I have done some lentils and beans stew before haven’t tried chickpeas stew “cocido” before. And I fancied a good homemade cocido soup! So as I had my last piece of cure ham in the freezer, I went for it. This is a proper cocido, but I used the ingredients I had at hand and the result was very tasty. That’s what matters to me.
Ingredients
1 piece of cure ham
1 chicken breast sliced
1 portion of chorizo
1 potato
1 cup of chickpeas cover on water from the day before
1 onion
1 carrot
2 cloves of garlic
Salt, pepper
Paprika (pimenton!)
Some greens: I used chard
2-3 handfuls of fideos
Process
Get a big pan, put all ingredients apart from the greens and fideos
Fill the pan with boiling water. Put the pan at medium heat until start boiling. We want plenty of liquid for the soup!
Reduce heat till simmer. Stir from time to time for 1 hour of so.
Taste the liquid, it should have a strong flavour. If the potatoes, chickpeas and carrot are soft, we are nearly done.
Add the green and fideos. Stir for couple of minutes until the fideos are cooked. The greens will boil and keep a nice color.
Shred the ham so it releases all juices. Mix all together
All done, it is quite easy. And had a tasty lunch for the work week!
MM is one of the few people I read/folllow and his newsletter (and books) is one of the best in my opinion. And today I had a laugh about this week entry. I have never heard about the impact of CO2 with obesity but who knows. The funny part was the theory about the “world peace period” is mainly chased by the big corporations (McDonalds, Dell, etc) because war doesnt make profit for them. In one side, makes sense, USA-China are like a old married couple, standard war is not profitable. Just do it somewhere else.
I was surprised today reading this blog entry. Watching the video, it reminds me to techno, so it is good. And reading further his bio in wikipedia, I was really impressed with his persona, political/social effort and music. And somehow, I noticed there was a movie about him, I am pretty sure I have seen the ad somewhere but as usual, I normally ignore the movies.
I dont believe in those hall of fame things, but definitely I would put Tina, RATM and Fela.
When making hot chocolate at home, I used to use the pre-mix thing, the result was good. But this time, I wanted to make it from scratch and get the final hot chocolate I like when as a kid bought “churros”: thick, delicious hot chocolate.
So I have tried several methods, but I made my best result based on this video. Easy ingredients, easy process. Great result!
Ingredients:
1/3 cup of plain flour
1/3 cup of 100% cocoa powder
1/3 cup of sugar
2 cups of milk
Process:
Mix all dry ingredients in a bowl.
Add the milk to the dry ingredients and mik well.
Put the mix at medium hit and stir from time to time. It will start to thicken up in 15 minutes or so. Be sure it doesnt stick in the bottom of the pan.
Taste it, you may add some spoons of cocoa if it is too sweet.
Once it is thick for your taste, remove from the heat and enjoy!
As a kid, sometimes I used hard bread with my chocolate. Good memories today!
I wanted to read this book for some time. It became a hit in its time and there was a movie. But to be honest I wasn’t sure what was about. So finally managed to get a copy and read it. I was surprise that it was a comic novel but really enjoyed.
I read it quite fast, it was engaging and when you finished, you wanted more.
But it clearly made me think. How was Iran before, during and after the revolution. What a curse can be the oil. How shit we are the western nations. How shit we are human beings. How the author had to go through so many different stages in life to find herself, find the connection, find your belonging.
And, as many times tell myself, how lucky like I am, although some times struggle with it.
There is a point in the book, when the Irak-Kuwait war in the 90s triggered a panic in Europe, like it was the end of the world (like with covid lately) and Marjane parents laugh at it because the war was so far from Europe and they have already went through several years of war.
I wrote an entry based on a blog from Seth Godin some months ago. I was curious about the guy and I subscribed to his blog and bought one of his books. I finished last night and it as good things.
You can take it as directed to marketing people but you can use it for nearly everything. At the end of the day, it is not talent. It is practice and attitude. This is a concept I have read in different ways from several books like flow, midset, etc. And with practice, at the end, the result takes care by itself. You focus in the practice. You have your goal, you know why you are doing it. You can’t guarantee the result, dont worry about it. Just put yourself in the hook. You can’t please everybody, know for whom you are doing it. Trust yourself, you dont need external validation (MBA, CCIE, etc)
If you take this from the bright side, it is great, you can achieve most things in life with dedication. You dont have to born with the skill, wait for the muse, have the holy inspiration. You can be the tortoise and still win a race. And, it is a stop to the excuse of “I am not smart”, “I am not beautiful”, etc. So, turn up, start moving, do the job, dont overthink it, dont wait for the inspiration. Simply, repeat. There are things we can control, and others not.
In part of the book, I wondered, how all this fit with the concept “work-hard”, “work long hours”, “work-life balance”. Sometimes got the feeling that all this denies to have “a life”. It is great to enjoy your job, it is so important for social, financial and psychological reasons. But does it have to be ALL?
Learning and education is not the same. Learning is voluntary, it can be ugly as it requires some tension and discomfort. If you get something done without effort, you dont enjoy it. Here personally, as per “flow”, it has a manageable difficulty, something that makes you grow. Drop by drop you fill the bucket. I dont need everything now.
Something that I liked a lot: “Play to play, not to win.”
Scarcity and creativity: Actually everything is out there and there is plenty, it is up to grabs. Determination (your practice) is what you need. This plays with the concept of “The fear of falling behind”. It is something the current society makes a believe: extreme capitalism, social media, etc.
it is a good book, you can take positive things from it.
Again, I am following the author post but adapting it to my environment using libvirt instead of VirtualBox and Debian10 as VM. All my data is here.
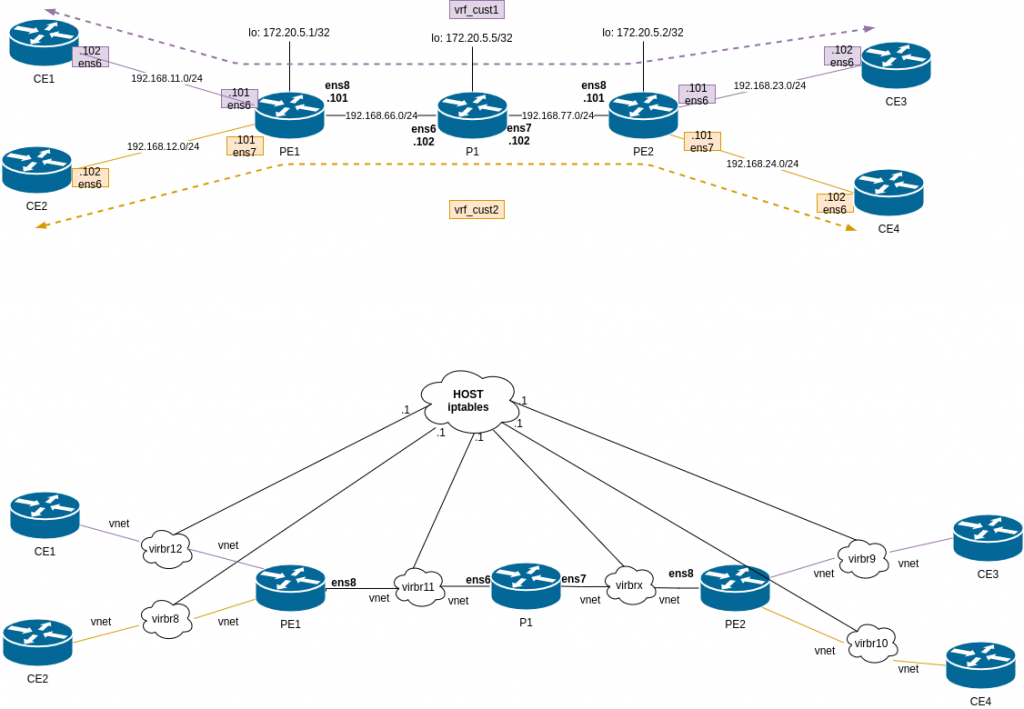
This is the diagram for the lab:
Difference from lab3 and lab2. We have P1, that is a pure P router, only handling labels, it doesnt do any BGP.
This time all devices FRR config are generated automatically via gen_frr_config.py (in lab2 all config was manual).
Again the environment is configured via Vagrant file + l3vpn_provisioning script. This is mix of lab2 (install FRR), lab3 (define VRFs) and lab1 (configure MPLS at linux level).
So after some tuning, everything is installed, routing looks correct (although I dont know why but I have to reload FRR to get the proper generated BGP config in PE1 and PE2. P1 is fine).
So let’s see PE1:
IGP (IS-IS) is up:
PE1# show isis neighbor
Area ISIS:
System Id Interface L State Holdtime SNPA
P1 ens8 2 Up 30 2020.2020.2020
PE1#
PE1# exit
root@PE1:/home/vagrant#
BGP is up to PE2 and we can see routes received in AF IPv4VPN:
PE1#
PE1# show bgp summary
IPv4 Unicast Summary:
BGP router identifier 172.20.5.1, local AS number 65010 vrf-id 0
BGP table version 0
RIB entries 0, using 0 bytes of memory
Peers 1, using 21 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt
172.20.5.2 4 65010 111 105 0 0 0 01:39:14 0 0
Total number of neighbors 1
IPv4 VPN Summary:
BGP router identifier 172.20.5.1, local AS number 65010 vrf-id 0
BGP table version 0
RIB entries 11, using 2112 bytes of memory
Peers 1, using 21 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt
172.20.5.2 4 65010 111 105 0 0 0 01:39:14 2 2
Total number of neighbors 1
PE1#
Check routing tables, we can see prefixes in both VRFs, so that’s good. And the labels needed.
PE1# show ip route vrf all
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
VRF default:
C>* 172.20.5.1/32 is directly connected, lo, 02:19:16
I>* 172.20.5.2/32 [115/30] via 192.168.66.102, ens8, label 17, weight 1, 02:16:10
I>* 172.20.5.5/32 [115/20] via 192.168.66.102, ens8, label implicit-null, weight 1, 02:18:34
I 192.168.66.0/24 [115/20] via 192.168.66.102, ens8 inactive, weight 1, 02:18:34
C>* 192.168.66.0/24 is directly connected, ens8, 02:19:16
I>* 192.168.77.0/24 [115/20] via 192.168.66.102, ens8, label implicit-null, weight 1, 02:18:34
C>* 192.168.121.0/24 is directly connected, ens5, 02:19:16
K>* 192.168.121.1/32 [0/1024] is directly connected, ens5, 02:19:16
VRF vrf_cust1:
C>* 192.168.11.0/24 is directly connected, ens6, 02:19:05
B> 192.168.23.0/24 [200/0] via 172.20.5.2 (vrf default) (recursive), label 80, weight 1, 02:13:32
via 192.168.66.102, ens8 (vrf default), label 17/80, weight 1, 02:13:32
VRF vrf_cust2:
C>* 192.168.12.0/24 is directly connected, ens7, 02:19:05
B> 192.168.24.0/24 [200/0] via 172.20.5.2 (vrf default) (recursive), label 81, weight 1, 02:13:32
via 192.168.66.102, ens8 (vrf default), label 17/81, weight 1, 02:13:32
PE1#
Now check LDP and MPLS labels. Everything looks sane. We have LDP labels for P1 (17) and PE2 (18). And labels for each VFR.
PE1# show mpls table
Inbound Label Type Nexthop Outbound Label
16 LDP 192.168.66.102 implicit-null
17 LDP 192.168.66.102 implicit-null
18 LDP 192.168.66.102 17
80BGPvrf_cust1 -
81BGPvrf_cust2 -
PE1#
PE1# show mpls ldp neighbor
AF ID State Remote Address Uptime
ipv4 172.20.5.5 OPERATIONAL 172.20.5.5 02:20:20
PE1#
PE1#
PE1# show mpls ldp binding
AF Destination Nexthop Local Label Remote Label In Use
ipv4 172.20.5.1/32 172.20.5.5 imp-null 16 no
ipv4 172.20.5.2/32 172.20.5.5 18 17 yes
ipv4 172.20.5.5/32 172.20.5.5 16 imp-null yes
ipv4 192.168.11.0/24 0.0.0.0 imp-null - no
ipv4 192.168.12.0/24 0.0.0.0 imp-null - no
ipv4 192.168.66.0/24 172.20.5.5 imp-null imp-null no
ipv4 192.168.77.0/24 172.20.5.5 17 imp-null yes
ipv4 192.168.121.0/24 172.20.5.5 imp-null imp-null no
PE1#
Similar view happens in PE2.
From P1 that is our P router. We only care about LDP and ISIS
P1#
P1# show mpls table
Inbound Label Type Nexthop Outbound Label
16 LDP 192.168.66.101 implicit-null
17 LDP 192.168.77.101 implicit-null
P1# show mpls ldp neighbor
AF ID State Remote Address Uptime
ipv4 172.20.5.1 OPERATIONAL 172.20.5.1 02:23:55
ipv4 172.20.5.2 OPERATIONAL 172.20.5.2 02:21:01
P1#
P1# show isis neighbor
Area ISIS:
System Id Interface L State Holdtime SNPA
PE1 ens6 2 Up 28 2020.2020.2020
PE2 ens7 2 Up 29 2020.2020.2020
P1#
P1# show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
K>* 0.0.0.0/0 [0/1024] via 192.168.121.1, ens5, src 192.168.121.253, 02:24:45
I>* 172.20.5.1/32 [115/20] via 192.168.66.101, ens6, label implicit-null, weight 1, 02:24:04
I>* 172.20.5.2/32 [115/20] via 192.168.77.101, ens7, label implicit-null, weight 1, 02:21:39
C>* 172.20.5.5/32 is directly connected, lo, 02:24:45
I 192.168.66.0/24 [115/20] via 192.168.66.101, ens6 inactive, weight 1, 02:24:04
C>* 192.168.66.0/24 is directly connected, ens6, 02:24:45
I 192.168.77.0/24 [115/20] via 192.168.77.101, ens7 inactive, weight 1, 02:21:39
C>* 192.168.77.0/24 is directly connected, ens7, 02:24:45
C>* 192.168.121.0/24 is directly connected, ens5, 02:24:45
K>* 192.168.121.1/32 [0/1024] is directly connected, ens5, 02:24:45
P1#
So as usual, let’s try to test connectivity. Will ping from CE1 (connected to PE1) to CE3 (connected to PE2) that belong to the same VRF vrf_cust1.
First of all, I had to modify iptables in my host to avoid unnecessary NAT (iptables masquerade) between CE1 and CE3.
I have double-checked the configs. All routing and config looks sane in PE2:
vagrant@PE2:~$ ip route
default via 192.168.121.1 dev ens5 proto dhcp src 192.168.121.31 metric 1024
172.20.5.1 encap mpls 16 via 192.168.77.102 dev ens8 proto isis metric 20
172.20.5.5 via 192.168.77.102 dev ens8 proto isis metric 20
192.168.66.0/24 via 192.168.77.102 dev ens8 proto isis metric 20
192.168.77.0/24 dev ens8 proto kernel scope link src 192.168.77.101
192.168.121.0/24 dev ens5 proto kernel scope link src 192.168.121.31
192.168.121.1 dev ens5 proto dhcp scope link src 192.168.121.31 metric 1024
vagrant@PE2:~$
vagrant@PE2:~$ ip -4 a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 172.20.5.2/32 scope global lo
valid_lft forever preferred_lft forever
2: ens5: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.121.31/24 brd 192.168.121.255 scope global dynamic ens5
valid_lft 2524sec preferred_lft 2524sec
3: ens6: mtu 1500 qdisc pfifo_fast master vrf_cust1 state UP group default qlen 1000
inet 192.168.23.101/24 brd 192.168.23.255 scope global ens6
valid_lft forever preferred_lft forever
4: ens7: mtu 1500 qdisc pfifo_fast master vrf_cust2 state UP group default qlen 1000
inet 192.168.24.101/24 brd 192.168.24.255 scope global ens7
valid_lft forever preferred_lft forever
5: ens8: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.77.101/24 brd 192.168.77.255 scope global ens8
valid_lft forever preferred_lft forever
vagrant@PE2:~$
vagrant@PE2:~$
vagrant@PE2:~$
vagrant@PE2:~$
vagrant@PE2:~$ ip -M route
16 as to 16 via inet 192.168.77.102 dev ens8 proto ldp
17 via inet 192.168.77.102 dev ens8 proto ldp
18 via inet 192.168.77.102 dev ens8 proto ldp
vagrant@PE2:~$
vagrant@PE2:~$ ip route show table 10
blackhole default
192.168.11.0/24 encap mpls 16/80 via 192.168.77.102 dev ens8 proto bgp metric 20
broadcast 192.168.23.0 dev ens6 proto kernel scope link src 192.168.23.101
192.168.23.0/24 dev ens6 proto kernel scope link src 192.168.23.101
local 192.168.23.101 dev ens6 proto kernel scope host src 192.168.23.101
broadcast 192.168.23.255 dev ens6 proto kernel scope link src 192.168.23.101
vagrant@PE2:~$
vagrant@PE2:~$
vagrant@PE2:~$ ip vrf
Name Table
vrf_cust1 10
vrf_cust2 20
vagrant@PE2:~$
root@PE2:/home/vagrant# sysctl -a | grep mpls
net.mpls.conf.ens5.input = 0
net.mpls.conf.ens6.input = 0
net.mpls.conf.ens7.input = 0
net.mpls.conf.ens8.input = 1
net.mpls.conf.lo.input = 0
net.mpls.conf.vrf_cust1.input = 0
net.mpls.conf.vrf_cust2.input = 0
net.mpls.default_ttl = 255
net.mpls.ip_ttl_propagate = 1
net.mpls.platform_labels = 100000
root@PE2:/home/vagrant#
root@PE2:/home/vagrant# lsmod | grep mpls
mpls_iptunnel 16384 3
mpls_router 36864 1 mpls_iptunnel
ip_tunnel 24576 1 mpls_router
root@PE2:/home/vagrant#
So I am a bit puzzled the last couple of weeks about this issue. I was thinking that iptables was fooling me again and was dropping the traffic somehow but as far as I can see. PE2 is not sending anything and I dont really know how to troubleshoot FRR in this case. I have asked for help in the FRR list. Let’s see how it goes. I think I am doing something wrong because I am not doing anything new.
I was getting many video recommendations about this type of cheesecake. So I gave it a go:
Ingredients:
4 big eggs
500g cream cheese
250g double cream
200g sugar (I used 150g)
1 tsp plain flour
Process:
Pre-heat oven at 200C
Mix cream cheese and sugar.
Add eggs and mix
Add double cream and mix
Add flour and mix
Use two wet pieces of baking paper into a round mold.
Pour the mix into the mold
Bake for 40 minutes or until quite brown on top.
Let it cool down for a bit and then put into the fridge for a couple of hours.
The recipe is quite easy and quick. To be honest, it tastes good, even better the next day. Best cheesecake ever? Don’t care, but I need to compare with the cheesecake I used to bake.
To be honest, I dont know how to translate it, but I found the video randomly and gave it a go. Quite happy with the result.
Ingredients:
4 potatoes
1 leek
2 carrots
100 grams of spinach
1 red pepper
4 medium eggs
4 tablespoons of olive oil,
4 tablespoons of milk
4 tablespoons of flour
1/2 pack of baking powder
2 teaspoons salt, peppe
50 grams of grated cheese
Sesame seeds
Process:
1) Slice the leeks, red pepper and spinach. The add the potatoes and carrots grated. Mix all together.
2) In a bowl, whisk the eggs with the oil. Add the flour and whisk. Add the milk and whisk. Add the baking powder and whisk. Add the salt and pepper and whisk.
3) Pour the butter into the veggie try. Mix everything. Try to flat out the mix as much as you can.
4) Put the try in a pre-heat oven at 180C for 25 minutes.
5) Remove from the oven and add the cheese and sesame seeds. Put back in the oven until cheese forms a crust.
6) Remove from oven and let is cool down for a bit. Then cut in squares.
I fancied something light to read. Oh, how enjoyed those memories when I wished to be an archaeologist like Indy. It was like watching the movie again. I didnt care I knew every twist. It brought me some smiles. Pity I devoured it so fast. Will get to the last one at some point.