Lightmatter: Based on this video, they are using photonics to connect chips, looks interesting, I remember Google has something with optical but for networking. But It is pretty clear this is not photonics computing.
- allreduce: collect elements from all nodes, apply a reduction operator(eg sum) then distribute reduction to all nodes -allgather: collect elements from all nodes, and distribute the to all other nodes - gpu: cpu for parallelization - RDMA: RoCE2 GPU memory to GPU memory - origin in IB - issues: flow collision, trafic polarization. low entropy!!! > dificult to ecmp => Dynamic LB incast: many2one -> ECN + buffering (in spine!) - use chassis!
With an operations hat on, dealing with chassis is expensive and no efficient. It kind of a vendor lock-in. AWS is all in pizza boxes and I remember one presentation in Cisco Live where the Cisco EVPN authority recommended pizza boxes.
This is a pizza that I tried several years ago, and it seems the restaurant is out of business. I have done some pizzas trying to emulate it but never matching that memory. So this is a placeholder to try:
Original Ingredients: Bechamel, Smoked Mozzarella, red onions, pancetta, sliced potatoes, and Buffalo Mozzarella.
...thanks to the coherence IBM already has across NVLink (which is really BlueLink running a slightly different protocol that makes the GPUs think DRAM is really slow but really fat HBM2, in effect, and also makes the CPUs think the HBM2 on the GPUs is really skinny but really fast DRAM).
Checking some wireshark traces last week, I cam across the concept of TCP Conversation Completeness. This was totally new for me. This video gave some idea too. This was useful for me for finding TCP conversation that showed retransmissions when trying to stablish the TCP handshake, and not just showing the retransmission, so I used “tcp.completeness<33” so I should see TCP flows with a sync + RST.
AI developer Kit by NVIDIA: This card looks nice, I would mind to buy it and give a chance to learn, but it is sold out everywhere…. This is a video about it.
python vu: replacement for pip, pyenv, etc. Need to try
InfraHub: As a network engineer interested in Automation. This looks interesting and I would like to go deeper to fully understand as it is the merge of the typical source of truth (DB) that you can’t get in git.
Segment Routing Controller: This is another thing I played with some years ago, but never found a controller to make TE. I dont see clearly this software is OSS but at least doesnt look like is a vendor-lock…
AWS re:Invent 2024 – NET201: The only interesting thing is minute 29 with the usage of hollow core fiber, to improve latency. I assume it is used in very specific parts of the network, looks a bit fragile. Elastic Fabric Adapter, not really good explanation what it is, where doest it run: network, server, nic? but it seems important. Looks like SIDR?
AWS re:Invent 2024 – NET403: I think 401 and 402 were more interesting. There were repeated things from the two other talks. Still worth watching and hopefully there is a new one in 2025.
GenCast: weather predict by Google Mind. Not sure until what point, this can be used by anybody? And how much hardware you need to run it?
we’ve made GenCast an open model and released its code and weights, as we did for our deterministic medium-range global weather forecasting model.
Videos:
510km nonstop – Ross Edgley: I have read several of his books and it is the first time I watch a full interview. Still I am not clear what his dark side is.
Google TPUv6 Analysis: “… cloud infrastructure and which also is being tuned up by Google and Nvidia to run Google’s preferred JAX framework (written in Python) and its XLA cross-platform compiler, which speaks both TPU and GPU fluently.” So I guess this is a cross-compiler for CUDA?
“The A3 Ultra instances will be coming out “later this year,” and they will include Google’s own “Titanium” offload engine paired with Nvidia ConnectX-7 SmartNICs, which will have 3.2 Tb/sec of bandwidth interconnecting GPUs in the cluster using Google’s switching tweaks to RoCE Ethernet.” So again custom ethernet tweaks for RoCE, I hope it makes to the UEC? Not sure I understand having a Titanium offload and a connectx-7, are they not the same?
Alphafold: It is open to be used. Haven’t read properly the license.
OpenAI API key: ********************************************************************************************************************************************************************
Tip: To save this key for later, run one of the following and then restart your terminal. MacOS: echo 'export OPENAI_API_KEY=your_api_key' >> ~/.zshrc Linux: echo 'export OPENAI_API_KEY=your_api_key' >> ~/.bashrc Windows: setx OPENAI_API_KEY your_api_key
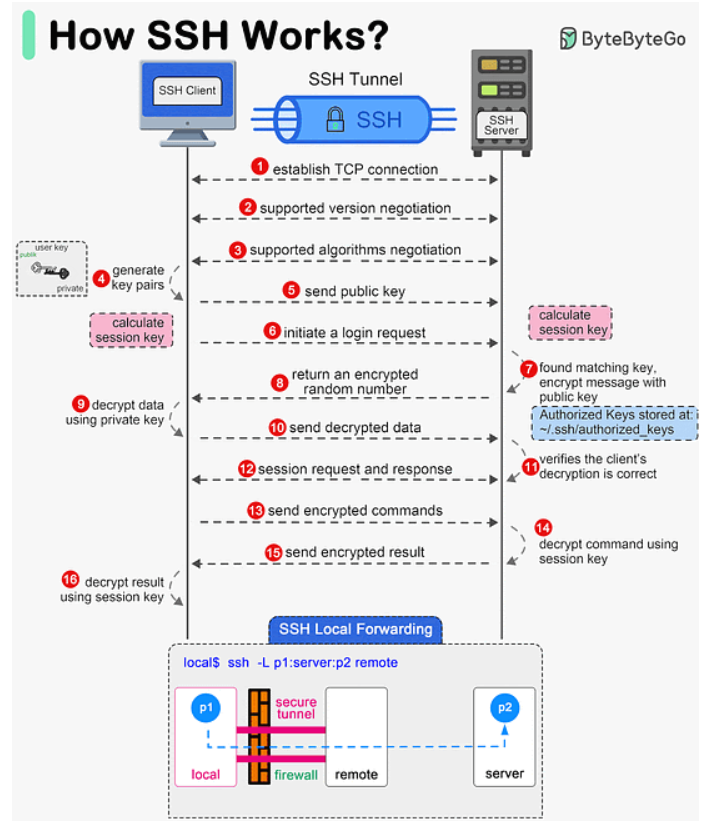
Zero Trust SSH. From Cloudflare. And this video I watched some months ago (and it is already 4y).
Finger Strength: I follow similar protocol, although not everyday, for warm up and I think it works. I am not getting that super results but at least my fingers are stronger…. and I am not getting injuries!!!! \o/
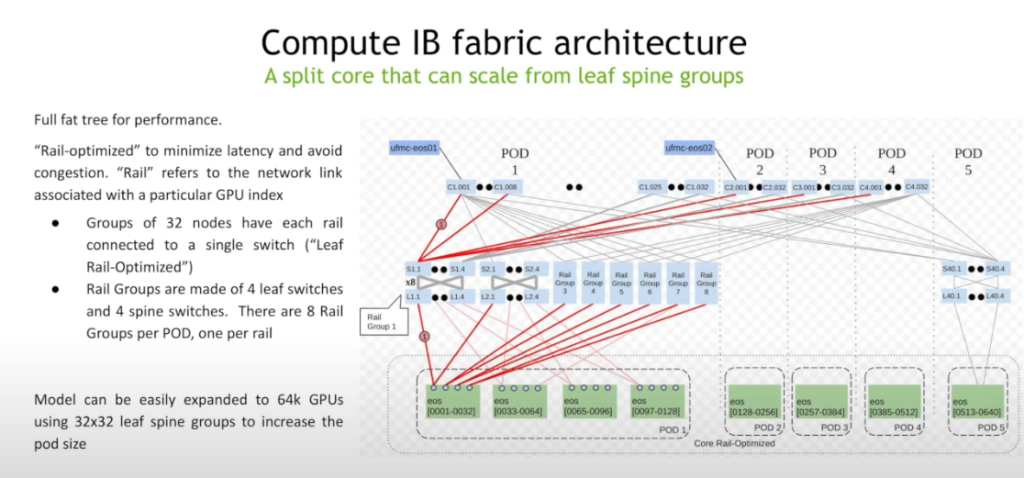
Create different networks (inter-GPU, front-end, storage, mgmt),
Inter-GPU:
– non-blocking, rails-optimized (fig.3)
Inter-GPU challenges:
– Packet loss: Use PFC +ECN (flow aware)
– Network delay: “Rich” QoS – proprietary QoS to handle mice flows. Needs good telemetry
– Network congestion: Some kind of communication switch-NIC
– Non-uniform utilization: Most vendors have something proprietary here, some dynamic LB and static-pinning?
– Simultaneous Elephant flows with large bursts: dynamic buffer protection (proprietary)
Videos:
Raoul Pal: Crypto Investment. His company. Go long run, invest a bit you can lose
Scott Galloway: Interesting his political analysis. Trump won and it seems Latins voted massively for him.
Bruce Dickinson: I read Bruce’s books some years ago so I was surprised to see him in a podcast. Need to finish it.
Eric Schmidt: I read one of his books some time ago so again, surprised to find him in a podcast. Still think Google has become evil and most of the good things he says are gone.
Javier Milei: I am not economist but it “seems” things are improving in Argentina. He is a character nonetheless. Need to finish it.
Matthew McConaughey: His book was really refreshing, and seeing him talking is the same. Raw, real.
Alex Honnold: You have to try hard if you want to do hard things.
This is site that a friend shared with me some months ago. And it is PURE gold from my point of view. They share a lot info free but not all, you have to subscribe/pay for the whole report. I would pay for it if my job were in that “business”
It covers all details for building such infrastructure up to the network/hardware side. So from power distribution, cooling, racking, network design, etc. All is there.
It is something to read slowly to try to digest all the info.
This report for electrical systems (p1) shows the power facilities can be as big as the datacenter itself! So it is not rear to read hyperscalers want nuclear reactors.
It seems Malaysia is getting a DC boom, but it based on coal???
This is a MS NVIDIA GB200 based rack. I am quite impressed with the cooling systems being twice as big as the compute rack! And yes, MS is sticking with IB for AI networking.
I didnt know that Oracle OCI was getting that big in the DC/AI business. And they were related to xAI. Their biggest DC is 800 megwatts… and a new one will have three nuclear reactors??
FuriosaAI: A new AI accelerator in the market. Good: cheap, less power. Bad: memory size.
OCP concrete: Interesting how far can go the OCP consortium.
IBM Mainframe Telum II: You think the mainframes business doesnt exist. Well, it is not. Honestly, at some point, I would like to fully understand the differences between a “standard” CPU and a mainframe CPU.
NotoebookLM: It seems it is possible to make summary of youtube videos! (and free)
EdgeShark: wireshark for containers. This has to be good for troubleshooting
OCP24 Meta AI: It is interesting comparing the Catalina rack with the one from MS above. The MS has the power rack next to it but FB doesnt show it, just mention Orv4 supports 140kW and it is liquid cooled. I assume that will be next to Catalina like MS design. And AMD GPU are getting into the mix with NVIDIA. It mentions Disaggregated Scheduled Fabric (DSF), with more details here. And here from STH more pictures.
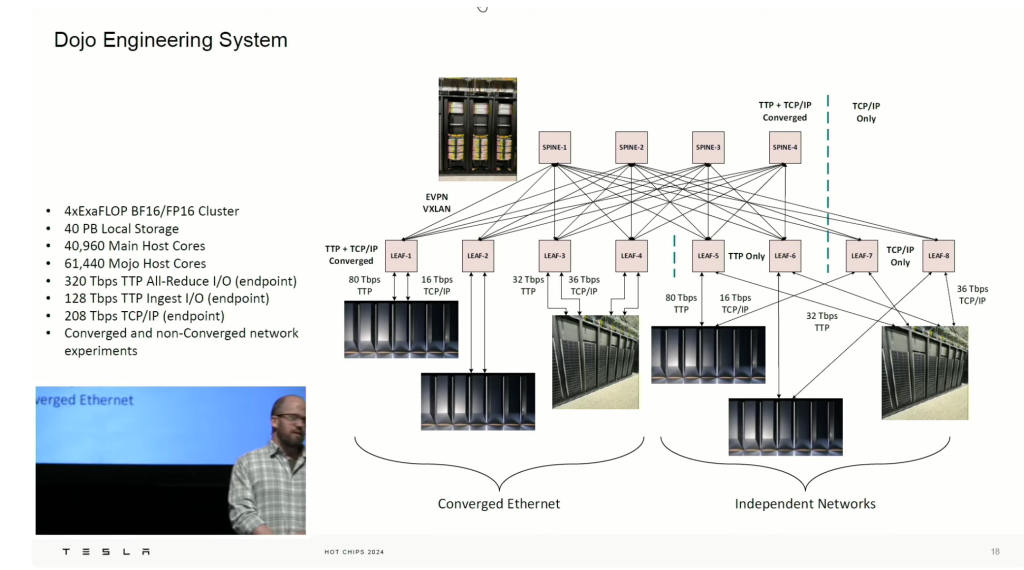
Testa TCP replacement: Instead of buying and spending a lot of money, built what you need. I assume very smart people around and real network engineering taking place.It is like a re-write of TCP but doesnt break it so your switches can still play with it. It seems videos are not available in the hotchips webpage yet. And this link looks even better, even mentions Arista as the switching vendor. (video from hotchips24)
Cerebras Inference: From hotchips 2024. I am still blow away for the waferscale solution. Obviously, the presentation says its product is the best but I wonder, can you install a “standard” linux and run your LLM/Inference that easily?
Leopold AIG race: Via linkedin, then the source. I read the chapter 3 regarding the race to the Trillion-Dollar cluster. It all looks Sci-Fi, but I think it may be not that far from reallity.
Cursor + Sonet: Replacement for copilot? original I haven’t used Copilot but at some point I would like to get into the wagon and try things and decide for myself.
AI AWS Engineering Infra: low-latency and large-scale networking (\o/), energy efficiency, security, AI chips.
NVLink HGX B200: To be honest, I always forger the concept of NVLink and I told my self it is an “in-server” switch to connect all GPUs in a rack. Still this can help:
At a high level, the consortium’s goal (UltraEthernet/ UA) is to develop an open standard alternative to Nvidia’s NVLInk that can be used for intra-server or inter-server high-speed connectivity between GPU/Accelerators to build scale-up AI/HPC systems. The plan is to use AMD’s interconnect (Infinity Fabric) as the baseline for this standard.
Netflix encoding challenges: From encoding per quality of connection, to per-title, to per-shot. Still there are challenges for live streaming. Amazon does already live streaming for sports, have they “solved” the problem? I dont use Netflix or similar but still, the challenges and engineering behind is quite interesting.
Some career advice from AWS: I “get” the point but still you want to be up to speed (at certain level) with new technologies, you dont want to become a dinosaur (ATM, frame-relay, pascal, etc).
Again, it’s not about how much you technically know but how you put into use what you know to generate amazing results for a value chain.
Get the data – be a data-driven nerd if you will – define a problem statement, demonstrate how your solution translates to real value, and fix it.
“Not taking things personally is a superpower.” –James Clear
Because “no” is normal.
Before John Paul DeJoria built his billion-dollar empire with Patrón and hair products, he hustled door-to-door selling encyclopedias. His wisdom shared at Stanford Business School on embracing rejection is pure gold (start clip at 5:06).
You see, life is a numbers game. Today’s winners often got rejected the most (but persevered). They kept taking smart shots on goal and, eventually, broke through.
Cloudflare backbone 2024: Everything very high level. 500% backbone capacity increase since 2021. Use of MPLS + SR-TE. Would be interesting to see how the operate/automate those many PoPs.
Cisco AI: “three of the top four hyperscalers deploying our Ethernet AI fabric” I assume it is Google, Microsoft and Meta? AWS is the forth and biggest.
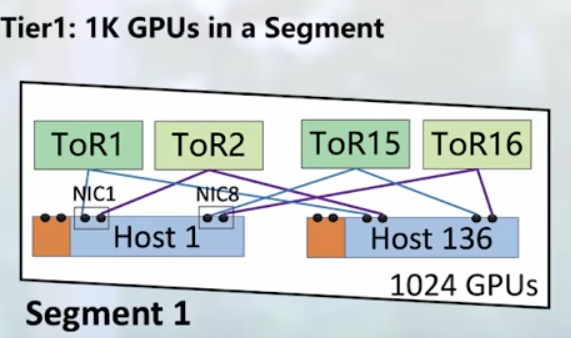
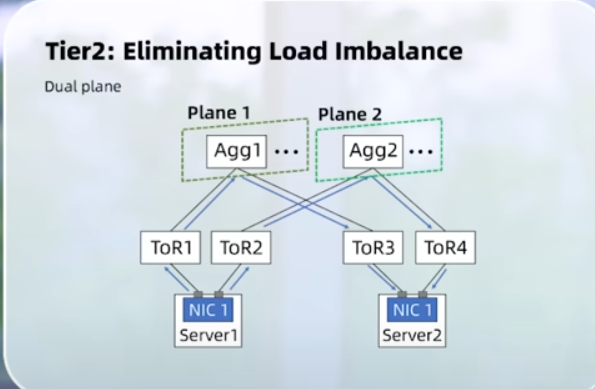
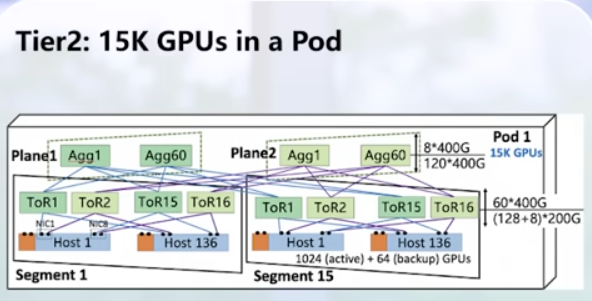
xAI 100k GPU cluster: 100k liquid-cooled H100s on single RDMA fabric. Looks like Supermicro involved for servers and Juniper only front-end network. NVIDIA provides all ethernet switches with Spectrum-4. Very interesting. Confirmation from NVIDIA (Spectrum used = Ethernet). More details with a video.