Cloudflare backbone 2024: Everything very high level. 500% backbone capacity increase since 2021. Use of MPLS + SR-TE. Would be interesting to see how the operate/automate those many PoPs.
Cisco AI: “three of the top four hyperscalers deploying our Ethernet AI fabric” I assume it is Google, Microsoft and Meta? AWS is the forth and biggest.
Huawei Cloud Monitor: Haven’t read the paper RD-Probe. I would expect a git repo with the code 🙂 And refers to AWS pdf and video.
Automated Leetcode: One day, I should have time to use it a learn more programming, although AI can solve them quicker than me 🙂
Alibaba Cloud HPN: linkedin, paper, AIDC material
LLM Traffic Pattern: periodically burst flows, few flows (LB harder)
Sensitive to failures: GPU, link, switch, etc
Limitations of Traditional Clos: ECMP (hash polarization) and SPOF in TORs
HPN goals:
-Scalability: up to 100k GPU
-Performance: low latency (minimum amount of hops) and maximum network utilization
-Reliability: Use two TORs with LACP from the host.
Tier1
– Use single-chip switch 51.2Tbps. They are more reliable. Dual TOR
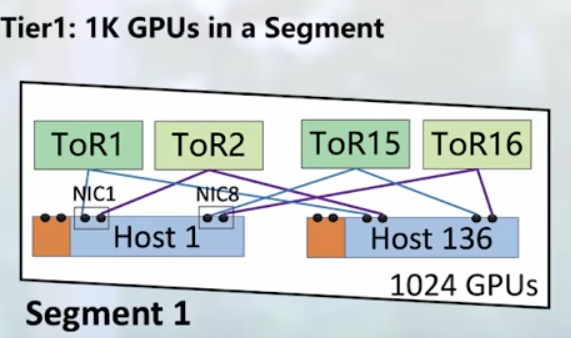
– 1k GPUs in a segment (like nv-link) Rail-optimized network
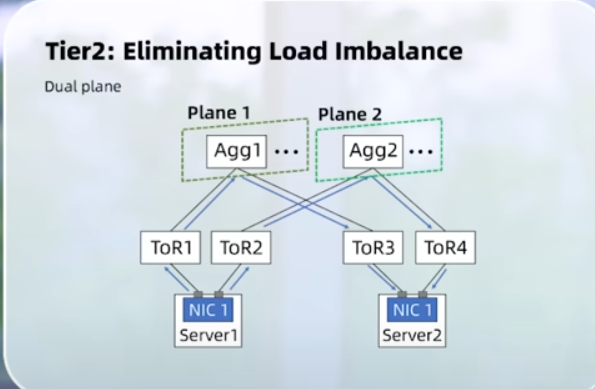
Tier2: Eliminating load imbalance: Using dual plane. It has oversubscription
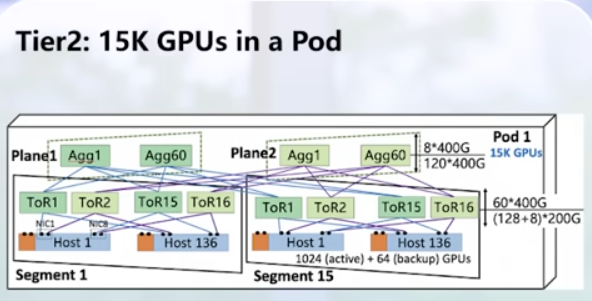
Tier3: connects several pod. Can reach 100k GPUs. Independent front-end network
Altman Universal Base Income Study: It doesnt fixt all problems, but in my opinion, it helps, and it is a good direction.
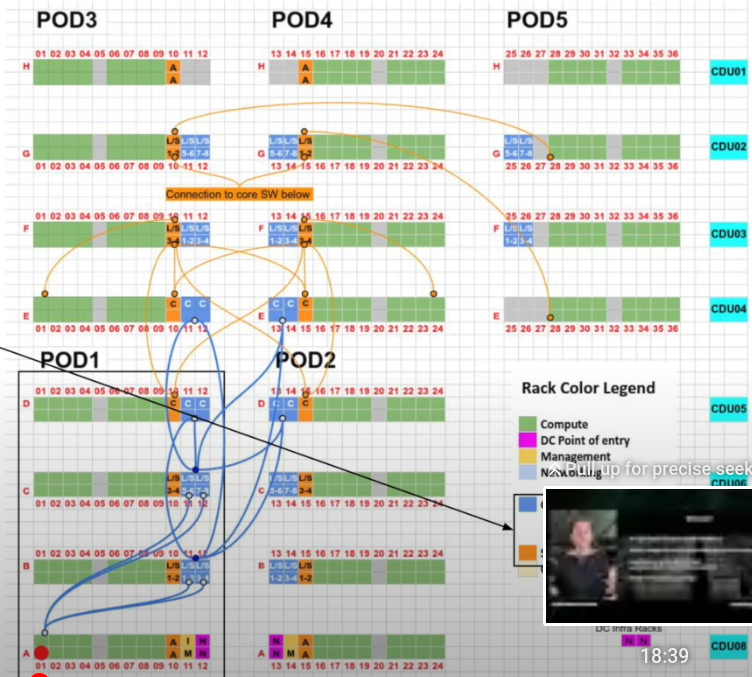
xAI 100k GPU cluster: 100k liquid-cooled H100s on single RDMA fabric. Looks like Supermicro involved for servers and Juniper only front-end network. NVIDIA provides all ethernet switches with Spectrum-4. Very interesting. Confirmation from NVIDIA (Spectrum used = Ethernet). More details with a video.
Github access deleted data: Didn’t know about it. Interesting and scary.
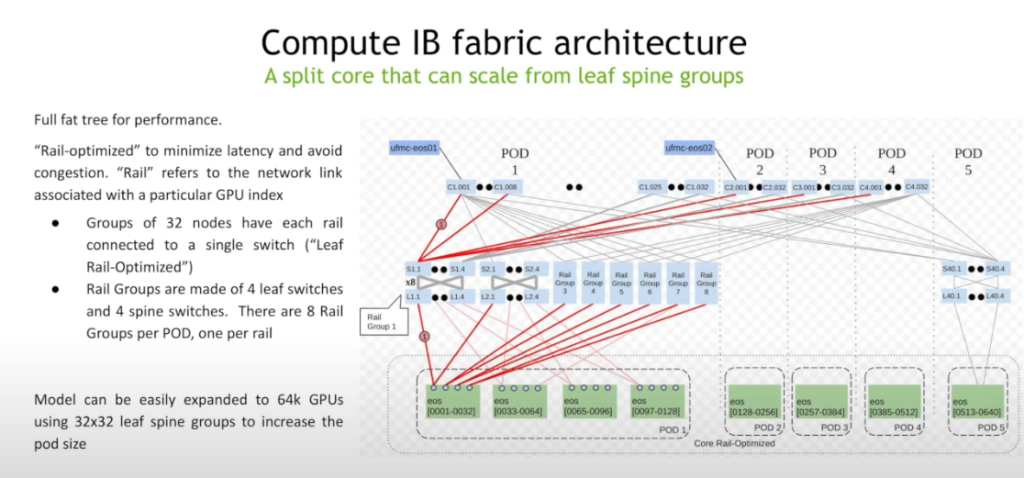
Nvidia DGX SuperPod: reference architecture. video. 1 pod is 16 racks with 4 DGX each (128×8=1024 GPU per pod), 2xIB fabric: compute + storage, fat tree, rail-optimized, liquid cooling. 32k GPU fills a DC.
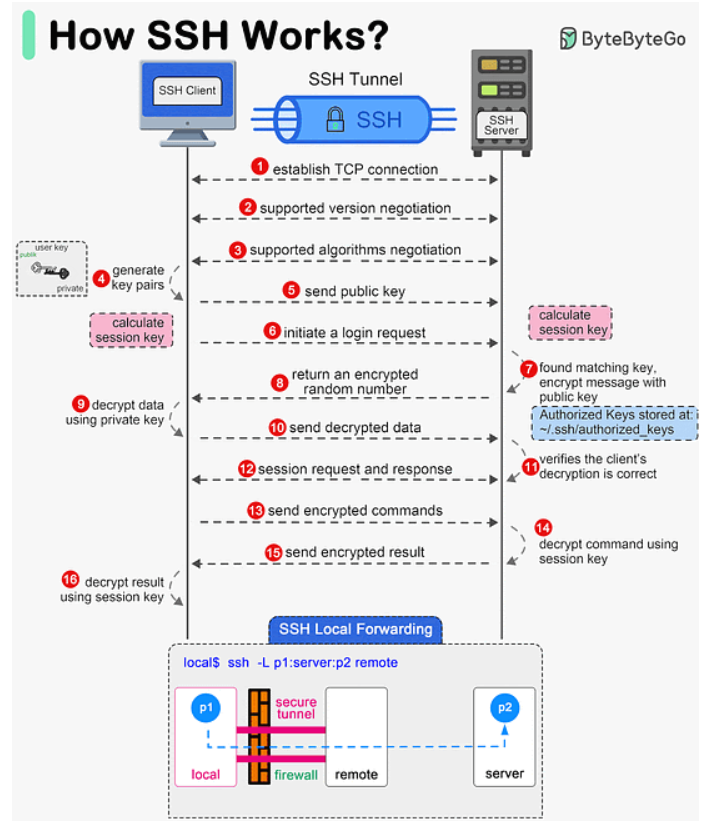
How SSH works: So powerful, and I am still so clueless about it
Chips and Cheese GH200: Nice analysis for Nvidia Grace CPU (ARM Neoverse) and Hopper H100 GPU