It is really humbling how three people started all this on their own. We capable of horrible things but as well, amazing things. So maybe your effort is just a drop of water but it can add up.
I had no idea about the deforestation mafia of Red Kehmr in Cambodia and how that financed the war. And worst, how both sides were profiting from it. As always, the population is the one that pays the consequences.
That follows the diamonds from Angola, the petrol from Guinea, the wars of Siorra Leone and Liberia, etc.
I think of several countries as corrupted, but as the book shows, it is the first work with the financial engineering and PR/Law firms that allow all the mone to be moved away from those countries
If we dont allow those people to buy property, ferraris, etc it would be less convenient…. and make all the companies accountable.
At the end of the day, while fiscal paradise exists, this will continue, but at least there are people like GW that will pull the carpet and show the ugliness…
I have been quite surprised by this book. It is based on the psychology work from Alfred Adler. And i take it more as philosophy than anything else.
It is based on teleology: the study of the purpose of a given phenomenon, instead of its cause (that is aetiology). We determine our own lives according to the meaning we give to those past experiences. So it negates the influence of the past and traumas. The important thing is not what one is born with, but what use one makes of that equipment. We need the courage to be happy, because that needs change (the lifestyle), and it is scary. As well, this makes you to focus in the present.
All problems are interpersonal relationship problems. Personally, I feel my goal is not to be hurt in relationships with other people. But it is impossible not to get hurt (or hurt somebody).
Feelings of inferiority are subjective assumptions (and excuses), and those we can change it. Boasting is an inverted feeling of inferiority. If one really has confidence, one doesnt need to boast.
Life is not a competition (winner vs looser) and this applies to Relationships too. This make you see people as comrades. Only compare with your ideal self. You are the only one worrying about your appearance. When there is competition, there is a power struggle. Avoid the conflict as soon as possible, dont answer the action with a reaction (this is not admitting defeat though), because this evolves to a revenge.
Our objectives are: self-reliant (I have the ability) and live in harmony with society (people are my comrades). Our life tasks are: tasks of work, frienship and love
Life lie = I am making up flaws in other people just so that I can avoid my life tasks, and more, I can avoid interpersonal relationships -> courage.
As we have our tasks, the other have their tasks. As we focus in our task, looking for recognition is debilitating, it creates a dependency, a vertical relationship (you want horizontal relationship). Do not live to satisfy the expectations of others. This means freedom. Freedom to be disliked by other people. The same way, you dont have to praise or debuke. Saying “Thank you” is good enough
This leads to the goal of interpersonal relationships, that is the feeling of community. This is acquired by your own efforts, active commitment.
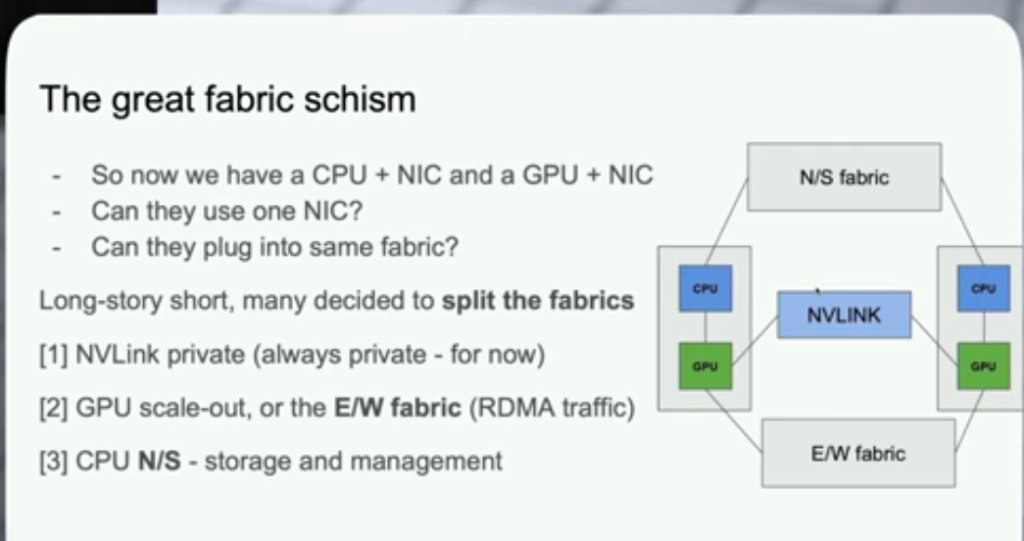
1) Network Topology: backend network only for GPUs (RDMA nics), non-blocking. Frontend network: data ingestion, checkpointing, logging.
Pod = AI zone
leaf = RTSW, DAC cables, shallow buffer
spine = CTSW, deep buffers. fiber between leaf-spine.
SuperSpine = ATSW, oversubscribed, connect AI zones
intra-node -> nvlink
ROCE: cpu offloading, ethernet (standard)
collective communication library serves as the sw abstraction between training workloads and the NIC
schedules verbs calls over QP (Queue Pairs)
parallelism strategy determines collective: allreduce, allgather, alltoall
choice logical topology:
------------------
2) Routing: work load. low entropy flows (few flows) -> ECMP bad (5-tuple udp: src/dst ip, src/dst port, protocol), burstiness, elephant flows
--
RTSW uplinks 1:2 under-subscribed! -> expensive (short-term)
1) QP scaling: use destination QP of Roce packet using the UDF capability in switch to increase entropy -> Enhanced ECMP -> short-term
2) Central TE controller -> long-term: CP real-time topology end-to-end cluster,
flow matrix (flow bps) + CSPF (constrained SPF)
write in switches dataplane
DP: TE overrides default BGP routing policy in leaf. Use Exact Match table.
Not good with multiple link failures. Doesnt scale
3) Flowlet switching: try to improve 1 and 2. hw assistant schema. put packets in different ports in ECMP
out-of-order: move packets only after 1/2 RTT
load-aware path assignment: better than TE
------------------
3) Transport: congestion management. Start with DCQCN. packet drops on ACK/NACK can cause prolonged Local ACK timeout (LAT)
--
Tuning DCQCN not great (strict ECN -> minimize PFC (can lead to head-of-line blocking)
200G, we stayed with relaxed ECN marking, allowing for buffer build up in the CTSW, while keeping default DCQCN settings.
400G We proceeded without DCQCN. just PFC for flow control
re-design collective library: two-stage copy
------------------
4) Operations:
Change QoS priority of Clear to Send (CTS) messages. In RTSW ASIC, modify dsCP marking for ACK messages
Tuning VOQ in CTSW
obeservability: OOS: out of seq.
Link flaps
Local ACK timeouts (LAT)
PFC watchdog: catch any long-duration PFC pause (>200ms)
buffer utilization RTSW
reachibility (pings)
constant latency monitoring loaded and unloaded (catch regressions)
base lines!!!
AWS RNG – Random Graph Network: The paper is totally out of my space, but the concept looks brutal. With an operations hat, how you troubleshot it? (ping, traceroute, link congestion, data flows patterns, etc)
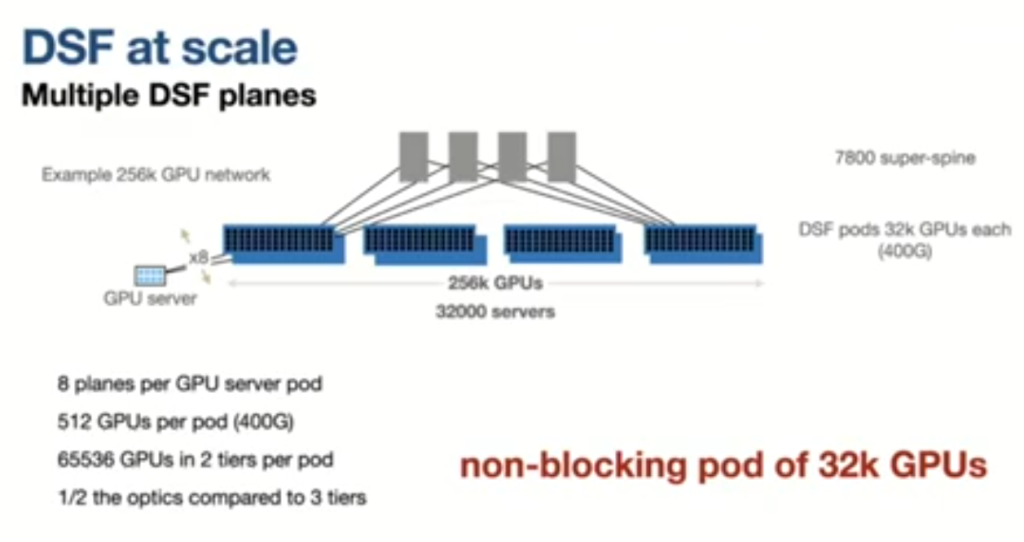
MRC1 and MRC2 (OCI): Why we need planes (breakouts) and not just a big plane.
As SerDes speeds continue increasing, every microsecond of congestion creates much larger pressure inside the fabric. A 100G transport domain may be manageable. A 400G domain amplifies the same congestion into roughly 4x pressure. An 800G domain, and eventually a 1.6T domain, becomes much harder to coordinate.
This pressure appears as larger switch buffer requirements, larger congestion domains, harder retransmission coordination, larger cache pressure, larger synchronization storms, and harder thermal and power scaling inside ASICs.
At hyperscale, switch ASIC cache and transport coordination become fundamental scaling bottlenecks. Increasing switch buffer size is extremely difficult: high-speed SRAM is expensive, larger cache arrays consume significant power, thermal density rises quickly, die area scaling becomes inefficient, and routing complexity increases dramatically.
Splitting transport into many smaller lanes naturally reduces these pressures. Reliability improvements then emerge as a byproduct, because congestion, retransmission, and buffering become more distributed.
THE QUESTION: which breakout keeps the fabric at the shallowest practical Clos depth while keeping plane count and operations manageable? -> less hops, less switches, less latency
Slurm Workload Manager (short for Simple Linux Utility for Resource Management) has become a cornerstone of large-scale computing. Originally created in the early 2000s to support large-scale high-performance computing (HPC) environments, Slurm is now widely recognized as the de facto scheduler for HPC clusters. Today, it orchestrates jobs across thousands of servers and GPUs in some of the world’s most advanced computing environments.
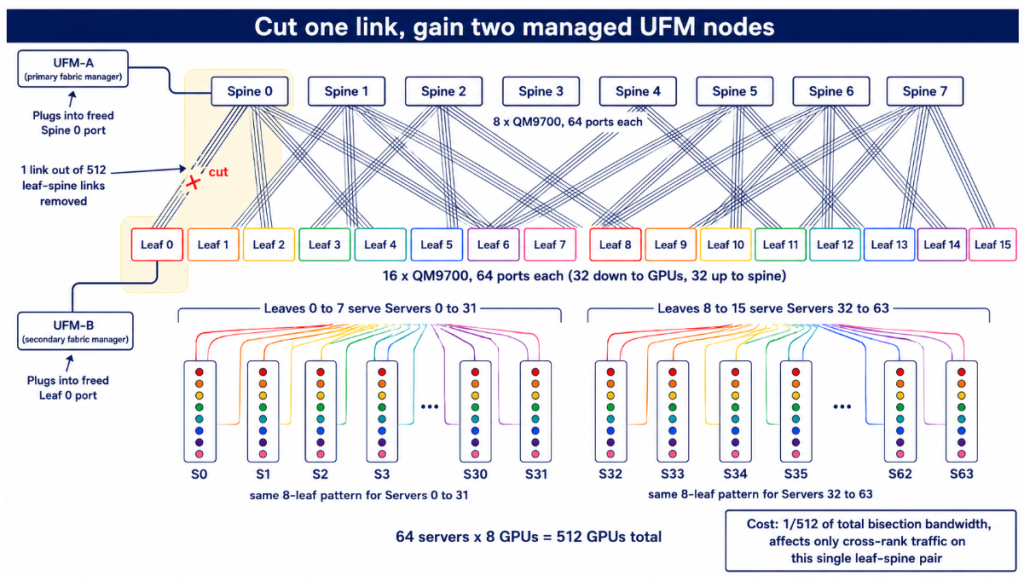
Interview Question: 512 GPU, non-blocking (full bisection) and 2xUFM! I really liked this. I think for once I understand the rail-optimize (fat-tree = leaf-spine). Just break one leaf-spine link, beautiful!!!
800VDC: Next step in electrical infra in DC space.
Very interesting book. In Western Work we know a lot about Roman Empire, Alexander the Great, etc. But we dont look very often to Asia. And Gengish Khan and the following Mongol empires shaped much of the world society on the time and until know.
He was focused in meritocracy. As part of his war strategy, it was the elimination of the aristocracy of the conquered land. Very strong focus in integration. They never imposed their culture, they had full freedom for religious belief. They were brutal in war but never cruel. Torture was common in Europe and other empires, for them, it was against their belief.
They had a very clear war strategy: light travel, fast striking. They had few luggage and basic diet. They cleared the path for their horses for advancing and returning. So they destroyed and agriculture over their conquering paths.
It is interesting how Genghis Khan crumbled after his death because he didnt manage this family properly. But still, the new kingdoms kept a balance for a long time.
And something that reminded me to Rome, they had to keep expanding the empire just to keep happy the capital…. They introduced the paper money and women ruled when the men were fighting… and their campaigns lasted years!
Trade was critical for Mongols. They reached Hungary and the Balkans. They trade slaves with Venice and Genoa.
The climate was critical for their success, when the weather became warmer, their pastures were less productive in Mongolia, they had less horses, so the base of their strength was tilted.
They were master of propaganda, to spread fear so they conquering was easier. The empire was based on good army, good propaganda and good administration (just think of the sear size of the empire). They founded public education.
Mongols unified China. I didnt know that, they founded Beijing and started Forbidden City. They created the Chinese identity but they followed the mongol customes behind the curtines.
And the end of it was the Plague. The Plague stopped commerce and people. Without the fluid transit of people and goods, they couldnt keep it together.
And it is really shocking the bad reputation that has been written about Mongols after their incredible empire and success.
This is a cake I wanted to try after I visited Greece with my friends. I never had the name of the cake, but after that holidays I did dome research and I think I found the name, portokalopita. I’ve got a receipe, but then I did nothing.
So finally, I tried. The taste is similar but the execution is not great. Mine is too runny.
Ingredients
Syrup
1 1/2 cup orange juice (just squeeze it from oranges…. I didnt do it)
1/2 cup water
1 1/2 cup sugar
1 cinnamon stick
Cake
180g phyllo sheets (I think I need double)
4 eggs
1/2 cup sugar
1 cup olive oil
2 tsp vanilla extract
200g yogurt
2 tsp baking powder
orange zest from 2 medium oragnes.
Instructions
Preheat oven at 120C.
Place the phillo sheets on a tray. Cut them in slices so it easy to fit. Get them in the oven, until hard and crunchy. Turn them over when needed. Remove from oven and let is cool down
Make the syrup. In a small sauce pan mix the orange juice, water, sugar and cinnamon. Bring to boil, then reduce heat and simmer for 7 minutes. Set aside to cool
Set oven at 180C
In a large bowl add the eggs, sugar, oil and vanilla. Beat until frothy.
In a smaller bowl, mix the yogurt and baking powderand set aside for 2-3 minutes. Add the yogurt to the egg mix
Add the orange zest and crumbled phyllo into the egg mix gradually.
Grease an oven dish, and pour the cake mix. Even it out
Bake for 35-40 minutes or until the top is dark golden.
Remove from oven and make a few slashes with a knife and immediately drizzle the syrup slowly.
Let the cake sit for 2-3 hours.
Keep in the fridge for 1h before serving.
The result:
I think the syrup is too much and I my cake mix needed more phyllo
This is a tiny book I found in a toilet during holidays a couple of years ago. I bought a while ago and can’t find it anymore, this is one from the same author.
Fall in love (only when you can’t help it)
Dont forget that there are always consequences
When you get bucked off, get back on
Skin you own deer
If it breaks, fix it.
Never cut, what you can untie
If you make a mess, clean it up
Talk less and say more
Never betray a Trust
Make apologies, not excuses
Don’t get even, get over it
Dont waste good money on cheap boots
Help what you can; endure what you can’t
Do it Today, tomorrow is promised to no one.
Never miss a chance to Dance
Act right, behave yourself, do your job, and things will turn out all right
Take care of your knees; you are going to need them all your life
NVIDIA releases MRC: Multipath Reliable Connection – I assume they need to do something to compete with UltraEthernet
OSPF shutdown router: I would have test this. In my opinion, the key thing is although the router LSA1 is in the neighbors LSDB, SPF is ignoring it. Still quite interesting, you always learn/re-learn something.
Mark Manson – 10y therapy: I like the very beginning and then when Chris says you have to through shit to understand those rules and appreciate them.
JEPA (Joint Embedding Predictive Architecture): LeCun against LLM. Proof.
Interesting book about the “start” of quant trading by Jim Simons. Funny he was a strong smoker and quick sharp and active till the end, great Mathematician and was code breaker! I didnt know anything about Renaissance. In part, it reminds me the book from Edward O. Thorp. It was weird that with so much tech and algorithms developed, in key moments, he didnt trust them. Reminds me to Nassim Taleb and the dark swans. Still he was never crashed and always made money. I always feel uneasy with this subject. Is it moral? The thing that surprise the most was the connections with Donald Trump by members of his company and Brexit election. But he supports and finance Democrats.
Eat the peel: After reading this, I started eating the kiwi’s peel. Not going back. I would like to do something with banana peels and oranges. But dont want to use a tone of sugar neither. I will try my spicy banana bread next time with peel. The orange peels you can keep it as aromatic when dried.
Virginia Air Space Museum: I was there 3 years ago I think. Amazing. You have a blackbird SR71, Concorde, Space Shuttle, etc. Totally worth visiting.
Fairwater: This is already old news in the AI datacenter world. But still interesting at high level.
Microfluidics: “Tiny channels are etched directly on the back of the silicon chip, creating grooves that allow cooling liquid to flow directly onto the chip and more efficiently remove heat”.
The process works in three stages. First, air is taken in from the surroundings and cleaned. Second, the air is repeatedly compressed until it is at very high pressure. Third, the air is cooled until it becomes liquid, using a multi-stream heat exchanger: a device that includes multiple channels and tubes carrying substances at different temperatures, allowing heat to be transferred between them in a controlled way.
“The energy that we’re pulling from the grid is powering this charging process,” says Cetegen.
When the grid needs extra energy, the liquid air is put to work. It is pumped out of storage and evaporated, becoming a gas again. It is then used to drive turbines, generating electricity for the grid. Afterwards, the air is released back into the atmosphere.
Infinibad HPC: This is a good intro for infiniband, it helped me to refresh the training I did two years ago
Designing HPC Cluster Infinibad: It seems more practicas as you have the different type of deployments based on required nodes. Avoid credit loops.
Do you want to be helped? – What’s this really about? Decision Making mindset. Lean into data and reasoning
What does everyone want? How will we make choices together?
How to figure out what this is really about? First, recognize that this is a negotiation. Next determine what does everyone want? Then how will we make choices together?
Do you want to be hugged? – How do we feel? Emotional mindset. Lean into stories and compassion
In a conflict, we learn why are fighting by discussing emotions.
In a conflict, we draw out emotions by proving we are listening.
In a conflict, we prove we are listening by looping for understanding: ask questions, summarize what you heard, ask if you got it right.
In a conflict, focus in controlling:
Yourself
Your environment
The conflict boundaries
Check mood and energy!
Do you want to be heard? – Who are we? Social mindset
We all posses social identities that shape how we speak and hear.
how to talk about who we are:
Draw out multiple identities
Put everyone on equal footing
Create a new group by building on existing identities
Be aware of this loop:
Telling someone they belong to a group they abhor -> triggers identity threat -> causes defensiveness -> prompts counter-attacks -> leads to telling someone they belong to a group they abhor -> loop
Before discussion:
What do you hope to accomplish?
How will this conversation start?
What obstacles might emerge?
When those obstacles appear, what’s the plan?
What are the benefits of this dialogue?
Rules:
Pay attention to what kind of conversation is occurring (above)
Share your goals, and ask what others are seeking: prepare for the conversation. Ask many questions!
Ask about others’ feelings, and share your own
Explore if identities are important to this discussion.
The examples of “The Big Bang Theory” (how do you hear emotions no one says aloud?,) the court case, guns ownership, anti-vax, COVID, football team, netflix (no-rules), etc are really good.