This is site that a friend shared with me some months ago. And it is PURE gold from my point of view. They share a lot info free but not all, you have to subscribe/pay for the whole report. I would pay for it if my job were in that “business”
It covers all details for building such infrastructure up to the network/hardware side. So from power distribution, cooling, racking, network design, etc. All is there.
It is something to read slowly to try to digest all the info.
This report for electrical systems (p1) shows the power facilities can be as big as the datacenter itself! So it is not rear to read hyperscalers want nuclear reactors.
It seems Malaysia is getting a DC boom, but it based on coal???
This is a MS NVIDIA GB200 based rack. I am quite impressed with the cooling systems being twice as big as the compute rack! And yes, MS is sticking with IB for AI networking.
I didnt know that Oracle OCI was getting that big in the DC/AI business. And they were related to xAI. Their biggest DC is 800 megwatts… and a new one will have three nuclear reactors??
FuriosaAI: A new AI accelerator in the market. Good: cheap, less power. Bad: memory size.
OCP concrete: Interesting how far can go the OCP consortium.
IBM Mainframe Telum II: You think the mainframes business doesnt exist. Well, it is not. Honestly, at some point, I would like to fully understand the differences between a “standard” CPU and a mainframe CPU.
NotoebookLM: It seems it is possible to make summary of youtube videos! (and free)
EdgeShark: wireshark for containers. This has to be good for troubleshooting
OCP24 Meta AI: It is interesting comparing the Catalina rack with the one from MS above. The MS has the power rack next to it but FB doesnt show it, just mention Orv4 supports 140kW and it is liquid cooled. I assume that will be next to Catalina like MS design. And AMD GPU are getting into the mix with NVIDIA. It mentions Disaggregated Scheduled Fabric (DSF), with more details here. And here from STH more pictures.
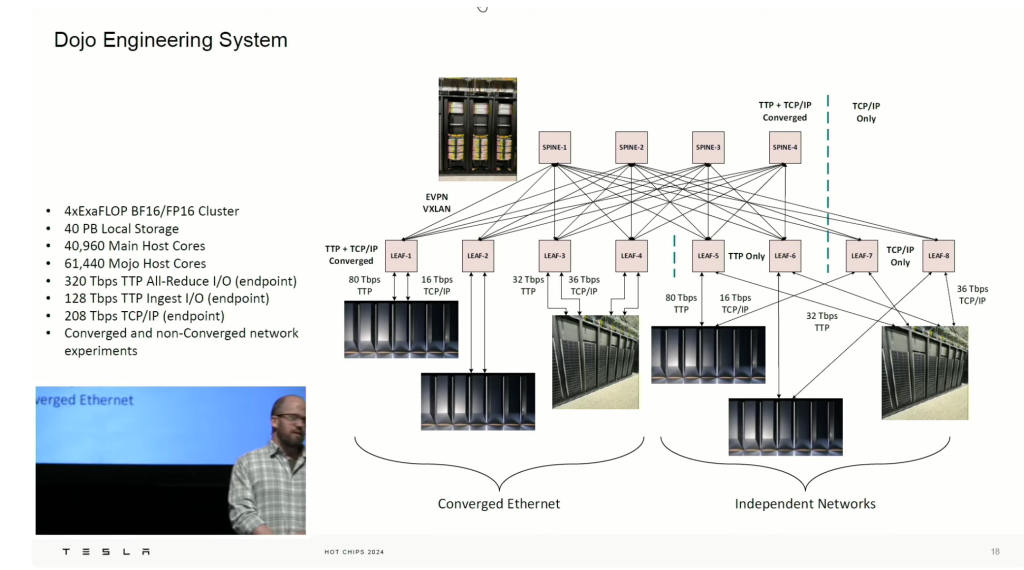
Testa TCP replacement: Instead of buying and spending a lot of money, built what you need. I assume very smart people around and real network engineering taking place.It is like a re-write of TCP but doesnt break it so your switches can still play with it. It seems videos are not available in the hotchips webpage yet. And this link looks even better, even mentions Arista as the switching vendor. (video from hotchips24)
Cerebras Inference: From hotchips 2024. I am still blow away for the waferscale solution. Obviously, the presentation says its product is the best but I wonder, can you install a “standard” linux and run your LLM/Inference that easily?
Leopold AIG race: Via linkedin, then the source. I read the chapter 3 regarding the race to the Trillion-Dollar cluster. It all looks Sci-Fi, but I think it may be not that far from reallity.
Cursor + Sonet: Replacement for copilot? original I haven’t used Copilot but at some point I would like to get into the wagon and try things and decide for myself.
AI AWS Engineering Infra: low-latency and large-scale networking (\o/), energy efficiency, security, AI chips.
NVLink HGX B200: To be honest, I always forger the concept of NVLink and I told my self it is an “in-server” switch to connect all GPUs in a rack. Still this can help:
At a high level, the consortium’s goal (UltraEthernet/ UA) is to develop an open standard alternative to Nvidia’s NVLInk that can be used for intra-server or inter-server high-speed connectivity between GPU/Accelerators to build scale-up AI/HPC systems. The plan is to use AMD’s interconnect (Infinity Fabric) as the baseline for this standard.
Netflix encoding challenges: From encoding per quality of connection, to per-title, to per-shot. Still there are challenges for live streaming. Amazon does already live streaming for sports, have they “solved” the problem? I dont use Netflix or similar but still, the challenges and engineering behind is quite interesting.
Some career advice from AWS: I “get” the point but still you want to be up to speed (at certain level) with new technologies, you dont want to become a dinosaur (ATM, frame-relay, pascal, etc).
Again, it’s not about how much you technically know but how you put into use what you know to generate amazing results for a value chain.
Get the data – be a data-driven nerd if you will – define a problem statement, demonstrate how your solution translates to real value, and fix it.
“Not taking things personally is a superpower.” –James Clear
Because “no” is normal.
Before John Paul DeJoria built his billion-dollar empire with Patrón and hair products, he hustled door-to-door selling encyclopedias. His wisdom shared at Stanford Business School on embracing rejection is pure gold (start clip at 5:06).
You see, life is a numbers game. Today’s winners often got rejected the most (but persevered). They kept taking smart shots on goal and, eventually, broke through.
Cloudflare backbone 2024: Everything very high level. 500% backbone capacity increase since 2021. Use of MPLS + SR-TE. Would be interesting to see how the operate/automate those many PoPs.
Cisco AI: “three of the top four hyperscalers deploying our Ethernet AI fabric” I assume it is Google, Microsoft and Meta? AWS is the forth and biggest.
xAI 100k GPU cluster: 100k liquid-cooled H100s on single RDMA fabric. Looks like Supermicro involved for servers and Juniper only front-end network. NVIDIA provides all ethernet switches with Spectrum-4. Very interesting. Confirmation from NVIDIA (Spectrum used = Ethernet). More details with a video.
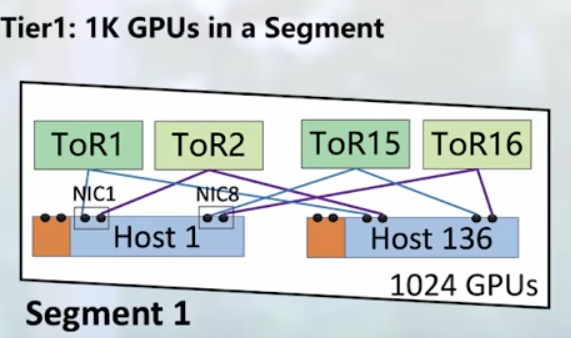
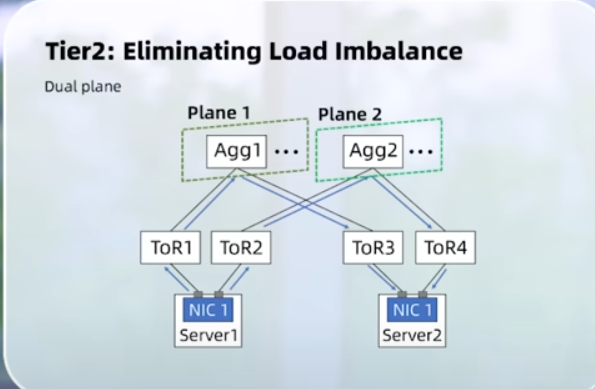
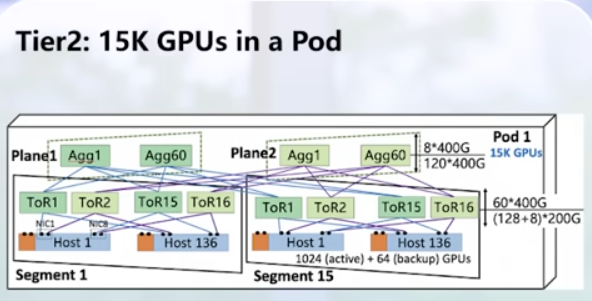
Scale Systems 2024 (videos): GenAI Training: Short but interesting video. Main failures: GPU, memory and network cables 🙂 For the Network side, I liked this screenshot. Still they are able to build two 24k GPU cluster with IB and RoCE2.
Starlink TCP: Very quick summary, control protocols with Selective Ack perform better. The ping analysis is quite good. Being able to see that each 15s you are changing satellite, is cool.
NVIDIA Computex 2024: It seems they are going to yearly cadence for networking kit. They showed plans for 2025 and 2026… I liked the picture of a NVLink spine and the huge heatsinks for B200….
UALink: The competition for NVLink. This is for GPU-to-GPU communication. UltraEthernet is for connecting pods.
Aurora supercomputer: Exascale broken. Based on HPE slingshot interconnect (nearly 85k endpoints) Everything else is Intel.
Arista AI Center: it seems they are going to team-up with NVIDIA. Some EOS running on the nics.
Kubenet: Seems interesting but only supporting Nokia SRLinux at the moment.
“Lo que hicimos fue un trabajo personalizado en el que cuidamos todos los aspectos de la nutrición y buscamos la regeneración y la correcta expresión de sus genes.”
“fisiogenómica: Yo lo llamo así porque mezcla fisioterapia, nutrición y nutrigenómica. En cada persona tenemos que buscar por síntomas, análisis e intervenciones qué alimentos limitar por producir una mala expresión genética, pero todas las pautas están basadas en la Pirámide de la Dieta Mediterránea”
Cloudflare and Let’s Encrypt’s certificate change: I haven’t heard of this until recently. I use Let’s Encrypt so as far as I can read, makes sense what they are doing. But didnt know 2% Cloudflare customer were using the “cert”
ChatDev: Communicate agents for software development. I am a not a developer but I would use this just as a starting point If I have any idea for a project. I would remove the C-suite agents, at least for low level projects.
IB vs Ethernet: A bit of bias here (the author is from Broadcom -> Ethernet). I have no hands-on experience with IB, but I have read the cables are not cheap… Let’s see when UltraEthernet gets into the market. Another view.
Slingshot and Juniper: A bit of bias again as HP bought Juniper. So how will these interconnects fade inside the company? As far as I know, most supercomputers use some “special” interconnect so not much ethernet there. But the money nowadays is in AI infra… Paper for slingshot (haven’t read it)
Tailscale SSH, wireguard throughput: These are things I should a spend a bit of time one day and consider if I should use them (I dont like it is not opensource though). This netmaker?
Videos:
Jocko Willink: Discipline = Freedom. Remember but not dwell. Good leader, delegate. Be a man -> take action, bonding (pick your activity)
Jimmy Carr: Imposter syndrome each 18 months, so you have to stand-up. People crave the success not the journey. Teaching comedy good for communicating.
Sam Altman – Stanford 2024: First time I see him talking. It has some funny moments. More powerful computers. I missed a question about opensource LLM and closed ones.
Find a girlfriend: I know just a little bit about the person (I want to read one of his books) from other books and videos. I would think he would have already a girlfriend or family. From the three methods, definitely, the face to face approach in the street looks so much better (and that’s what I would like to do)
CNI performance: I have used kubernetes since I studied for CKAD but still I am interested in the networks side. I didn’t know about Kube-router and it did great! I am bit surprised with Calico as I have read more and more about Cilium.
rsync go: Interesting talk about rsync, as it explains how it works and it is something I didnt know. But then, all other things/projects mentioned are cool and related. I need to try to install rsync go in my vm. cccslides and repo
NASA to the moon: This is an engaging and provocative video regarding the Artemis III (project back to the moon II). He makes some hard questions to the people in charge (I have no clue about physics) and it seems he has a point. Not sure it this will get any effect but again, looks “smart”. When he mention the NASA SP287 (What made Apollo a success) document as the grial for going back to the moon, I wanted to get a copy (here) so I could read it one day.
Git options: Nice post about popular git config options. I am a very basic git user (and still sometimes I screw up) but the options to improve diff looks interesting so I will give it a go at work.
Undersea cable failures in Africa: It is clear that Africa relays heavily in submarine cables (it doesnt look like there are many cable systems intra continent). And the Red Sea is becoming a hot area due to different conflicts…
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system. (John Gall)
In programming, simplicity and clarity are a crucial matter that decides between success and failure. (Edsger Dijktra)
Log4j: This is old news but when it came out I tried to run the PoC but I failed 🙁 This is just a reminder. It was annoying because I manged to install all tools but never managed to exploit it.
Done List: I feel totally identified. The to-do list is never done and you feel guilty. Done-list, much healthier.
Dan Lynch: He passed away, and as usual on my ignorance, it seems he is one of the unsung heroes of Internet, migrating ARPANET to TCP/IP.
Systems-Based Productivity: TEMPO refers to five dimensions of productivity: T (Time Management), E (Energy Management), M (Mindset), P (Proficiency) and O (Organization).
InfraOps challenge: A bit beyond me, but interesting If you could try without applying for the job.
Devika: Agent AI. Another thing I would like to have time to play with it. If you have API keys for some LLMs, looks like it shouldn’t be difficult to run and you dont need a powerful laptop (?)
Daytona: My development environment is a joke, just python envs. But I guess for more serious devs, could be interesting
NTP and year 2038: Agree, when it is not DNS, it is likely NTP (seen this with VPNs and SSL certs in boxes with NTP unsync), or something blocking UDP.
Linux crisis tools: I haven’t got my hands dirty with BPF but I am surprised with so many tools. I would add nc, netstat, lsof, traceroute, ping, vim, openssl etc but because I do pure networks.
Jim Kwik: How to improve your reading speed. One improvement is you use your finger or a ruler. Need to watch again.
Rich Roll: The guy is super chill. I would like to be able to do some ultra at some point in life… Very personal conversation.
Ferran Adria: I didnt know much about the person apart from being one of the best Chefs in history. I like how he starts the interview and take over for 15 minutes. Haven’t watched till the end. But just the beginning is priceless.
Mark Manson: I have read all his books and his emails. Interesting his story.
Chocolonely: I didnt know it was a dutch company and interesting history behind. I want to try one day, but I haven’t found a dark choco version.
LLM in 1000 lines puce C: I was always crap at C. But interesting this project as something educational and intro in LLM.
Enforce-first-as: I dint know about this until last week. Cisco defined by default. Juniper disabled by default. And this makes sense with Route Servers.
Several posts worth reading. There are plenty of things go over my knowledge. I already posted this, it is a good refresher.
GPU Fabrics: The first of the article is the one I am more lost as it about training and the communications between the GPU depending on the take to handle the models. There are several references to improvements as the use of FP8 and different topologies. As well, a bit more clear about NVLink (as internal switch for connecting GPUs inside the same server or rack)
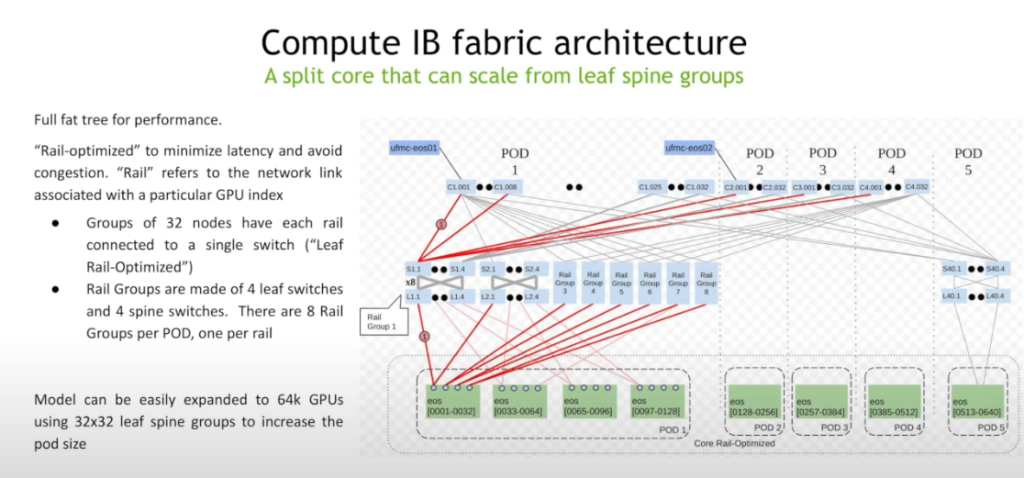
When it moved to the inter-server traffic, I started to understand a bit more things like “rail-optimized” (it is like having a “plane” for my old job where the leaf only connects to a spine instead of all spines, in this case each GPU connects to just one leaf. If you cluster is bigger then you need spines). I am not keen of modular chassis from operations point of view but it is mentioned as an option. Fat-tree CLOS, Dragon-Fly: reminds me to Infiniband. Like all RDMA.
And Fabric congestion it is a big topic with many different approaches: adaptive LB (IB again), several congestion control protocols and mention to Google (CSIG) and Amazon (SDR) implementations.
In general I liked the article because I dont really feel any bias (she works for Juniper) and it is very open with the solutions from different players.
LLM Inference – HW/SW Optimizations: It is interesting the explanation about LLM inferencing (doubt I can’t explain it though) and all different optimizations. The hw optimization (different custom hw solutions vs GPU) section was a bit more familiar. My summary is you dont need the same infrastructure (and cost) for doing inference and there is an interest for companies to own that as it should be better and cheaper than hosting with somebody else.
Network Acceleration for AI/ML workloads: Nice to have a summary of the different “collectives”. “collectives” refer to a set of operations involving communication among a group of processing nodes (like GPUs) to perform coordinated tasks. For example, NCCL (Nvidia Collective Communication Library) efficiently implements the collective operations designed for their GPU architecture. When a model is partitioned across a set of GPUs, NCCL manages all communication between them. Network switches can help offload some or all of the collective operations. Nvidia supports this in their InfiniBand and NVLink switches using SHARP (Scalable Hierarchical Aggregation and Reduction Protocol – proprietary). This is call “in-network computing”. For Ethernet, there are no standards yet. The Ultra Ethernet Consortium is working on it but will take years until something is seen in production. And Juniper has the programmable architecture Trio (MX routers – paper) that can do this offloading (You need to program it though – language similar to C). Still this is not a perfect solution (using a switches). The usage of collectives in inference is less common than their extensive use during the training phase of deep learning models. This is primarily because inference tasks can often be executed on a single GPU
From a different topics:
Learning at Cambridge: Spend less hours studying, dont take notes (that’s hard for me), go wild with active learning (work in exercises until you fully understand them)
British Library CyberAttack: blog and public learning lesson. I know this is happening to often for many different institutions but this one caught my eye 🙁 I think is a recurrent theme in most government institutions were upgrading is expensive (because it is not done often), tight budgets and IT experts.
“Our major software systems cannot be brought back in their pre-attack form, either because they are no longer supported by the vendor or because they will not function on the new secure infrastructure that is currently being rolled out”
However, the first detected unauthorised access to our network was identified at the Terminal Services server. Likely a compromised account.
Personally, I wonder what you can get from “stealing” in a library ???