ 65000 … 65004 ]
needs multihop!
BGP FLOWSPEC
amplification attacks: memcached (10k-50k), ntp monlist (556), CHARGEN (358), DNS (28-54), SSDP (30)
uRPF: against IP spoofing.
strict: interface packet is received must be the best and active path to the source prefix.
loose: source address must match a prefix in the routing table (accomodates asym routing)
RTBH
Destination-based RTBH: customer communicates to ISP. ISP, via iBGP import policy on edge PE, drops traffic heading to the destination IP
bw is restored when attack is targeted to a single IP or prefix
negative: knocks victim offline, force emergency IP change.
Source-based RTBH: attacked source IP is advertised to ISP via BGP (blackhole community), ISP uses it with uRPF to dropp traffic at edge.
negative: src addr often not known or too numerous, or behind CGNAT or they are public services (DNS,NTP,LDAP, etc)
BGP FLOWSPEC: rc5575, afi 1 safi 133 = ipv4, afi 1 safi 134 = vpnv4
afi 2 safi 134 = ipv6, afi 2 safi 134 = vpnv6
1- dst prefix 7 icmp-type
2- src prefix 8 icmp-code
3 ip protocol 9 tcp-flags
4 src or dst port 10 packet-lenght
5 dst port 11 dscp
6 src port 12 fragment encoding
bgp-community 0x8006 traffic-rate
0x8007 traffic-action
0x8008 redirect
0x8009 traffic-marking
order processing
1 compare left-most components of each NLRI
2 if types differ, lowest type by numeric value is used, if same, then values within that component are compared
3 for ip prefix values (type 1,2,3) the lowest IP is chosen, and if the IP addresses are the same, the most specific prefix is used
4 for all other types, the binary string of content is compared to determine the order
validation
1 originator of flow spec matches the originator of best-match unicast route for destination prefix embedded in flow spec
2 there are no more-specific unicast routes that have benn received from a different neighbor aS than the best-match unicast router from 1)
- this validation can be disabled: customer calls instead of having BGP
config:
family inet unicast + flow peering with ISP
- advertise prefix
- config flow spec under routing-options
policy
CUSTOMER
set protocols bgp group SP type external export TO-SP peer-as ASN neigbor IP family inet unicast flow
set routing-options flow route DNS match protocol udp port 53 packet-length 100-65535 destination DESt/32 then discard
term-order standard
set policy-options policy-statement TO-SP term flow-to-SP from rib inetflow.0 then accept
term CUSTOMER-ROUTES from route-filter DEST/24 exact then accept
term REJECT then reject
SP
set protocol bgp group Customer import Customer-in peer-as X neighbor IPY family inet unicast flow prefix-limit maximum 2
group IBGP local-adress Z family inet unicast flow neigbor A1 neighbor A2....
set policy-options policy-statement Customer-in term 1 from rib inetflow.0 route-filter DEST/24 prefix-lenght-range /32-/32
then community add CUST-FS-COMM accept
term 2 from route-filter DESt/24 exact then accept
term 3 then reject
community CUST-FS-COMM members 100:9999
*For other PEs:
set routing-options
rib inetflow.0 maximum-prefixes 10000 threshold 90
flow term-order standar
Case-2: customer doesnt do BGP, calls NOC. SP needs RR:
RR:
set protocols bgp group RR-CLIENT-FLOWSPEC import NO-ROUTES-IN export FLOW-ROUTES-OUT type internal local-address X family inet flow cluster X neighbor a,b,c
set routing-options flow route DNS match protocol UDP port 53 packet-lenght 100-65535 destination DEST/32 then discard
term-order standard
set policy-options policy-statement FLOW-ROUTES-OUT term 1 from rib inetflow.0 then community add INTERNAL-FS accept
term 2 then accept
policy-statement NO-ROUTES-IN term 1 then reject
community INTERAL-FS members 100:1000
For other PEs:
set protocols bgp group RR-CLIENT-FLOWSPEC import FLOWSPEC-RR-IN type internal local-address X family inet flow no-validate FLOWSPEC-RR-IN
set policy-options policy-statement FLOW-ROUTES-RR-IN term 1 from rib inetflow.0 route-filter 0.0.0/0 prefix-length-range /32-/32 then accept
term 2 then reject
set routing-options rib inetflow.0 maximum-prefixes 1000
flow term-order standard
show bgp summary
show route table inetflow.0 extensive [hidden] -> Fictitious indicates there is no BGP next-hop in the route
show route flow validation detail -> check “match validation”
show firewall -> flowspec_default_inet applied to all interfaces
LAB
BGP TROUBLESHOOTING SP
peering session establishment troubleshooting:
tcp states for bgp: idle (init state, no route to send tcp syn), connect (wait for tcp to complete, tcp sent), active (tcp timout occurred)
ibgp: igp dooesnt have loopbackc, missing local src ip. Test: ping loopback_dst source loopback_src, mtu
ebgp: multihop, mtu
routing issues:bgp import policty accepts all routes by default. NH not reachable. aggregating missing contributing
show bgp summary
show bgp group
show bgp neighbor IP
show system connections inet extensive | find P
set protocols bgp traceoptions file X size 10m files 2 flag packets details flap general flag open
show log X
monitor start X
show route advertising-protocol bgp IP [extensive: bgo communities, asparth-prepend]-> routes after export policies
received -> routes befor import policies
show route protocol bgp source-gateway BGP-NEIGHBOR-IP -> routes after import policy
show route protocol bgp active-path
[terse < brig < no_option < detail < extensive ]]
Policy Troubleshooting
import policy: before RIB
export policy: after RIB and before reaching neighbor
fw export policy: from RIB to FIB (ie: LB)
RTBH: Remote triggered black hole: can discard legitimate traffic -> better: FlowSpec
common match conditions: protocol, route-filter and PL, NH and interfac
import/export policies: order is important, left to right
defaults:
Import Export
BGP accept accept
ISIS accept reject (but ISIS peer accept)
OSPF accept LSA reject (but OSPF peer accept)
RIP accept reject
expresions: be careful!!!, can be unpredictable if policies only modify attribtures and don’t accept/reject the route!!!
ie: export ( policy-one && !policy-two)
regex only for ASPATH (minium value is a ASN) and communities (minimun value is a character)
community set (replace all values with a new onne) <> community add (keep current values and add new one)
no-export: not leave AS (so to iBGP is fine)
no-advertise: no iBGP, no eBGP
no-export-subconfed: not leave confederation sub-as.
show route forwarding table -> “ulst” list of unicast NH for LB
show policy forwarding-policy (no very useful)
test policy (no very useful)
traceoptions flap policy: powerful but use with care! add “trace” in any “then” term. remove when done!!!!
show ospf database external advertising-router ROUTER | match PREFIX
show isis database external ROUTER | match PREFIX
set policy-options as-path-group X as-path P1 65051*
as-path P2 65052*
as-path Y "65500 .*"
policy-statement send-customers term T1 from as-path-group X then accept
policy-statement no-transit term T2 from as-path Y then reject
LAB
BGP Route Damping
rfc 2439 – bgp route flap damping
figure of merit = points decay = 0 when learned. Increased when flaps (1000) or attributes changes
points decay = reduce value at certain rate = ‘half-life’ (reduced penalty points by half: def: 15 min)
points above ‘suppress’ (def: 3000) threshold -> route is damped
points drop below ‘reuse’s (def: 750) threshold -> route is used
‘max-suppress’: longest time to suppress a route. def: 60 min
set policy-options damping NAME-DAMP half-life minutes max-suppress minutes reuse number suppress number
dont-damp disable (not calculate a merit figure for routes = no damping)
set policy-options policy-statement C1 then damping dont-damp
C2 term t1 from route-filter NET/x or longer then damping dont-damp accept
t2 then damping NAME-DAMP
set protocols bgp damping
import POLCICY-IN
show route damping history extensive
decayed
suppressed
clear bgp damping –> figure of merit=0 for all routes
=========================================
Junos Layer 2 VPNs On-Demand
=========================================
REFRESHER L2VPN
ipsec vpn (full-mesh, partial, hub-spoke), sd-wan, mpls-vpn. Trade-offs
PE: connect to CEs, bgp to other PEs, ingress/egress LSP
P: LSP transit, fw only based on labels, PHP, bgp-free
lsp: ldp (igp), rsvp (manual), sr, bgp-lu
transport label (outer – advertisedd by ldp/rsvp, changes hop-by-hop), vpn label (inner – advertised by bgp PEs, doesnt chnage)
mpls.0 table – just labels (transport and vpn)
l2vpn = virtual switch. label stack: labels are placed between SP ethernet fram (top) and customer ethernet frame (sandwiched)
L2VPN flavours
l2vpns: virtual-wires or virtual-switch
pseudowire: CEs think they are directly connected
logical pe-ce = attachment circuit !!!
method-1: one single logical unit accepts all traffic
method-2: multiple logical units for multiple pseudowires = vlan-tag identifies pseudowire (hub-spoke)
no need to MAC learning
5 types:
l2vpn: bgp autodiscovers PEs and signals vpn (address family l2vpn, longer config)
l2circuit: ldp signals the vpn, neighbord manually defined (address family l2circuit, shorter config)
fec-129: bgp autodiscoverd PEs, ldp signals vpn. bpg overloadd…
circuit-cross-connect: 2xrsvp (one in each direction), 1 label, doesnt scale (family ccc)
bgp-signaled evpn-vpws: evpn without mac-learning (newer)
L2VPN <> l2vpn
L2VPN: bpg-signaled pseudowires in Junos (kompella)
l2vpn: all types of mpls vpn at l2.
L2Circuit = Layer2 Circuit = ldp-signaled pseudowires (martini)
vpws: virtual-private wire service
vpls: virtual private lan service, overlay model
pe: learns mac address, unknow mac flooding, irb can be places inside vpls
trade-offs: multihoming can do active/active, vrrp, mac learning
evpn: mac learning via bgp, multihming ok (no stp!), no need vrrp
“encapsulation flexible-ethernet-services” you can use all types of vpn in one physical interface
be aware of l2 stretching! -> stretch failure domain
L2VPN or BGP-signaled pseudowires (kompella) rfc6624
AC = Attachment Circuit, can have several pseudowires. 1 pseudo-wire = 1 p2p vpn
PE interface to CE: configures as
- Ethernet encap: one AC. all incoming frames to to one remote site. vlan tags are consired part of the payload
- Ethernet-vlan encap -> multiple AC. vlan is not part of payload -> each AC is bound to one remote interface
RT: bgp ext community. identify vpn membership target:ASN:number
Site-ID: unique number for each end of the L2VPN. Used to calculate vpn label
Label-Block: can advertise a range of vpn labels for multiple AC at the same time (efficiency): label base, label size, label offset
RD: just make advertisements unique
typo 0: 2byASN:4byNumber:IPPrefix
type 1: 4byLo0:2byNumber:IPPrefix -> great for LB and fast failover. Because eachc PE advertise the prefx with its LO in thhe RD so the RR will see always different vpnv4 prefixes.
type 2: 4byASN:2byNumber:IPPrefix
L2VPN prefix is just two fiels: RD + local Site-ID ie: 192.168.1.2:222:2
————— –
RD Site-ID
bgp L2VPN update: RT, Encap, RD, Site-ID, LabelBase/Size/Offset
bgp.l2vpn.0 -> instance_name.l2vpn.0
PE pseudowires dont do mac-learning (BGP does that)
Layer2 Info: BGP extended community: Encap Type (5=raw(all), 4=ether-vlan), layer-mtu.
NLRI: AFI=25 =Layer2 VPN, SAFI=65=vpls!!! (although is a bgp-signaled L2VPN!)
RD, CE-ID, Label Block offset, size, base
L2VPN Config
pre-requisites
IGP in backbone, 2xLSP between PEs, “family l2vpn signaling” between PEs/RR
—- ethernet-mode
PE:CE-facing interface
set interface ge-0/0/0 encapsulation ethernet-ccc => AC is in”Ethernet Mode” pseduo-wire (all tags are part of payload)
unit 0
PE config
set routing-instances L2VPN-NAME instance type l2vpn interface ge-0/0/9.0 route-distinguier LoIP:xxx vrf-target target:ASN:xxx
protocols l2vpn encapsulation-type ethernet
site NAME site-identifier 1 interface ge-0/0/9.0
*remote site-id is implicit: if local is 1, remote is 2 and viceversa
—–ethernet-vlan mode
PE:CE-facing interface
set interface ge-0/0/0 encapsulation extended-vlan-ccc
vlan-tagging
unit 100 vlan-id 100 family ccc
unit 200 vlan-id 200 family ccc
or
set interface ge-0/0/0 encapsulation flexible-ethernet-services => when you have different services apart from L2VPN in the interface
flexible-vlan-tagging
unit 100 vlan-id 100 encapsulation vlan-ccc => pseudo-wire
unit 200 vlan-id 200 family inet address IP/24 => ipv4
PE config
set routing-instances L2VPN-NAME instance type l2vpn interface ge-0/0/9.100 route-distinguier LoIP:xxx vrf-target target:ASN:xxx
protocols l2vpn encapsulation-type ethernet-vlan
site NAME site-identifier 1 interface ge-0/0/9.100
*remote site-id is implicit: if local is 1, remote is 2 and viceversa
—– verification
show route table bgp.l2vpn.0 detail -> prefix => RD : remote site_id : offset / 96 (96 is the lenght of the NLRI and can be ignored)
INSTANCE_NAME.l2vpn.0
show l2vpn connections instances INSTANCE_NAME [extensive show logs]
show route table mpls.0 lable LABEL_from_above_command
ccc ge-0/0/9.0 detail -> show how PE process incoming traffic in this AC
L2 Header ether-type: 0x0800 ipv4, 0x086dd ipv6,
802.1q header: tag protocol id (TPID): 0x8100 = single-vlan frame / 0x9100 = double-tag frame (QinQ)
* ethernet-ccc (ethernet-mode) any TPID is accpeted
* extendended-vlan-ccc (ethernet-vlan) only allows 0x8100 / 0x9100
L2VPN Troubleshooting
no LSP to remote PE
show l2vpn connections instance XXX -> no connections found
no l2vpn signaling in iBGP
show l2vpn connections instance XXX -> no connections found
customer interface encapsulaton dont match
show l2vpn connections instance XXX -> encapsulation mismatch (EM)
customer interface vlan tags dont match
show l2vpn connections instance XXX -> doesnt show any issue. vlan tag are not exchanged!
check interface config
incorrect customer interface in instance
show l2vpn connections instance XXX -> LD: local site signaled is down / or RD: remote site is down
choosing incorrect site-id
show l2vpn connections instance XXX -> OR: out of range (range = range of labels in the label base, site-id is used to calculate the vpn label)
L2VPN Site-ID, Label Base, Overprovisioning
Site-IDs: hub-spoke
Label Block: one routing-instance, one bgp adv with one block labels -> remote site can calculate label from the block based on site-id
show l2vpn connections instance XXX extensive -> Label-base, connection-site = remote-site-id, offset,
vpn-label = label-base + (remote-site-id – offset) -> incoming label expected (what remote PE needs to use)
*labels are only significant to the originating router
overprovisioning: add more AC that needed for future growth
PE-HUB
set interface ge-0/0/9 vlan-tagging
encapsulation extended-vlan-ccc
unit 200 vlan-id 200 family ccc
unit 500 vlan-id 500 family ccc
**explicit remote-site-id
set routing-instances XXX instance-type l2vpn
interface ge-0/0/9.200
.500
routing-distinguisher LoIP:111
vrf-target target:ASN:111
protocols l2vpn encapsulation-type ethernet-vlan
site ONE
site-identifier 1
interface ge-0/0/9.200 remote-site-id 4
site EIGHT
site-identifier 8
interface ge-0/0/9.500 remote-site-id 3
offset=local-site-id
range=number of interfaces configured?
show l2vpn connections instance XXX extensive
**implicit remote-site-id, it is infered base on the order the interfaces are added into the site config. Difficult to see errors!!!! simple to configure
set routing-instances XXX instance-type l2vpn
interface ge-0/0/9.200
.300
routing-distinguisher LoIP:111
vrf-target target:ASN:111
protocols l2vpn encapsulation-type ethernet-vlan
site ONE
site-identifier 1
interface ge-0/0/9.200 -> remote-site 2 (becaue loca-site is 1)
interface ge-0/0/9.500 -> remote-site 3
…
L2VPN Advanced concepts
Multihoming
sure primary and backup connections with bgp. the backup will use LP=1. primary LP=65535
remote PE;
show route table INSTANCE.l2id.0 detail -> BGP status after path selection proces: you an see both paths
primary PE:
show l2vpn connections instance XXX -> you will see the connection from the backup PE with state “RN” because the primary PE is the DF (designated fw)
backup PE
show l2vpn connections -> connections are “LN” local site not designated (AC is shutdown), because primary PE is DF.
Martini Encap
Martini circuit = LDP-signaled pseudowire.
Martini Encap = how to send l2 traffic via MPLS pseudowire -> “control word” between mpls label and l2 customer header
Ethernet control word = 4bits=0 + 12bits=0 + Seq Num = 16 bits
Normalization
swapping vlan tags
set interface ge-0/0/8 vlan-tagging encapsulation flexible-ethernet-services
unit 200 encapsulation vlan-ccc
vlan-id 200
input-vlan-map swap vlan-id 100
outout-vlan-map swap
show interfaces ge-0/0/8.200 -> it shows the in/out swap labels)
OOB RR
RR needs LSPs to resolve L2VPN prefixs, but as it is OOB, it can’t resolve the NH with LSPs (inet3.0)
sol: use inet.0 -> set routing-options resolution rib bgp.l2vpn.0 resolution-ribs inet.0
set routing-options route-distinguisher-id PE_LO_IP
RT constraint
PE tells neighbors the RT that is interested in (using “family route-target”). Then VPN prefixes are sent second.
show bgp summary -> “bgp.rtarget.0” = the address family has been negotiated
show route table bgp.rtarget.0
advertising_ASN:RT/96 (ie: 64512:64512:111/96)
in RR:
set protocols bgp … family route-target advertise-default = “sends me everything”
from RR-client
show route table bgp.rtarget.0
0:0:0/0 –> default RT that says send everything to RR
needs each PE and RR:
set routing-options resolution rib bgp.rtarget.0 resolution-ribs inet.0
L2Circuit LDP signaled Pseuowires (Martini)
bpg (kompella) and ldp (martini) both use AC, martini encap (control word), data plane is identical
easy to config, trade-offs:
manual targeted ldp sessions, no auto-discovery (like bgp)
set protocols ldp interface lo0.0 (update fw to allow tcp/dp 646)
set interfacces ge-0/0/8 encapsulation ethernet-ccc unit 0 (ethernet encap = accept all regardless vlan tag) — identical to L2VPN
set interfacces ge-0/0/9 vlan-tagging encapsulation flexible-ethernet-services
unit 100 encapsulation vlan-ccc vlan-id 100 (ethernet-vlan encap = each vlan tag is a pesudowire) — identical to L2VPN
set protocols l2circuit neighbor Remote-PE-Lo0.IP interface ge-0/0/8.0 virtual-circuit-id XXX
set protocols l2circuit neighbor Remomte-Pe-Lo0.IP interface ge-0/0/9.100 virtual-circuit-id YYY
show ldp session/neighbor/database
show l2circuit connections [neigbor IP]
FEC = Fw Equivalence Class = set of traffic forwarded the same way using MPLS = the traffic goes down the same lsp = remote PE Lo0
ldp l2circuit fec type = 128
ldp advertise: fec type, control word, ethernet mode, PW id (circuit id)v lan, mtu, vpn lable
L2Circuit troubleshooting
show l2circuit connections -> OL = no outgoing label -> it is not receiving a label from the remote PE
VC-Dn = problem with pseueowire -> check ldp
EM = encapsulation mismatch: encapsulation, circuit-id mismatch
NP = hw not present -> customer-id is wrong or interface missing ethernet-ccc or vlan-ccc
pseudowire status tlv -> only report problems with local customer interface
set protocols l2circuit neighbor remote-pe-loIP interface ge-0/0/8.0 pseudowire-status-tlv
fw filter for ldp udp/tcp 646
show ldp session/neighbor
advertised FEC containes the inbound vlan after PE has manipulated the frame (if required)
PE-2
set interfaces ge-0/0/9 vlan-tagging encapsulation flexible-ethernet-services
unit 100 encapsulation vlan-ccc
vlan-id 200 !!!!
PE-1
set interfaces ge-0/0/9 vlan-tagging encapsulation flexible-ethernet-services
unit 100 encapsulation vlan-ccc
vlan-id 100
input-vlan-map swap vlan-id 200
output-vlan-map swap
set protocols l2circuit traceoptions file FILE.txt flag connections detail fec detail
L2Circuit Advanced
vccv: virtual circuit connectivity verification: PE generate traffic to remote PE via pseudowire
each L2Circuit negotiates its own vccv options, sent in FEC (bgp)
cv: connectivity verification: icmp ping, lsp ping (udp 3503), bdf ip/udp
cc: control channel, somehow needs to avoid PHP. use special control word, inserts a special router label above the pseudowire label
set protocols l2circuit neighbor remote-pe-lo0 interface ge-0/0/8.0 virtual-circuit-id X
pseudowire-status-tlv
oam ping-interval 30 ping-multiplier 3 bfd-liveness-detection minimum-interval 1000 multi 5
show bfd sessions -> dest address is 127.0.0.1 !!! (different from standard bfd)
multihoming
the actual primary/backcup config is done in the remote-PE !!! the multihoming PEs (local) dont talk to each other!
set protocols l2circuit neighbor remote-pe-lo0 interface ge-0/0/7.0 virtual-circuit-id X backcup-neibhor remote-pe-backcup-lo0
* by default: no preemption, you can modify that with “revert-time x”
show l2circuit connections inteface ge-0/0/7.0 -> BK: backup connection in remote-PE. the back-up PE will show the l2circuit as down because it hasn’t received a label from the remote-pe
** local-switching: two sites connected to the same PE, no need of l2circuit pseudowire
set protocols l2circuit local-switching interface ge-0/0/8.0 end-interface ge-0/0/7.0
show l2circuit connecctions
** stitching pseudowires (merging companies) need interworking interface iw0 (ie L2VPN+L2Circuit
set interfaces iw0 unti 0 encapsulation vlan-ccc mtu 1514 vlan-id 610 peer-unit 1
unit 1 encapsulation vlan-ccc mtu 1514 vlan-id 610 peer-unit 0
set protocols l2iw
set routnig-instances VPN1 instance-type l2vpn interface iw0.0 route-distinguisher lo0:1 vrf-target target:asn:1
protocols l2vpn encapsulation-type ethernet-vlan
site VPNA site-identifier 2 interface iw0.0 remote-site-id 1
set protocols l2circuit neighbor remote-pe-lo0 interface iw0.1 virtual-circuit-id 1
FEC129 Pseudowire (no standard): auto-discover pseudowires
L2Circuit uses FEC type 128: explicit remote PE config, ldp signals the pseudowire, needs virtual-circuit-id
FEC 129: uses BGP to autodiscovery, so no explicit remote PE config needed, ldp signals the pseudowire. mix of L2Circuit and L2VPN
nowadays there is no notable adv to fec129
AGI: Attachment Group Id = virtual-circuit-id = vpn id -> l2vpn-id:ASN:umber (it is a extendedd bgp community)
SAII: surce attachment individual id = source site-id
TAII: target . . . = target site-id
same as L2VPN site-ids
PE autodiscover is identical as L2VPN (rt, rd, local-site-id)
data plane: ldp uses FEC129, AGI, SAII and TAII
- pe-ce interface config is identical to L2VPN. Enable LDP in Lo0, allow firewall
set protocols bgp group INT type internal
local-address lo0
family l2vpn auto-discovery-only !!!
neihbor remote-pe-lo0
set routing-instances TEST instance-type l2vpn
inteface ge-0/0/8.0
interface ge-0/0/9.100
route-distinguisher Lo0:num
l2vpn-id l2vpn-id:ASN:xxx *
vrf-target target:ASN:xxx
protocols l2vpn site SITE1 source-attachment-identifier 1
interface ge-0/0/8.0 target-attachment-identfier 2
SITE2 source-attachment-identfier 2
interface ge-0/0/9.100 target-attachment-identifier 4
show route receive-protocol bgp remote-pe-lo0 [detail]
under bgp.l2vpn.0 and INSTNACE.l2vpn.0
NLRI = RD:source-attachmen-id/96
show ldp database
show l2vpn connections -> l2vpn-id and target-attachment-id means it is fec129!!!
VPLS Intro – Virtual Private Lan Service
VPWS – virtual private wire service
pseudo-wire: no mac-learning, p2p, 1 ac per pseudowire
VPLS: SP acts as as switches LAN for customer
MAC learning like a switch
several psuedo-wires
signal: bgp (l2vpn), ldp (l2circuit), fec129
known MAC
unknow MAC: avoid loop -> if a PE received an unknow MAC from a remote PE, it only floods into the local CE
-replications can be problematic when having many PE and CE
-multi-homed?
- irb: one PE is the gw, cons: traffic from remote PE has to cross the whole BB, if PE with irb goes down -> outage -> sol: use VRRP between PEs
signalling:
bgp-signalled – L2vpn – kompella: autodiscovery (with RT), RR make scalable, block of labels: 1 bgp adv can signal every pseduowire in a vpls to all remote PEs, each site has Site-ID, rfc 4761
ldp-signalled – martini: routing instenace, virtual circuits = vpls-id. configuration of remote PE per VPLS (no autodiscover), targeted LDP-sessions, no RR.
fec-129: can use bgp or ldp, rfc 6074
VPLS BGP config
PE-CE
1) flexible just in case you use differnent encapsulations
set intnerfaces ge-0/0/8 flexible-vlan-taging
encapsulation flexible-ethernet-services
unit 300 encapsulation vlan-vpls
vlan-id 300
2) lock entire phy interface for only vpls
set intnerfaces ge-0/0/8 flexible-vlan-taging
encapsulation extendend-vlan-vpls
unit 300 family vpls
vlan-id 300
PE
set protocols bgp group INT type internal local-address LO-IP
family l2vpn signaling
neighbor remote-PE-LO-or-RR**
** RR out-of-band of MPLS path -> it can’t resolve prefixes ->sol: resolve VPN prefixes in inet.0 instead of inet.3
** RT family -> avoid unnecessary RT
set routing-instances VPLS instance-type vpls
interface ge-0/0/8.300
route-distinguisher lo:12345
vrf-target target:asn:12345
protocols vpls no-tunnel-servics -> if you dont have a PIC with tunnel services **
label-block-size x (def=8)
site ONE site-identifier 1 –> this implies is a VPLS BGP
interface ge-0/0/8.300
** with tunnel-services
vt-1/2/1.0
without tunnel-services
lsi.1242343 (label-switch-interface)
verification
show bgp summary -> bgp.l2vpn.0 (all advertisements)
VPLS.l2vpn.0
show route table bgp.l2vpn.0 match-prefix “PREFIX:RD:*” detail (!!! prefix:rd:remot_site:offset !!!)
show vpls connections instance VPLS [extensive -> see label-base, logs, etc] -> verify control-plane
show vpls mac-table instance VPLS -> verify data-plane
advertise blocl labels in bpg l2vpn? one label for each binding of a local interface to a remote interface
-> vpn label = label base + (remote-site-id – offset)
** in vpls, vpn label is not bound to a local customer interface !!! -> second look-up
** by default, bgp assing blocks of 8 labels per-vpls
VPLS LDP config and FEC129
= BGP: routing instace vpls, customer interface into vpls, protocols vpls into instance, optonal: no-tunnel-services
!=BGP: ldp in lo.0, manualy specify each neighbor PE (for each vpls), choose vpls-id (similar to virtual-circuit-id), no RT, no RD, no Site-ID
set protocols ldp interface lo0.0 + FW filter for LDP
set routing-instances VPLS instance-type vpls
interface ge-0/0/0.100
protocols vpls no-tunnels-services
vpls-id XXX
neighbor lo-PE1
show ldp database
show vpls connections instance VPLS -> VPLS-Id => LDP signaled!
= fec-129 pseudowire: routing-instance, RT, RD and l2vpn-id
!= no needed explicit source/target attachment identifiers (SAII/TAII) — they are automatically generated (based on remote lo-pe
set protocols ldp interface lo0.0 + Fw filter for LDP
set protocols bgp group EXAM type internal
local-address LO-IP
family l2vpn auto-discovery-only
neighbor LO-PE2
set routing-instance VPLS instance-type vpls
interface ge-0/0/0.100
route-distinguisher LO:xxx
l2vpn-id l2vpn-id:asn:xxxx -> FEC129 !!!
vrf-target target:ASN:xxxx
protocols vpls no-tunnel-services
show rorute receive-protocol bgp PE2-LO
show vpls connections instance VPS -> L2vpn-id => FEC129 !!!
VPLS: default vlan mode
4 vlan options in vpls:
-default vlan: one mac table or all interfaces regardless of the VLAN tag
=> an interface in a bridge domain receives ALL broadcast traffic with the original sender;s VLAN tag (even if the CE is in a different vlan! -> CE will drop it though)
-vlan-aware: separated mac tables for each unique vlan configued on a interface
-vlan-normalizing: one mac table for the whole vpls, vlan tags automatically swapped
-no-vlan: one mac table for the whole vpls, vlan tags automatically popped.swpapped
set interfaces ge-0/0/7 flexible-vlan-tagging
encapsuation flexible-ethernet-services
unit 200 encapsulation vlan-vpls
vlan-id 200
set interfaces ge-0/0/8 flexible-vlan-tagging
encapsuation flexible-ethernet-services
unit 100 encapsulation vlan-vpls
vlan-id 100
bridge domain: like advanced vlan, one broadcast domain but not tied to a vlan number
show vpls mac-table instance VPLS -> VLAN: NA => default vlan mode
VPLS VLAN normalization, vlan-aware, dual-stack vlans
vlan-aware: one MAC table per vlan. All inside one VPLS instance. NOTE: can’t be used if VPLS contains IRB interfaces !!! (you need to use vlan-normalization instead)
set routing-instances VPLS vlan-id all -> that’s it! (in every PE in the VPLS)
show vpls mac-table instance VPLS -> for the same routing-instance NAME you will see severl bridgin domain per VLAN
vlan-normalization: Any host can reach any host no matter the vlan they are in -> choose random vlan number for entire VPLS -> swap in/out vlan-tag
set routing-instances VPLS vlan-id 200 (in all PEs in VPLS)
show interfaces ge-0/0/0.100 –> VLAN-Tag (xxx) In(swap .200) Out(swap .100) …
show vpls mac-table instance VPLS
no-vlan mode: instance of using a random vlan-tag like in vlan-normalization, here, the vlan-tag is removed/poped. Same goal as vlan-normalization
set routing-instances VPLS vlan-id none (in all PEs in VPLS) You may lose CoS info because 802.1q header contains it
show interfaces ge-0/0/0.100 –> VLAN-Tag (xxx) In(pop) Out(push .100) …
show vpls mac-table instance VPLS -> Bridging domain: VLAN: none
dual-stack: QinQ – C-Tag: customer tag / S-Tag: service tag (identifies customer). It follows the default vlan mode => 1 bridge domain, 1 broadcast domain, doesnt care about VLAN. Both inner and outer Vlan-tag need to match for host-to-host communication
set routing-instances VPLS vlan-id all -> that’s it! (in every PE in the VPLS)
set interface ge-0/0/0.100 encapsulation vlan-vpls
vlan-tags outer 2000 inner 200
show interfaces ge-0/0/0.100 –> VLAN-Tag ( S-tag C-tag) In(pop) Out(push .2000) …
*set routing-instances VPLS vlan-id inner-all -> QinQ with vlan-aware (in every PE in the VPLS)
*set routing-instances VPLS vlan-id X -> QinQ with vlan normalization (in every PE in the VPLS) -> S-tag poped, C-tag normalized
*set routing-instances VPLS vlan-id outer-tag X inner-tag Y -> QinQ with vlan normalization for outer and inner (in every PE in the VPLS)
VPLS Adv features and Troubleshooting
Automated BGP VPLS Site-Id deployment
set routing-instance VPLS protocols vpls site X automatic-site-id -> PE listen to discover other Site-IDs, chooses one, listen again 30s to double-check is not in use
- resolving-conflicts: “Unassigned” control flag (A flag = Automatic) in BGP path-attr extended-comm
1- manual site-id are preffered (Automatic site-ids have the A flag control bit set =1)
2- auto advertisements are better than auto-claims
3- highest LP
4- lowest BGP NH
show vpls connections
MAC limiting and flood protection:
depends on hw: 5120 macs per vpls. 1024 macs per attachment-circuit. When MAC is over limit: New MACs are not lerned, traffic to those new MACs is flooded
set routing-instances VPLS protocols vpls mac-table-size X [packet-action drop]
set routing-instances VPLS protocols vpls interface-mac-limit Y [packet-action drop] (by default exceed MAC is not dropped)
set firewall family vpls filter FLOOD-CONTROL term police-BU then policer POLICER-200K accept
set firewall policer POLICER-200k if exceeding bandwidth-limit 200k bust-size-limit 15k then discard
set routing-instances VPLS forwarding-options family vpls flood input FLOOD-CONTROL
show vpls statistics instance VPLS
MAC flap protection (for multihoming or redundant links)
shutdown physical CE-facing interface if MAC flaps. pseudowire is never shutdown
set protocols l2-learning global-mac-move threshold-time 3 (for MACs learned for more than 300s)
threshold-count 6 (how many times a MAC can flap in threshold time)
statistical-approach-wait-time 3 (for MAC learned less than 300s)
[interface-recovery-time 300] by default CE-facing interface is shutdown
[cooloff-time 1] if MAC flaps between 3+ interfaces. by default Junos waits 30s befor shutddwon addtional interfaces
[virtual-mac MAC] list of MAC to exclude from MAC flapping protection like VRRP
set routing-instances VPLS protocols vpls enable-mac-move-action
VPLS, IRB and VRRP config
set interfaces irb.300 family inet address IP vrrp-group 10 virtual-address VIP priority 110 -> each PE will have different priority !!!!
set routing-instance VPLS instance-type vpls
vlan-id 300
interface ge-0/0/0.300
routing-interface irb.300 (irb can be in vpls and l3vpn)
show vpls connections extensive -> shows if there is an IRB in VPLS
ingress-replication may saturate bw (in ring topology) -> use multicast LSP for flooding efficiency (p2mp lsp) -> in ring topology, ingreess PE only send traffic twice.
set routing-instances VPLS provider-tunnel rsvp-te label-switched-path-template default-template => enable p2mp lsp!! only in BGP-signaled VPLS!
show rsvp session -> p2mp lsp name convention: DstPE_LOip:RD(loIP:xxx):vpls:routing-instance-name. Only one label!!!
show route table mpls.0 lable XXX
(lsi = label switch interface – virtual interface created so MAC addresses can be associated with a particular pseudowire in VPLS)
bgp-ldp vpls interworking (at stiching point)
set routing-instances INTERW instance-type vpls
vrf-target target:ASN:xxx
route-distinguisher LOIP:xxx
protocols vpls site BORDER site-identifier 2
mesh-group LDP-SIGNALED vpls-id 123 (this is the key config)
neighbor LO-IP-PE-peer
Troubleshooting
*In L2VPNs, there is a single pseudowire for a mapping between local attachment circuit and a remote attachment circuit
In BGP VPLS, there is a single pseudowire for a local site to a remote site, and there is a any2any mapping of local interface to remote interface
A PE makes a pseudowire for each local site, to each remote site -> this can create loops for BU traffic -> solution: just use one pseudowire that is shared by the local sites
show vpls connections instance VPLS -> output for the second+ local-site shows status = LM and no connections -> can be confusing, but is fine, it is using the first site.
- if you forget no-tunnel-services knob -> you need Tunnel Service PIC -> show vpls connection instante VPLS -> shows NP error
VPLS Multihoming (loop prevention)
BGP-VPLS
1) like BGP L2VPN, set one PE as primary and other as backup. The remote PE will only single a pseudowire to the primary PE. The backup PE shutdowns its local cust interface
PE primary
set routing-instance VPLS interface ge-0/0/0.300
route-distinguisher LO:12345
protocols vpls site FOUR multi-homing
site-identifier 4
site-preference primary -> LP=65535
interface ge-0/0/0.300
PE backup
set routing-instance VPLS interface ge-0/0/0.300
route-distinguisher LO:12345
protocols vpls site FOUR multi-homing
site-identifier 4
site-preference backuo -> LP=1
interface ge-0/0/0.300
show vpls connections instance VPLS -> status LN = local site not designated = you are the backup, lost DF election -> no getting tunnels to other VPLS sites
PE remote
show route table VPLS.l2vpn.0 -> you will see the diff LP!
show vpls connections instance VPLS -> you will only see the pseudowire to the primary PE
2) Multihome + singlehome in same PE.
- when PE has multiple sites, the lowest site-id signals the pesudowire, and all other sites share it.
- CRITICAL: multihome site has the highest site-id when we have single-home and multi-home. So the single home site pseusowire is always signaled. DF election will avoid the loop for multihome PE multihome + singlehome
set routing-instance VPLS interface ge-0/0/0.300
interface ge-0/0.1.200
route-distinguisher LO:12345
protocols vpls site TWO site-identifer 2 -> this pseudowire will come-up
interface ge-0/0/1.200
FOUR multi-homing
site-identifier 4 -> this pseudowire will not come-up, will use site-2
site-preference primary -> LP=65535
interface ge-0/0/0.300 PE remote
show vpls connections instances VPLS -> for Site 2, you will see Up but for Site 4, you will see RM (remote-site-ID not minimum designated) 3) Best site: overrides the default election of signaling the pseudowire with the lowest site-id- site-id with no interfaces -> pseudowire will come up !!!
So to avoid down-time (only 1 pseudowire active, if its site goes down, need to signal a new one) when having multi-home + single-home sites in a PE
=> use best-site with a dummy site-id that has no interfaces!!! => you will have a pseudowire always up between PEs no matter which site is up or down in the PE. So each PE has a dummy site-id. PE multihome + singlehome + dummy site
set routing-instance VPLS interface ge-0/0/0.300
interface ge-0/0.1.200
route-distinguisher LO:12345
protocols vpls site TWO site-identifer 2
interface ge-0/0/1.200
FOUR multi-homing
site-identifier 4
site-preference primary
interface ge-0/0/0.300
NINE_NINE_ONE site-identifer 991
best-site -> this pseudowire will be always up and shared by the other sites in the PE
mac-flush PE remote
show vpls connections instance VPLS -> only your dummy local-site will have connections up or RB (for the multihome not best-site), the other local-site will show connections as LB = Local site not best-site best-site is advertised via control-flaps in the L2 info BGP community:
it uses:
down-bit: signals if a CE is up or down
flush-bit: flushes MAC addresses
best-site bit: bit for the best site, not officially assigned!!!
LDP-VPLS
1) Like L2Circuit multihoming. All config is in the remote PE, and not in the PEs connected to the multihomed site.
PE remote
set routing-instances VPLS …
protocols vpls vpls-id 123
neighbor LO-PE2 revert-time 5
backup-neihbor lO-PE3 standby
2) VERY OPTIONAL: running STP with a customer -> creates a new instance
set routing-instances VPLS-MSTP
instance-type layer-control !!!!
interface ge-0/0/1.100
interface ge-0/0/2.100
protocols mstp configuration-name SITE1
revision-level 1
interface ge-0/0/1
interface ge-0/0/2
msti 1 vlan 1-4094
show spanning-tree mstp configuration routing-insatance VPLS-MSTP
LAB: LDP-VPLS, BGP-VPLS.
EVPN INTRO (RFC 7432)
vpls disadvantage: MAC learning via Data plane (flood and learn: inefficient, inconsistent, fw filter difficult), multi-homing requires to shutdonw CE interfaces to avoid loop (no active-active), only one active RIB at a time, 3 signalling methods
evpn overview: uses BGP: adv/withdraw/move MAC, multi-home, irb
BGP RT to autodiscovery, no flood-and-learn. remote MACs learnt via control-plane <- PE snoop ARPs to learn MAC-IP and advertise via bgp PE can answer local ARP request for remote MACs = ARP supression allow/reject MAC -> routing policy.
MAC mobility protection:
Ethernet Segment: set of links connect to the same customer device. Multi-home links are advertised in BGP -> key to avoid loops: ESI: ethernet Segment Id (ESI of all zeros = single-home)
active-active IRBs: no need of VRRP
MPLS dataplane is not mandatory, it can use VXLAN -> add VXLAN header: vni = vxlan id
AFI=25
sAFI=80=evpn
EVPN Using BGP to Advertise MACs and to Flood Traffic
EVPN Instance = EVI = “vrf”
EVPN Types
type1: ethernet auto-discovery route
type2: mac/ip advertisement route <- arp snooping: it sends 2xtype2: one with MAC only and other with MAC/IP
type3: inclusive multicast ethernet tag route (BUM traffic)
type4: ethernet segment route
ethernet tag = vlan-id
Type2: MAC or MACIP
- in VPLS, each PE has a pseudowire to each other PE -> each pseudowire has a unique VPN label -> this enables data plane learning
- in EVPN, no data plane learning -> Type2 can use same label for all remote PEs -> all devices in an EVI share a common VPN label for know MACs
MAC, Vlan tag and VPN label is enough
Type3: request flood traffic from remote PEs. Use L3VPN Multicacst concepts. PE join inclusive-tree for each bridge domain in an EVI
contains PMSI attribute -> that is a path attribute inthe BGP update message. It has a unique MPLS label (different from typ2). Tunnel type is Ingress Replication (sending PE replicates the flood packet for each remote PE, instead of using multicast)
type3 content is quite short. most things are in the PMSI section
*EVI has at least two labels: one for known macs for “all” bridge domains and
one for flood traffic “per” bridge domain (ie 4 bridge domains -> 4 unique vpn labels)
EVPN Configuring a Single-Homed VLAN-Based EVI
requisites:
ISIS/OSPF all PEs-RR
MPLS LSP between PEs (RR can be oob of the mpls path -> must do: set routing-options resolution rib bgp.evpn.0 resolution-ribs inet.0 (RR must resolve NH in inet0 instead of inet3 because it is not in the MPLS path)
FW filters: bpg, igp, ldp/rsvp
LB: set policy-options policy-statement LB then load-balance per-packet
set routing-options forwarding-table export LB
set protocols bgp group INTERNAL family evpn signaling –> mandatory
inet-vpn unicast –> optional for L3VPN!
vlan-based EVI: instance-type evpn
only one vlan-id
one single bridge domain with automatic vlan normalization (it doesnt matter what vlan tag you configure on the various customer-facing interfaces)
set routing-instance BLUE instance-type evpn
vlan-id 90
inteface ge-0/0/0.90
route-distinguisher LO:90
vrf-target target:ASN:90
protocols evpn
// MX l2 interface
set interface ge-0/0/0 flexible-vlan-tagging
encapsuation flexible-ethernet-services
unit 90 encapsulation vlan-bridge
vlan-id 90
family-bridge
show bgp summary
show route table bgp.evpn.0 match-prefix "2:RD:*"
2:RD(lo:vlan)::ethe-tag(vlan-id)::(mac|mac::ip)/304
3:RD(lo:vlan)::ethe-tag(vlan-id)::sender-pe-lo/248
show evpn instance BLUE extensive (very long!)
show evpn database
show evpn mac-table (for vlan-based evi / instance-type evpn)
show bridge mac-table (for vlan-aware evi / instance-type virtual-switch)
vlan-aware EVI: instance-type virtual-switch
as many bridge domains as you like
each bridge domain is aware of the vlans it hosts
IM = inclusive multicast
EVPN Configuring a Single-Homed VLAN-aware bundle EVI
vlan-aware evi -> each vlan gets its own named bridge domain in the routing instance.
set routing-instance GREEN instance-type virtual-switch
interface ge-0/0/0.1245
interface ge-0/0/1.3525
route-distinguisher lo:aaa
vrf-target target:asn:aaa
protocols evpn extended-vlan-list [ 50 60 70 ]
bridge-domains v50 vlan-id 50
v60 vlan-id 60
v70 vlan-id 70
set interface ge-0/0/0 flexible-vlan-tagging
encapsulation flexible-ethernet-service
unit 1245 family bridge interface-mode trunk
vlan-id-list [ 50 60 70 ]
show evpn instance extensive GREEN -> see several bridge domains. One single vpn label for all MACs in all bridge-domain. each vlan has its own label for BUM (IM)
show route table bgp.evpn.0 match-prefix “3:lo-pe:*:”
show evpn database instance GREEN
show bridge mac-table instance GREEN
EVPN Multihoming Configuration and Type 4 Routes (Ethernet Segment: advertise PEs in a ES, and choose DF) Prevent loops when traffic comes from remote PE
CE links are in bundle ae to different PEs. All active links.
CE
set chassis aggregated-devices ethernet device-count 1
set interfaces ge-0/0/0 gigether-options 802.3ad ae0 ->to PE1
set interfaces ge-0/0/1 gigether-options 802.3ad ae0 ->to PE2
set interface ae0 flexible-vlan-tagging
mac xx:xx:xx:00:02:30 (optional)
aggregated-ether-options lacp active
unit 11 vlan-id 11
family-inet address IP/24
** eachc unit is in a different VRF
PE
set chassis aggregated-devices ethernet device-count 1
set interfaces ge-0/0/0 gigether-options 802.3ad ae0 ->to CE1
set interface ae0 flexible-vlan-tagging -> each unit can use single or stacked tagging
encapsulation flexible-ethernet-services -> each unit can use any service: vpls, evpn, etc
aggregated-ether-options lacp system-id xx:xx:xx:xx:xx:xx (same in both PEs!)
esi 00:xx:xx:xx:xx:xx:xx:xx:xx:xx all-active (same in both PEs) (if ESI all zero -> single-home)
unit 90 encapsulation vlan-bridge
vlan-id 90
family bridge
unit 1234 family bridge interface-mode trunk
vlan-id-list 11-14
** eachc unit is in a different VRF
show evpn instance extensive NAME -> check for the aeX and ESI
show evpn instance NAME designated-forwarder
show route table bgp.evpn.0 match-prefix “4:*” [detail] -> 4::ESI:PE_loIP/296
type4 ethernet segment -> avoid loop in multihoming (similar to type1!!!)
- accepted only by PEs on the same ES -> discover other PEs on the segment + elect DF (designated fw) for segment =? auto-generated RT for the segment (ES Import -> and creates a hidden import policy to accept that RT) ->PEs in the same segment, accept it, the other PEs, ignore it.
type of loops: – remote PE1 send BUM to both multihomed PE-2/3 -> fixed with DF in segment = DF only PE that forwards recevied BUM from remote-PE to local-CE
multihomed CE send BUM to both PE2/3 ech EVI has A DF
EVPN Multihoming Features Using Type 1 Routes (Ethernet Auto-Discovery: accepted by every PE in the VPN, not just the ES) Prevent loops when traffic comes from local-CE
(COMPLEX!!!)
two types: type1 ethernet auto-discovery **Per-ES: one single type1 is sent for the entire ES => all other PEs learnt about the ES automatically
3 pieces: advertise RT of each EVI in ES, special ESI MPLS Label community to avoid loops (all-active=0, be careful with 20b vs 24b), ESI and MPLS Label = 0 (the actual label is the ESI MPLS label) !!!
two functions: Mass MAC withdrawal: PE withdraws its type1 per-ES when the CE-link goes down. So remote PE uses other type1 for that segment. This is quicker than sendng one type2 withdraw for each MAC in the segment.
Loop prevention: PE-3 received BUM from CE, it sends to PE-2 (that is in ES), but PE-2 doesnt send the BUM to the CE because the ESI in the type1, it sends it to other different ESI (= split horizon filtering). Keep in mind that there are 3 labels here: bottom = ESI label, medium = VPN label, top = Transport label.
**Per-EVI: multiple type1 sent, one per EVPN instance in ES: MPLS Label != 0 !!!!
twp functions: Enable remote-PEs to LB to all-active ESI = aliasing (if the receiver PE doesnt now the MAC, still can forward it)
faster failover in single-active ESI = backup path
You need both type1 AD
1st: type AD per-ES: remote-PE know about the ES exists
2nd: type AD per-EVI: remote-PE can send traffic to devices connected to ESI
show evpn instance extensive NAME
show evpn database instance GREEN -> if “Active Source” = ESI -> it can LB
EVPN MAC Mobility and IRB Interfaces
enabled by default
Typ2 + “mobility mobility” community = static flag + seq nu (same seq -> tie braker is PE with lowest IP) +
show route table bgp.evpn.0 match-prefix 2:(RD:lo:x)::vlan::MAC:21/304 detail
default mac flap protection: 4 moves in 3 minutes -> 5th moved is blocked = PE will not advertise type2 -> manual clearing
clear evpn duplicate-mac-suppresion
show evpn database extensive mac-address MAC instance EXAMPLE
set routing-instance EXAMPLE protocols evpn duplicate-mac-detection detection-threshol 4 detection-window 180 auto-recovery-time 300 (default 0 -> manual recovery)
Every PE can host an active IRB. 3 options
- automatic gateway mac-ip sync: each IRB has unique IP/MAC. Advertised via type2 + “Default Gatway” community. Network syncs automatically PE1
set interfaces irb unit 50 family inet address 10.50.0.1/24 mac 00:00:10:50:00:01
set routing-instancces GREEM bridge-domains v50 routing-interface irb.50
protocols evpn default-gateway advertise (default)
PE2
set interfaces irb unit 50 family inet address 10.50.0.2/24 mac 00:00:10:50:00:02
idem show route table bgp.evpn.0 match-prefix 2:(RD:lo:x)::vlan::MACirb::IPirb detail
show bridge evpn peer-gateway-macs -> list of all automatic-gateways MACs received
show evpn instance extensive trade-off: migrated VMs lose their gw IF the original PE goes down
- manual gateway mac-ip sync: eachc IRB has same IP/MAC. No bgp advertise. Manual sync PEx
set interfac irb unit 50 family inet address 10.50.0.1/24 mac 00:00:10:50:00:01
set routing-instances GREEN protocols evpn default-gateway do-not-advetise
bridge-domains v50 routing-interface irb.50 show evpn instance GREEN extensive (no default gw MAC advertisement !!!) trade-off: mgmt is limited because all PE irb have the same IP
- Virtual gateway (most famous): each IRB has two IP: 1 unique for mgmt (system MAC) and a shared IP for default gw (VRRP MAC) PE1
set interfaces irb unit 50 family inet address 10.50.0.1/24 virtual-gateway-adress 10.50.0.254
set routing-instance GREEM protocos evpn default-gateway no-gateway-community -> type2 is generated for irb unique IP but withtou cmmunity
bridge-domains v50 routing-interface irb.50
PE2
set interfaces irb unit 50 family inet address 10.50.0.2/24 virtual-gateway-adress 10.50.0.254
idem trade-off: a bit more complex, use more IPs and MAC table increases
LAB:
EVPN Integration with L3VPNs (COMPLEX !!!! chained composite next hop -> efficiency in PFE: can rewrite big ammount of entries when NH (PE failover/changes)
CCNH is mandatory for EVPN: enables MAC rewrite and label actions between Vlans
l3vpn -> type: vrf / family: inet-vpn unicast
set routing-instances GREEN instance-type vrf
interface irb.50
route-distinguisher LO:xxx vrf-target target:asn:xxx vrf-table-lable (one-label for entire vrf)
irb can be in l3vpn (l3) and evpn (l2)
By default PE advertise for directled connected host (from the irb) -> l3vpn /32 to remote PE, so dont follow the /24 irb advertised by all other PEs and can go directly to the PE advertisnig the /32 — IMPORTANT !!!!
PE advertises 1x EVPN Type2 MAC for each IP leartn in the irb
1x EVPN type2 MAC+IP idem
1x l3vpn /32 (useful for PE that dont talk evpn)
remote PE that receives evpn type2 mac+ip CREATES l3pvn route in l3vpn table with preference 7 (because contains a lot of frame manipulation) and then uses evpn instead of l3vpn => useful for moving frames between vlans !!!!
show route table GREEN_L3.inet.0 10.60.0.11 protocol evpn detail -> “Ethernet header rewrite”
detail -> “Composite Next Hop”
set routing-instances GREEN protocols evpn remote-ip-host-routes -> creates local l3vpn host route entries for remote IPs
extra:
evpn-vpws (virtual private wire services) evpn signals pseudo-wires, no mac learning. only type1/4 (no type2), active/active multihoming
evpn-etree: hub-spoke, prevent spoke-to-spoke, no need for routing-policies or asym RTs
Inter-AS MPLS VPNs (complex but interesting, I think i understand it)
three methods: A
A: treat the other AS like a regular customer site so it is added to the VRF. No unique config required. Trade-off: extensive config to maintain (routes and MAC to learn)
From AS1, the ASBR from AS2 is like a CE, and viceversa. No MPLS between the devices, just VLAN multiplexing
B: each ASBR exchange BGP VPN (and labels) via eBGP (good when both AS belongs to the same org). No LSP between ASBRs. because it is eBGP, all bgp vpn are advertised and accepted. No need of vrfs. VPN labels are swapped at both ASBRs. Good: no need of vrfs in ASBR, simple is you are happy to run MPLS between both networks. Trade-off: ASBRs must learn every single VPN adv and generate a new vpn label -> strong CP and large LFIB
C: family bgp-label-unicast, create LSPs between AS. More complex but more scalable. PEs from each AS peer each other: eBGP + exchange vpn labels and prefixes => Loopbacks from each AS need to be exchanged, LSP between ASNs !!-> BGP-LU fixes it.
Good: no vrfs in ASBR, no large LFIB in ASBR
trade-off: complicated, increase label stackc
bgp-lu: advertise regular IPs with a transport!!! MPLS label. Between ASBRs only:
There are three LSP, one inside AS1, other between ASBRs and other in AS2.
PEs (inter AS!!) talk “family l2vpn signaling + eBGP!!”.
PES and its ASBR talk “family inet labeled-unicast + iBGP!!!”
ASBRs talk “family inet labeled-unicast + eBGP!!”
three label stack: top: transport to ASBR
middle: bgp-lu label processed by ASBR, and then swapped to send it to neigbbor ASBR
bottom: vpn label.
PE1 (AS1)
set routing-instances L2VPN-1 instance-type l2vpn
interface ge-0/0/6.620
route-distinguisher lo:asn
vrf-target target:asn:xxx
protocols l2vpn encapsulation-type ethernet-vlan
site CE1 site-identifier 1
interface ge-0/0/6.620 remote-site-id 2
set protocols bgp group INTERNAL type internal (no export policies!)
local-address lo
family inet labeled-unicast resolve-vpn (copies bpg-lu from inet.0 to inet.3 -> PE1 can use PE2-lo to resolve vpn prefixes)
neighbor ASBR-1-lo
EXTERNAL type external (to remote PEs in AS2)
multihop
local-address lo
family l2vpn signaling
peer-as AS2
neighbor PE2-AS2-lo
show route received-protocol bgp ASBR-1-LO –> you will see the PE2-AS2-LO in inet.0 and inet.3 !!!
PE2-AS2-LO –> you wil see bgp.l2vpn.0 and L2VPN-1.l2vpn.0 prefixes !!!
table mpls.0 -> you will see three labels to PE2-AS2
show l2vpn connections
ASBR1 ** normally from eBGP to iBGP you need to change NH because iBGP peers dont know the eBGP NH…
set protocols bgp group INTERNAL type internal ** when new label is generated, NH is changed !!! for that reason dont need next-hop-self here!
local-address lo
family inet labeled unicast
neighbor PE1-lo
EXTERNAL type external
family inet labeled unicast
export AS1-PE-LO-EXPORT
peer AS2
neighbor ASBR2-physical-ip
set protocols mpls traffic-engineering mpls-formarding –> copies LSPs into inet.0 BUT only use for forwarding. IGP still used for CP.
interface all
*Carrier-of-Carried (CoC) VPNs: Small SP is in two distant locations (with different ASn), and uses a large SP to connect both locations. Inter-AS MPLS but using another SP with option-C => BGP-LU between ASBRs and PEs.
BGP-LU ibgp: cust-pe1 <> cut-asbr1
BGP-LU ebgp: cust-asbr1 <> coc-asbr1
BGP-LU ibgp: coc-asbr1 <> coc-asbr2
BGP-LU ebgp: coc-asbr2 <> cust-asbr2
BGP-LU ibgp: cust-asbr2 <> cust-pe2
BGP-L2VPN ebgp: cust-pe1 <> cust-pe2
LSP cust-pe1 <> cust-asbr1
LSP coc-asbr1 <> coc-asbr2
LSP cust-asbr <> cust-pe2
CUST-PE1 (AS1)
set routing-instances L2VPN-1 instance-type l2vpn
interface ge-0/0/6.620
route-distinguisher lo:asn
vrf-target target:asn:xxx
protocols l2vpn encapsulation-type ethernet-vlan
site CE1 site-identifier 1
interface ge-0/0/6.620 remote-site-id 2
set protocols bgp group CUST-AS2 type external
multihop
local-address lo
family l2vpn signalinb
peer-as AS2
neighbor CUST-PE2-lo
INTERNAL type internal
local-address cust-pe1-lo
family inet labeled-unicast resolve-vpn (copies bgp-lu from inet.0 to inet.3)
neighbor cust-asbr1-lo
show route received-protocol bpg CUST-ASBR1-LO -> in inet.0 and inet.3 (because resolve-vpn and NH changed!) learn CUST-PE2-LO
CUST-PE2-LO -> bgp.l2vpn.0 and L2VPN-1.l2vpn.0
show l2vpn connections
CUST-ASBR1
set protocols bgp group COC-SP type external
family inet labeled unicast
export CUST-PE-LO-EXPORT
peer-as COC-ASN
neighbor coc-asbr1-phy-ip
INTERNAL type internal
local-address cust-asbr1-lo
family inet labeled-unicast)
neighbor cust-pe1-lo
COC-ASBR1: ** no need of export policy and no need of “resolve-vpn” because COC carrier has no visibility of CUST VPNs
** no need of NH-self like in option-C because when advertising a new label, NH is updated automcatically ebgp->ibgp
** in real world, the COC puts CUST into a L3VPN to keep separation.
set protocols bgp group CUST type external
family inet labeled unicast
peer-as CUST
neighbor cust-asbr1-phy-ip
INTERNAL type internal
local-address coc-asbr1-lo
family inet labeled-unicast
neighbor coc-asbr2-lo
Circuit Cross-Connect (ccc)
No MAC learning (frames are simply forwarded). It can stitch two RSVP LSPs
** pseudowire: donwside: 2xRSVP LSP, one in each direction, only dedicated to the CCC vpn -> increase RSVP state if you have many ccc
upside: just one label
pe1:
set protocols connetions remote-interface-switch CCC1 interface ge-0/0/9.300
transmit-lsp LSP_CEA-to_CEB
receive-lsp LSP_CEB-to_CEA
pe2:
set protocols connetions remote-interface-switch CCC1 interface ge-0/0/8.300
transmit-lsp LSP_CEB-to_CEA
receive-lsp LSP_CEA-to_CEB
** you need to define the LSP !!!
show connections remote-interface-switch CCC1
** Local switching: connecting two ports in the same device
set interfaces ge-0/0/8 flexible-vlan-tagging
encapsulation extended-vlan-ccc
unit 300 vlan-id 300
unit 300 family ccc
9 idem
set protocols connections interface-switch 008_to_009 interface ge-0/0/8.300
interface ge-0/0/9.300
show connections interface-switch 008_to_009
** LSP stitching:
abr:
set protocols connections lsp-switch pe1-to-pe2 transmit-lsp abr-to-pe2
receive-lsp pe1-to-abr
pe2-to-pe1 transmit-lsp abr-to-pe1
receive-lsp pe2-to-abr
** you need to define the LSP !!!
show route table mpls.0 lable xxxs
Multisegment Pseudowires: RFC 6073
pseudowire need to cross between different AS = Inter-AS option B but! ABRs take part in the vpn
T-PE: Terminating PE = PE hosts the customer-facicn interface = PE terminates the pseudowire
S-PE: Switching PE = PE that stitches two segments (ABR)
SS-PW: single-segment pseudowire: the “normal” one. vpn label is not changed between T-PEs
MS-PW: multi-segment pseudowire: set of pw segments that function as a single p2p pw. VPN label changes
junos uses FEC129 for MS-PW.
BGP autodiscover the router at the other end of the segment.
T-PE only needs to see the next S-PE in the path
LDP exchange VPN label for the specific segment: S-PEs swap vpn labels between segments
LSP between S-PEs (ABRs)
family l2vpn autodiscovery-mspw: 3xLSP: T-PEX1 <> S-PEX2 (ibgp), S-PEX2 <> S-PEY2 (ebgp), S-PEY2 <> T-PEY1 (ibgp)
T-PEX1
set routing-instances MS1 instance-type l2vpn
interface ge-0/0/9.0
route-distinguisher LO:200
l2vpn-id l2vpn-id:ASN:200
vrf-target target:ASN:200
protocols l2vpn site CE1 source-attachment-identifier 200:200:1 => Type 2 AII !!!
interface ge-0/0/9.0 target-attachment-identifier 200:200:2
pseudowire-status-tlv
set protocols bgp group INT type internal
local-address LO
family l2vpn auto-discovery-mspw
neigbor LO-S-PEX2
show route table mpls.0
show l2vpn connections extensive –> l2vpn-id = FEC129 + segments
S-PEX2
set protocols bgp group INT type internal
local-address LO
family l2vpn auto-discovery-mspw
export NH-SELF
neighbor LO-T-PEX1
group EXT type external
multihop ttl 1
local-address LO-S-PEX2
family l2vpn auto-discovery-mspw
peer-as AS2
neighbor LO-S-PEY2
static route to LO-S-PEY2 nh phy-int
set protocols ldp interface ge-TO-T-PEX1.0
lo.0
rsvp interface ge-To-S-PEY2
mpls label-switched-path TO-S-PEY2 to LO-S-PEY2, no-cspf
interface ge-TO-T-PEX1 ??
interface ge-TO-S-PEY2 ??
show route receive-protocol bgp LO-T-PEX1 –> MS-PW has two new tables: bgp.l2vpn.1 and ldp.l2vpn.1
LO-S-PEY2
**LAB: Inter-AS Option-C and MS-PW ***
VPLS Hub and Spoke Topologies
preventing vpls local switching (two CEs connected to same PE) -> config in all spoke PEs: set routing-instance VPLS_HS no-local-switching
3 methods
** asymmetric RT: by deault all PEs in the VPLS use the same RT
H&S: Hub PE sends RT1 to Spoke PEs
Spoke PEs send RT2 to Hub PE, onl accepted by Hub PE!
HUB PE
set policy-options community Hub2Spoke members target:ASN:123
Spoke2Hub members target:ASN:456
policy-statement ADVERT-H2S term h2s then community add Hub2Spoke, accept
RECEIVE-S2H term accept-spoke from community Spoke2Hub then accept
reject then reject
set routing-instances VPLS_HS vrf-import RECEIVE-S2H
vrf-export ADVERT-H2S
show vpls connections instance VPLS_HS --> nothing new here
SPOKE PE
set policy-options community Hub2Spoke members target:ASN:123
Spoke2Hub members target:ASN:456
policy-statement ADVERT-S2H term s2h then community add Spoke2Hub, accept
RECEIVE-H2S term accept-hub from community Hub2Spoke then accept
reject then reject
set routing-instances VPLS_HS vrf-import RECEIVE-H2S
vrf-export ADVERT-S2H
no-local-switching
show vpls connections instance VPLS_HS --> connection-site: only to Hub PE
** site-range with BGP VPLS. use site-range 1 in all spoKe PEs. All spoke PEs have site-id higher than site-range. No routing policies.
Hub PE has site-id 1.
SPOKE-PE
set routing-instances VPLS_HS instance-type vpls
no-local-switching
vrf-target target:asn:123
protocols vpls site-range 1
no-tunnel-services
site N20
site-identifier 20
show vpls connections instances VPLS_HS -> the connections to other PE spkes are in OR=Out of range !!!
** Hub-spoke LDP VPLS = hierarchical VPLS: Hub is VPLS, Spokes are L2Circuit (no MAC learning)
spoke-PE = MTU-s = multitenant unit switch
hub-PE = PE-rs = PE routing and switching (RFC 4762)
HUB (vlan-aware -> accepts all vlans)
set routing-instances VPLS_HS instance-type vpls
vlan-id all
interface ge-0/0/8.0
protocols vpls no-tunnel-service
vpls-id 1234
neighbor PE1-S-lo
neighbor PE2-S-lo
set interface ge-0/0/8 (CE) encapsulation ethernet-vpls unit 0 famiy vpls
show vpls connections instances VPLS_HS
show vpls mac-table instance VPLS_HS
***if you want spoke2spoke via hub: create mesh group in HUb
set routing-instances VPLS_HS instance-type vpls
vlan-id all
interface ge-0/0/8.0
protocols vpls no-tunnel-service
mesh-group L2-circuits <----
vpls-id 1234
local-switching <------
neighbor PE1-S-lo
neighbor PE2-S-lo
SPOKE
set protocols l2circuit neighbor PE1-S-lo interface ge-0/0/8.0 virtcual-circuit-id 1234 (matches vpls-id in HUB !!!!)
set interface ge-0/0/8 (CE) encapsulation ethernet-ccc unit 0
show l2circuit connections
=========================================
Junos Layer 3 VPNs On-Demand
=========================================
Refresher VPNs and MPLS: LDP (automatic LSP via IGP), RSVP (manual LSP but with TE). LSP between PEs. LSP are unidirect
Layer 3 VPNs Overview
RD type0: 2B ASN + 4B number
type1: 4B IP (PE-lo) + 2B number (best for CE multihome because a RR would see two different vpnv4)
type2: 4B ASN + 2B number
Mask (1B) + MPLS Label (3B) + RD( type (2B) + Admin (var + Number (var)) + ipv4 (4B)
vpnv4 afi=1 safi=128
Layer 3 VPNs Operation Characteristics
policy-based routing
RT: vrf-target
inner label: advertised by BGP (vrf lable)
outer label: advertised by LDP, RSVP. (transport label)
Layer 3 VPN Configuration
IGP for PE/P Lo
isis or ospf
iBPG between PEs Lo + family inet-vpn unicast (show bgp neighbor LO)
set protocols bgp group IBGP type internal
family inet-vpn unicast
local-address LO
neighbor PEx-LO
LDP/RSVP + LSP between PEs
set interfaces X unit 0 family mpls
set protocols mpls interface X
set protocols ldp interface X
lo0
show mpls interface
show ldp interface
tables:
inet.0 – igp and bgp
inet.3 – rsvp/ldp routes used to resolve BGP nh
mpls.0 – all labels + actions
bgp.l3vpn.0 – all vpnv4 received from remote PEs. NH resolved using inet.3
.inet.0 –
set routing-instances VPNA instance-type vrf
interface ge-1/0/4.0 (PE-CE)
route-distinguisher LO:xxx
vrf-target target:asn:xxx (should match remote-PE) // you can use vrf-import/export policies
protocols bgp group G1 type external
peer ASG1
neighbir CE-IP
import IMPORT-G1
**routing-option autonomous-system ASX indepedent-domain (optional: customer attributes preserved using ATTRSET)
**as-override: when CEs are in the same ASN
set routing-options route-distinguisher LO -> automatically creates type1 RD for each VRF***
site-of-origin SoO – CE is multihome and as-override is required. -> avoid loops between multihome CEs! use vrf-import/export
set policy-options community SoO members origin:LO:yyy
Layer 3 VPN Verification
show route table
show route table bgp.l3vpn.0
show route receive/advertised-route
show route forwarding-table vpn VPN
vrf-table-label:
by default: egress PE label allocaton is per NH. IP header is not evaluated for fw in egree PE
vrf-table-label: egrees PE label is per VRF, IP header is used for fw after popping mpls label
OSPF as the PE-to-CE Protocol (rfc4577)
BGP by default accepts/sends everything (if no import/export)
OSPF needs a export policy !!! (bgp doesnt automaticallu redistribute to ospf)
set routing-instances VPNA instance-type vrf
interface ge-0/0/9.0
route-distinguisher lo:123
vrf-target target:asn:123
protocols ospf area 0.0.0.0 interface ge-0/0/9.0
export CUST_BGP_TO_OSPF (this creates LSA-5 external!)
show ospf neighbor instance VPNA
lsa1 router
lsa2 network: when in multiaccess network, only advertise 1 connection to “pseudonode”, not to each other.
lsa1/2 stay in the area
lsa3 summary: generated by ABR, and stays within an area. Other ABR regenerate the lsa3
lsa5 external: generated by ASBR, ABR doesnt change it.
PEs are always area0, although not explicit. PEs dont talk OSPF between then, they do BGP
type1/3 are exported by default as l3vpn type3 by PEs -> two bgp communities: route-type and domain-id
route-type: rte-type:area:lsa_type:lsa5_external(1=ext-type2,0=ext-type1)
domain-id: if source and remote domain-id are different -> PE generates lsa5. By default domain-id=null=0.0.0.0
equal -> PE generates lsa3
OSPF Optimal Routing (DN bit) ***
avoid loops -> DN bit + VPN external route-tag (legacy for lsa5)
*PE sets DN bit on any lsa3/5 generates –> LSA with this bit are never readvertisd back to the vpn
*vpn route-tag only used for legacy devices can’t set DN in lsa5 -> vpn route-tag=32b based on SP ASN
set routing-instances VPNA protocols ospf domain-vpn-tag XXXX (only if 4B-ASN!)
no-domain-vpn-tag (disable vpn-tag and DN bit!)
sham-links: multihop OSPF neighbor between PEs. requires a unique Lo in customer VRF. Like a virtual-link. PEs can exchange lsa1
set interface lo0 unit “1”!!! family inet address IP1/32
set routing-instance VPNA interface lo0.1
protocols ospf area 0.0.0.0 interface lo0.1
area 0.0.0.0 sham-link-remote PE3-lo0.1-IP metric 10
sham-link local IP1
Route Leaking **
sharing routes between vrf tables in same PE
**auto-export: PE analyzes vrf-import/expor policies and vrf-target and copies VPN routes that match that
set routing-instances VPNA vrt-target target:asn:123 !!! the same RT in both VRFs!
routing-options auto-export
VPNB vrf-target target:asn:123 !!!
routing-options auto-export
**rib-groups:
set routing-options rib-groups A2B import-rib [ VPNA.inet.0 VPNB.inet.0 ]
B2A import-rib [ VPNB.inet.0 VPNA.inet.0 ]
set routing-instances VPNA routing-options interface-routes rib-group inet A2B
protocols bgp group EXT family inet unicast rib-group A2B
VPNb routing-options interface-routes rib.group inet B2A
protocols bgp group EXT family inet unicast rib-group B2A
if you want to keep shared vrf routes from other PEs -> create policy
Hub-and-Spoke Topologies
2 VRFs: Spoke and Hub VRF. Hub CE connected to both. Issues with looping using BGP
CE spokes advertise prefixes with spoke-RT
CE Hub leanrs that and readvertise with hub-RT to spoke sites
spoke-PE
set routing-instances VPNA instance-type vrf
interface ge-0/0/0.0
route-distinguisher lo0:xx
vrf-import VPNA-import !!!
vrf-export VPNA-export !!!
protocols bgp group EXT type external
peer-as HUB
as-override
neighbor HUB-lo0
set policy-options policy-statement VPNA-import term 1 from protocol bgp, community hub then accept
2 then reject
VPNA-export term 1 from protocol [bgp static direct] then community add spoke, accept
2 then reject
community hub members target:ASN:100
spoke memebers target:ASN:101
Hub-PE
set interfaces ge-0/0/0 vlan-tagging unit 0 vlan-id 100 // SPOKE
family inet adress 10.0.29.1/24
unit 1 vlan-id 101 // HUB
family inet address 10.0.30.1/24
set routing-instances HUB instance-type vrf
routing-options autonomouns-system loops 2 !!!!
interface ge-0/0/0.1
route-distinguisher lo0:xx
vrf-import null !!!
vrf-export hub-out !!!
protocols bgp group EXT type external
peer-as SPOKE
as-override
neighbor spoke-PE-lo0
SPOKE instance-type vrf
routing-options autonomouns-system loops 2 !!!!
interface ge-0/0/0.0
route-distinguisher lo0:xx
vrf-import spoke-in !!!
vrf-export null !!!
protocols bgp group EXT type external
peer-as SPOKE
as-override !!!!
neighbor spoke-PE-lo0
set policy-options policy-statement spoke-in term 1 from protocol bgp, community spoke then accept
hub-out term 1 from protocol bgp then community add hub, accept
null term 1 then reject
community hub members target:ASN:100
spoke memebers target:ASN:101
Layer 3 VPN CoS (need to repeat, it didnt follow)
recommended rewrite EXP bits in each LSR, same policies in eachc PE
firewall filter
ingress PE
set firewall family inet filter exp-class term 1 from source IP/16 then forwarding-class assured-forwarding
loss-priority high
2 then accept
set interface ge-0/0/2 unit 0 family inet filter input exp-class (interface to CE)
address ip/30
set class-of-service classifiers exp VPN-class forwarding-class assured-forwarding loss-priority high code-point 101
best-effort loss-priority low code-point 000
expedite-forwarding loss-priority high code-point 111
network-control loss-priority high code-point 001
schedulers af transmit-rate percent 50
priority high
be transmit-rate remainder
priority low
ef transmit-rate percent 20
pririty high
nc transmit-rate percent 10
pririty high
scheduler-maps VPN-map forwarding-class assured-forwarding scheduler af
forwarding-class best-effort scheduler be
forwarding-class expedited-forwarding scheduler ef
forwarding-class network-control scheduler nc
rewrite-rules exp VPN-rewrite forwarding-class assured-forwarding loss-priority high code-point 101
best-effor loss-priority low code-point 000
expedited-forwarding loss-priority high code-point 111
network-control loss-priority high code-point 001
interfaces ge-0/0/0 unit 0 classifiers exp VPN-class (link to another PE/P!!)
rewrite-rules exp VPN-rewrite
set protocols mpls explicit-null –> we dont want PHP -> EXP bits lost for egreess PE
vpn prefix mapping:
set policy-options policy-statement MAP term 1 from community GOLD then install-nexthop lsp PE1_PE2, accept
2 from community SILBER then install-nexthop lsp PE1_PE3, accept
set routing-options forwarding-table expor MAP
show route forwarding-table vpn VPN-A
Layer 3 VPN Protection Mechanisms
*BGP PIC Edge: PIC = Prefix Independence Convergence -> install vpn route in fw table as backup -> faster convergence during PE failover
configured in ingress PEs
set policy-options policy-statement LB then load-balance per-packet
set routing-options forwarding-table export LB
set routing-instances CUST1 instance-type vrf
routing-options protect core -> PIC enabled!
…
show route extensive table CUST1.inet.0 IP/24 –> “indirect next hop” weight=0x1 (active) 0x4000 (backcup)
show route forwarding-table table CUST1 destination IP/24 –? idr xxx matches the “indirect nex hop” index
*Provider Edge Link Protection: at ingress PE. only for external peers
configured in ingress PEs and only if best path is already installed in fw table.
set policy-options policy-statement LB then load-balance per-packet
set routing-options forwarding-table export LB
set routing-instances CUST1 instance-type vrf
routing-options protect core –> it seems it needs PIC too???
protocols bgp group EBGP type external
family inet unicast protection -> enabled!!!
show route IP –> see “Multipath” two bgp NH
Layer 3 VPN Scaling
rfc 4364: create multiple BGP RR for VPN routes, BGP route refresh (supported by default), RT filtering
RR: on a P or device not part of MPLS fw path.
must resolve the advertised NH of PEs ->
not recommened: LSP from RR to all PEs.
static default route in inet.3
*best: route resolution RIB: set routing-options resolution rib bgp.l3vpn.0 resolution-ribs inet.0
no needed VRFs, just VPN address-family
scaling guidelines: num VRF tables (RE dependent), routes per device (hw dependent)
vrf localization: chained composite NH feature: sets of routes sharing same destination to a common fw NH
core-facing interfaces: set chassis fpc 3 vpn-localization vpn-core-facing-default -> install VRF routes with NH in FPC
network-services enhanced-ip
ce-facing interfaces: set routing-instances VPNA routing-options localizaton fib -> determines FPC that interfac belongs
show route vpn-localization [vpn VPNA]
BGP Route Target Filtering
in all PE and RR. You need “route resolution RIB” (as above section) in all PE/RR.
set protocols bgp group PE type internal
family route-target (afi=1, safi=132) –> created bgp.rtarget.0 table !! (show bgp summary)
…
Layer 3 VPNs and Internet Access (LAB: RR, RT filter, LDP tunnelling and Internet VPN !!!) ***
Non-VRF internet access: two connections, you connect to a different or same PE. NAT in CE
VRF internet access: 3 types: NAT in CE or in SP router or Hub CE. One connection to PE
ie NAT in CE, RIB groups in PE, routing
1) CE NAT config
set security nat source rule-set VRF-inet-access from interface ge-0/0/1.0
to interface ge-0/0/2.0
rule VRF match source-addres LAN1/24
destination-add LAN2/24
then source-nat off
rule inet-access match source-add LAN1/24
destina-add defau
then source-nat interfce
2) PE RIB group
set routing-options interface-routes rib-group inet inet0_VPNA
static route CE-NAT-PUBLUC/32 next-table VPNA.inet.0 <— this is for the return traffic !!!!
rib-groups inet0_VPNA import-rib [ inet.0 VPNA.inet.0 ] <– copy inet.0 into VPNA table
import-policy SELECT-ROUTES <– policy states which routes to accept // optional
set policy-options policy-statement SELECT-ROUTES term CORE-INTERFACES from interface ge-0/0/0.0 then accept
term DEFAULT-ROUTE from route-filter 0.0.0.0/0 exact then accept
term REJECT-OTHER then reject
send_VPNA term 1 from protocol static
route-filter CE-NAT-PUBLUC/32 exact
then accept
set protocols bgp group GW type internal
export send_VPNA <– GW route needs to know where to return traffic to CE
neighbor IP-GW famil inet unicast rib-group inet0_VPNA <—- needed to accept the default route !!!!
show route 0/0 exact -> in inet.0 and VPNA.inet.0 !!!
show route table VPNA.inet.0
show route CE-NAT-PUBLIC exact –> it should point to table VPNA.inet.0 !!!
show route advertising-protocol bgp GW-IP -> we need to send CE-NAT-PUBLUC to GW
bgp CE-NAT-PUBLIC -> we need to send default and other VPN routes to CE1
Inter-AS Layer 3 VPNs (similar to the l2vpn)
how asbr communicate?: labesl travel between AS? exchange labels? each SP runs its own IGP, how PEs between ASn discover them
Solutions:
Option A: each SP treats each other as a CPE -> each ASBR is configured wtih all VRFs and logical interfaces. No MPLS between both ASBRs
easy but doesnt scale well (for ASBR many VRFs!). Best options when two SPs engaged
Option B: ASBRs exchange VPN labels using eBGP. No LSPs between ASBRs! No VRFS in ASBR! Best option when merging SPs
scale bettern than optionA, easy if you want to talk mpls between SPs. but ASBRs must learn all VPN labels and generate new one (big LFIB)
Option C: PEs between SPs talk eBGP VPN -> SPs needs to know Lo from the other + LSP between SPs -> use BGP-LU: adv IPs with mpls label (transp)
ASBRs talk BPL-LU to exchange labels for each other infra lo’s => end to end LSP between PEs (LSP in SP1 + BGP-LU LSP + LSP in SP2)
-> 3-label stack (outer transport for SPx,
middle bgp-lu label
inner vpn label)
good: no VRFs and no big LFIB in ASBRs
bad: complex. big label stack, RR more difficutl even.
Config: 3 BGPs: PE1-ASBR1 ibgp LU
ASBR1-ASBR2 ebgp LU
PE1-PE2 ebgp inet-vpn unicast
SP1-PE1
set routing-instances L3VPN1 instance-type vrf, rd, rt, inteface, vrf-table-label
set protocols bgp group INT type internal
local-address SP1-PE1-Lo
family inet labeled-unicast resolve-vpn -> copy bgp-lu prefixes from inet.0 into inet.3
neighbor SP1-ASBR1-lo
group EXT type external
multihop
local-address SP1-PE1-lo
family inet-vpn unicat
peer-as SP2
neighbor SP2-PE2-lo
show route received-protocol bgp SP1-ASBR1-lo -> you will see SP2-PE2 lo in inet.0 (by bgp-lu) and copied to inet.3
show route table L3VPN1.inet.0 -> you will see 3 label stack to SP2-CE2 /24
SP1-ASBR1
set protocols bgp group INT type internal –> NO NEED NH-self, because when new label is generated, nh is updated automatically
local-address SP1-ASBR1-lo
family-inet labeled-unicast
neighbor SP1-PE1-lo
group EXT type external
family inet labeles-unicast
export INTERNALS (redistribute SP1 lo to SP2-ASBR2)
peer-as SP2
neighbor SP2-ASBR2-phy
mpls traffic-engineering mpls-forwarding !!!! Important: copy LSP from inet.3 to inet.0 BUT LSP only for fw, IGP for CP.
inteface all
Carrier-of-Carriers VPNs (similar to l2vpn) = LAB!
SP1 in two locations (different ASNs!) but not connection. SP2 is used to connect those two locations from SP1, SP2=COC-SP
You can use l2vpn psedowire -> not scale
Use CoC – Carrier-of-Carrier model -> similar to Option-C (BGP-LU). COC-ASBR will learn SP1 PEs-lo. BGP-LU between PEs and ASBRs
bgp: new things you have to add to the already BGP config in place. There is ibgp inet-vpn unicast already in COC between ASBRs
sp1-pe1 <> sp1-asbr1: ibgp-lu
sp1-asbr1 <> coc-asbr1: ebgp-lu
coc-asbr1 <> coc-asbr2: ibgp-lu
coc-asbr2 <> sp1-asbr2: ebgp-lu
sp1-asbr2 <> sp1-pe2: ibgp-lu
sp1-pe1 <> sp1-pe2: ebgp-inet-vpn !!
lsp:
sp1-pe1 <> sp1-asbr1
coc-asbr1 <> coc-asbr2
sp1-asbr2 <> sp1-pe2
SP1-PE1
set routing-instances L3VPN1 instance-type vrf, interface, rd, rt, vrt-table-label
set protocols bgp group TO-SITE2 type external (to sp1-pe2)
multihop
local-address SP1-PE1-lo
family inet-vpn unicast
peer-as SP1-SITE2
neighbor SP1-PE2-Lo
INT type internal
local-address SP1-PE1-lo
family inet labeled-unicast resolve-vpn !!! -> copy bgp-lu prefixes from inet.0 into inet.3 for vpn resolution
neighbor SP1-ASBR1-lo
show route receive-protocol bgp SP1-ASBR1-lo -> inet.0 (learnt via bgp-lu) then copied to inet.3 (resolve-vpn!)
SP1-PE2-lo -> in L3VPN1.inet.0 you will see COC ASN!
table L3VPN1.inet.0 -> you can see 3-label stack
SP1-ASBR1
set protocols bgp group TO-COC type external
family inet labeled-unicast
export SP1-SITE1-LO !!!!!!!!!! (just advertise all PEx-lo from SITE1 of SP1)
peer-as COC-ASN
neighbor COC-ASBR1-phy
INT type internal
local-address SP1-ASBR1-lo
family inet labeled-unicast
neighbor SP1-PE1-lo
COC-ASBR1
set protocols bgp group TO-SP1-SITE1 type external
family inet labeled-unicast
peer-as SP1-SITE1-ASN
neighbor SP1-ASRB1-phy
INT type internal
local-address COC-ASBR1-lo
family inet labeled-unicast
neighbor COC-ASBR2-lo
** real-life: COC will have this config in a L3VPN !!! This example SP1 prefixes will be in COC inet.0 !!!!
** lab uses “advertise-inactive” in all “type external + bgp-lu” bgp groups???
Troubleshooting Layer 3 VPN – Overview
CP: PE-CE routing, BGP, label protocols
show route table VPN.inet.0 [protocol bgp hidden detail]
show bgp summary | neigbor CE-IP
show route advertising/receive-protocol bgp CE-IP
- bgp default policies: bgp routes from remote PEs are advertisd to CEs. Export policies are needed for redistributing between instances
” CE in same AS as PE -> as-override
ospf; use domain-id to redistribute vpn routes as type3 instead of type5. Sham-links
- ospf default policy: export policy is needed
show ospf database instance VPN1 advertising-router self
lsa-id IP detail
DP: ping/traceroute
Additional Layer 3 VPN Troubleshooting + LAB
MPLS
show route table inet.3 -> each PE.lo must be here. If using bgp-lu needs to use “resolve-vpn”. Maybe “traffic-enginnering mpls-forwarding” is needed too.
show rsvp interface/session/statistics
show ldp interface/neighbor/session/statistics/database
show mpls lsp
BGP
show bgp summary | neighbor PE
show route table bgp.l3vpn.0 [community target:x:y]
show route receive/advertised-routes bgp PE [hidden]
show route table inet.3 [NH from hidden route] -> check if LSP to PE is up!
unknown RT are discarded
** RR must have BGP NH in inet.3 (set routing-optios resolution rib bgp.l3vpn.0 resolution-ribs inet.0
DP
PE-CE: ping/traceroute in routing-instance, show arp
PE-PE: ping/traceroute mpls ldp|rsvp|segment-routing LSP_NAME
ping mpls l3vpn VRF prefix xxxx/x [sweep]= find path MTU
Multicast Overview
QoS is hard. Mostly for UDP
DR: designated router
IGMP: receiver and local router
PIM: between routers
Any source multicast
SSM source-specific multicast
Dense M vs Sparse Mode
Source-Tree = Shortest-path tree (S,G)
Shared-Tree or RP (rendezvous point) tree = (*,G) receiver to RP is shared-tree
224/4 (class D: 1110 )
224.0.0.x/24 local net
232.x.x.x/8 SSM block
233.(0-251).x.x GLOP based on ASN gives you an /24s
234/8 – public multicast
239/8 – private ips
RPF check: uses inet.0, successful checks saved in inet.1. inet.2 alternate table for RFP checks (needs RIB groups)
Introduction to IGMP (host <> routers)
host sends IGMP report to signal interest in receiving specific multicat traffic. IGMP not routing protocol!
router sends IGMP queries to check there is interest
igmp v2: asm + explicit leave so router knows if stop sending traffic. router querier = lowest IP
igmp v3: v2 + supports ssm
Multicast Routing Protocols
perfrom RPF check, build outgoing-interface-list (OIL), exchange multicast fw state with other routers
dense (implicit join, (S,G) = source-tree)
sparse (explicit join, use RP for source discovery or use SSM (igm3 needed), (*,G) intiallu to RP (suboptimal) then move to (S,G)
v2: own protocol
messages:
hello: maintein and discover neighbor (224.13), elect DR (highest priority, highest IP is tiebraker)
join/prune
graft-ack (dense): indicate interest in receiving traffic on previously pruned interfaces
assert: elect DW, shortest distance to the src
register (sparse) signaling between source router and RP
bootstrap and candidate-RP advert (sparse)
BGP MVPN Overview – rfc 6513 (Messy !!!!!)
two methods: dual PIM MVPNs (draft rosen – scale issues) or BGP MVPNs (doesnt require multicast config in backbone)
BGP MVPN: replaces PIM with BGP: rfc 6514 for mvpn signaling. can use a RR. PMSI = P-Multcast Service Inteface
PMSI: tunel PE to PE to transport multicast (rsvp p2mp lsp, mldp)
I-PMSI: (Inclusive) multidirectional: all PEs can transmit to all other PEs
unidirectional: one particular PE to transmit multicast to other PEs
S-PMSI: (Selective) one particular PE to transmit to a subset of PEs
NLRI: af1=1, safi=5 tables: bgp.mvpn.0 and .mvpn.0. PMSI Attribute: rsvp session id or ldp p2mp fec for p2mp lsps (and labels)
type1: Intra-AS I-PMSI autodiscovery route. Sent by all PE routers participating in MVPN
type2: Inter-AS I-PMSU autodiscovery route. Sent by ASBR participating in MVPN.
typex:PE-RD:PE-lo
typ3: S-PMSI autodiscovery route: advertised by multicast source PE in response to receiving a typ6/7 route. (sent by root PE when creating S-PMSI)
3:PE-RD:C-S Mask: C-S S-PMSI: C-G mask: C-G S-PMSI: PE-lo
type4: leaf autodiscovery route: originated by receiver PE in response to receiving typ3 (sent by receiver PE, to join S-PMSI)
4: typ3 : pe-lo
type5: source active autodiscovery route: sent by PE that discovers an active MC source (propagate info on active sources)
5:PE-RD:c-s mask:C-S:C-G mask:C-G
typ6: shared-tree route: sent by PE that receives PIM join (C-, C-G) on the vrf interface. (equivalent PIM join (,G)
6:upstream-PE-RD:ASN-upstream-PE:C-RP mask: C-RP IP: C-G mask: C-G
type7: source-tree join route: sent by PE that receives PIM join (C-S, C-G) on vrf interface (equivalent PIM join (S,G)
7:upstream-PE-RD:ASN-upstream-PE:C-S mask:C-S:C-G mask:C-G
p2mp lsp:
inclusive tree: each tree serves one MVPN. ineficient
selective tree: servers selected MC groups from a given MPVN
I-PMSI signaling:
C-DR: customer DR (a CE)
C-RP: customer RP (a PE)
RSVP.No PIM in Backbone.
With no receivers or source active, each PE:
advertises an inclusive MPVN A-D route to each other tagged with a route target and PMSI tunnel attribute (type1)
uses rsvp PMSI automatically builds a P2MP LSP to other PEs with itself as root and no PHP
uses incoming MPLS label encapsulating the MC packets
a p2mp lsp is signaled with a label-3 (explicit null) oin the penultime hop. A virtual tunnel interface or vrf-table-label must be configured
source begins sending MC traffic
C-DR sends PIM register to C-RP
C-RP sends type5 to remote PEs
using igmpv3, receivers join a source-specific group (other side of the SP network)
Receiver CEs send PIM (S,G) upstream to PEs. Those PEs convert PIM into type7 sent to C-RP
C-RP converts type7 into PIM S,G and sends to C-DR
after MC fw tree is built, C-DR sends native MC to C-RP. C-RP encapsulates packet. At some point one P, duplicates packet to interested PEs.
S-PMSI signaling: complex!!!
RSVP and LDP examples
hw requirements. Tunnel services on certain routers: C-DR, C-RP, all PEs participating in customers MC network
- this can be avoided using vrf-table-label
set chassis fpc1 pic0 tunnel-services bandwidth 1g
Configuring BGP MVPNs + LAB !!!
set protocols bgp family inet-mvpn signallng
set protocos mpls label-switched-path mvpn-example template, no-cspf, link-protection, p2mp
—
RSVP
I-PMSI (required)
set routing-instances mc-pe provider-tunnel rsvp-te label-switched-path-template mvpn-example
vrf-table-label -> disable PHP !!
S-PMSI
set routing-instances mc-pe provider-tunnel selective group 224.7.7.0/24 wilcard-source rsvp-te label-switched-path default-template
LDP
set protocols ldp interface ge-0/0/0.0
p2mp !!!
I-PMSI (required)
set routing-instances mc-pe provider-tunnel ldp-p2mp
vrf-table-label
S-PMSI
set routing-instances mc-pe provider-tunnel selective group 224.7.7.7/32 source lo-ip/32 ldp-p2mp
set routing-instances mc-pe protocols pim rp local address LO
interface alll mode sparse
mvpn mvpn-mode [spt-only | rpt-spt ]
verification
1- PIM customer domain
show pim interface|join|source|statistics
show mvpn c-multcast instance-name VPN_NAME extensive
2- BGP family MVPN
show route table VPN.mvpn.0 -> check for type1,2,3,4,5,6,7
show pim join instance mc-pe extensive
show multicast route instance mc-pe extensive
show route forwarding-table destination 224.7.7.7 exntensive (label and inteface outout should be the same as above command(
show route table bgp.mvpn.0
3- I-PMSI/S-PMSI for RSVP/LDP p2mp
show rsvp session
show ldp database