I really want to try one day access the darkweb. No idea if this video is good but could be a starting point.
Unrelated, I am trying to get better at playing chess (extremely slowly if any progress). This video is amazing. And learn Go some day… (as usual no enough time)
This is a conference about networks that I was interested and I finally got some emails with the presentations. They are mainly from Meta.
Meta’s Network Journey to Enable AI: video – second part interesting.
AI fabric (backend: gpu to gpu) hanging from DC fabric.
SPC (Space, Power, Cooling)
Fiber, Automation
RDMA requires (lossless, low-latency, in-order) -> ROCEv2(Ethernet) or IB
Servers have 8x400G to TOR. Tor 400G to Spines
1xAI zone per DH. 1xDC has several DHs.
Oversubscribed between zones, eBGP, ECMP.
Scaling RoCE Networks for AI Training: video — Really really good.
RMDA/IB used for long time in Research.
Training: learning a new capability from existing data (focus of the video)
Inference: Applying this capability to new data (real time)
Distributed training for complex models. GPU to GPU sync -> High BW and low/predictable latency.
ROCEv2 with (tuned) PFC/ECN. TE + ECMP (flow multplexing)
Oversubscription is fine in spine (higher layer)
Challenges: Load balancing (elefant flows), Slow receivers/back pressure, packet loss from L1 issues (those flapping links, faulty optics, cables, etc xD), debugging (find jobs failures)
Traffic Engineering for AI Training Networks : video – interesting both parts.
Non-blocking. RTSW=TOR. CTSW=Spine. Fat-Tree Architecture. 2xServer per rack. 1xserver=8xGPU. CTSW=16 downlinks -> 16 uplinks. Up to 208 racks?
ROCE since 2020. CTSW are high redix and deep buffer switches.
AI Workload challenges: low entropy (flow repetitive, predictable), bursty, high intensity elephant flows.
SW based TE: dynamic routing adapted on real-time. Adaptive job placement. Controller (stateless)
Data plane: Overlay (features from broadcom chips) and Underly (BGP)
Flow granularity: nic to host flow.
Handle network failures with minimum convergence time. Backdoor channel with inhouse protocol.
Simulation platform. NCCL benchmark.
Networking for GenAI Training and Inference Clusters: video Super Good!
Recommendation Model: training 100GFlops/interation. inference: few GFlops/s for 100ms latency.
LLM: training 1PetaFlops/sentence (3 orders magnitude > recommendation), inference: 10PF/s for 1sec time-to-first token. +10k GPUs for training. Distributed inferencce. Need Compute too.
LLama2 70Billion tokens -> 1.7M hours of GPU. IB 200G per GPU, 51.2 TB/s bisection bw. 800 ZetaFlops. 2 Trillion dataset. 2k A100 GPUs. As well, used ROCEv2 (LLama2 34B).
+30 ExaFlops (30% of H100 GPUs fp8 peak) + LLama65B training < 1day.
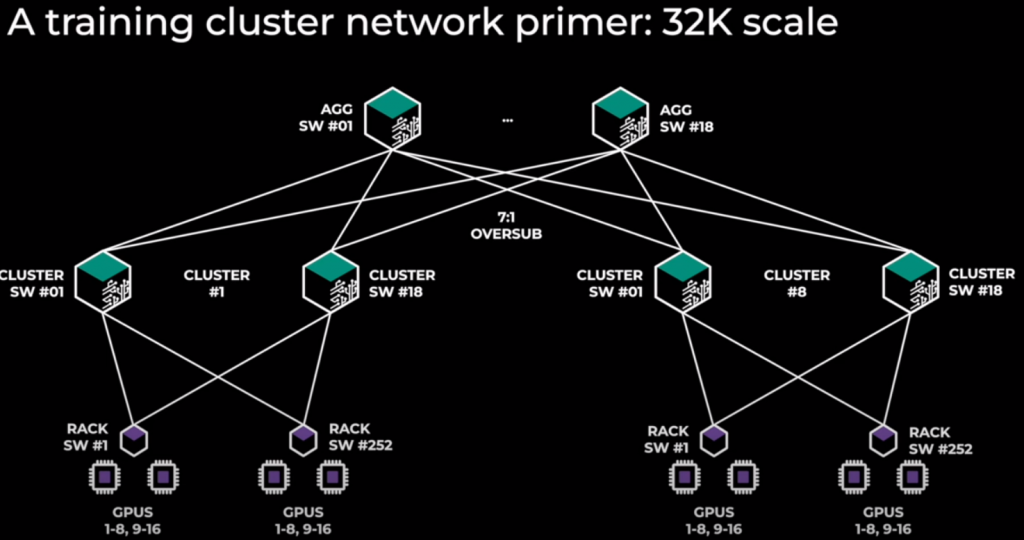
Massive cluster: 32k GPUs! Model Parallelism.
LLM inference: dual-edge problem. Prefill large messages (High BW) + Decode small messages (latency sensitive).
Scale out (-bw, large domain. Scalable RDMA (IB or Ethernet), data parallel traffic) + Scale up (+BW, smaller domain. NVLink 400G, model parallel traffic)
32k GPU. TOR (252), Spine (18), AGG (18). 3 levels. Oversubscription Spine-Agg 7:1. 8 clusters. 252 racks per cluster. 16 GPUs per rack (8x252x16=32k GPUs). ROCEv2!
Model Parallelism harder for computation. Model Parallel traffic: all-reduced/all-to-all, big messages (inside cluster = sclae-up). Data Parallel traffic: all-gather & reduce-scatter (between cluster = scale-out, NVLink)
Challenges: Latency matters more than ranking. Reliability !!!!!
From ESNOG (although I am subscribed, I dont really receive notifications…) I saw this presentation, and then I found the main video reference.
BUM: 1.5Mbps -> that goes to all customer ports!! Small devices can’t cope with that.
Ratelimiting for BUM ingress/egress
Originally IXP is VPLS. Issue with long lasting flows / long lasting MACs
Solution: EVPN + ProxyARP/ND Agent.
I know EVPN is mainly for Datacenters but it is interesting the move to IXP. Although I remember reading about EVPN into Cisco IOS-XR platform that is mainly a ISP device.
I didnt know anything about this conference until the last two months started to read news about it from different blogs. I am surprised the webpage doesnt link to the videos. This one is quite interesting but after the 15 minute becomes very hardcode for me.
I guess there are hundreds of project that try to use GPT to build apps. I found this one and looks very nice. I would like to use it if I find time for one idea.
From this blog, I could read an interesting presentation about network performance using satellite services. I guess there are many blogs about the performance of Starlink but this was the first time I read something about it. I was surprised the results were not that good even with the latest version of Startlink (that I didnt know neither)
I checked out this blog note from Google about Falcon. To be honest, I dont really understand the “implementation”. Is it purely software? Does it interact with merchant Ethernet silicon ASICs? There is so much happening trying to get Ethernet similar to Infiniband that I am wonder how this fits outside Google infra. At the end of the day, Ethernet has been successful because everybody could use it for nearly anything. Just my opinion.
I watched this video yesterday by coincidence . I was keen to know about making learning addictive. And honestly, I liked the video, it was funny and informative. And it is interesting that you can turn evil manipulations into positive ones. I didnt know the presenter was the founder of duolingo and he was from Guatemala. I use duolingo to learn languages, I am not sure if you can really learn a language this way (at least I am not that smart) but it helps to practice a little, and then the compound interest should get you to some decent level. This remind me to brilliant. It is something I wanted to use, but at the end of the day, I dont have time for all things I would like to do. I need to focus in the things I really need to do.