More from Berlin:
Taktil: Very good bread!
The small piece is my own bread. You can see the difference with the air pockets and texture!


Gorilla: The same, very good bread! I bough a piece of “Hausebrot”
The small one is my my own.


Today I Learned
I tried this recipe this weekend.
Ingredients:
150g extra firm tofu (more is ok)
5-6 pieces garlic
small piece ginger
3 sticks green onion
olive oil for frying
3 tsp dark soy sauce
150g noodles (of your choice)
1 tbsp paprika (didnt have gochugaru)
1 tbsp plant-based oyster sauce (didnt use)
Process:
This is my result:

As usual, doesn’t look like the video, but it is tasty!
Meta GenAI infra: link. Interesting they have built two cluster one Ethernet and the other Infiniband, both without bottlenecks. I don’t understand if Gran Teton is where they install the NVIDIA GPUs? And for storage, I would expect something based on ZFS or similar. For performance, “We also optimized our network routing strategy”. And it is critical the “debuggability” for a system of this size. How quick you can detect a faulty cable, port, gpu, etc?
Oracle RDMA: This is an ethernet deployment with RDMA. The interesting part is the development DC-QCN (some ECN enhancement)
Cerebras WSE-3: Looks like outside NVIDIA and AMD, this is the only other option. I wonder how much you need to change your code to work in this setup? They say it is easier… I like the pictures about the cooling and racks.
Co-packaged optics: Interesting to see if this becomes a new “normal”. No more flapping links anybody? It is the fiber or replace the whole switch….
I have been watching several videos lately and I would like to be able to get a tool to give a quick summary of the video so I can have notes (and check if the tool is good). Some tools: summarize.tech, sumtubeai
video1, video2, video3, video4, video5, video6, video7, video8, video9, video10, video11
Devin and Figure01: Looks amazing and scary. I will need one robot for my dream bakery.
I wanted to “extract” some pages from different pdfs in just one file. “qpdf” looks like the tool for it.
qpdf --empty --pages first.pdf 1-2 second.pdf 1 -- combined.pdf
levulinic acid: I learnt about it from this news.
Quite overdue. I need to fill all the gaps properly
I went from Apache to NGINX to make it more challenging for me…
More details
Or try to upgrade…link:
Be sure you have Let’s Encrypt setup for getting your free. Good thing, the DNS side was already done so it was just to configure NGINX
Link.
Link. I struggled with this. I had to make a minimal config and then put my backup. After that, I had my blog fully recover
Link. I struggled here because I had to serve my blog and phpadmin from nginx. I knew how to do it via Apache but was failing with nginx. I asked ChatGPT and at the end it gave me the solution
This is the final config:
server {
server_name thomarite.uk blog.thomarite.uk;
root /var/www/html/wordpress;
index index.php;
access_log /var/log/nginx/thomarite.uk.access.log;
error_log /var/log/nginx/thomarite.uk.error.log;
client_max_body_size 100M;
location / {
try_files $uri $uri/ /index.php?$args;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/var/run/php/php8.2-fpm.sock;
include fastcgi_params;
fastcgi_intercept_errors on;
}
location /phpmyadmin/ {
alias /usr/share/phpmyadmin/;
index index.php;
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/var/run/php/php8.2-fpm.sock;
include fastcgi_params;
fastcgi_intercept_errors on;
fastcgi_param SCRIPT_FILENAME $request_filename;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
}
location ~* \.(?:svgz?|ttf|ttc|otf|eot|woff2?)$ {
add_header Access-Control-Allow-Origin "*";
expires 90d;
access_log off;
}
location ~ /\.ht {
access_log off;
log_not_found off;
deny all;
}
listen [::]:443 ssl ipv6only=on; # managed by Certbot
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/thomarite.uk-0001/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/thomarite.uk-0001/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
if ($host = blog.thomarite.uk) {
return 301 https://$host$request_uri;
} # managed by Certbot
if ($host = thomarite.uk) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
listen [::]:80;
server_name thomarite.uk blog.thomarite.uk;
location / {
return 404;
}
}
Then
sudo nginx -t sudo service nginx restart
I need to check how this is installed properly. Check this.
Another LLM course: and looks quite good. But dont think I will have time to use it.
Nice video about Gaming Latency:
How to curl an ipv6:
$ curl -v -g -k -6 'https://[2603:1061:13f1:4c06::]:443/' Trying [2603:1061:13f1:4c06::]:443... Connected to 2603:1061:13f1:4c06:: (2603:1061:13f1:4c06::) port 443 ALPN: curl offers h2,http/1.1
The destination address is indeed IPv6 anycast: 2603:1061:13f1:4c06:: (notice the “::” at the end)
According to RFC4291 https://www.rfc-editor.org/rfc/rfc4291.html#section-2.6
So it is indeed an anycast address.
According to Cisco (haven’t been able to find the RFC, haven’t looked much), this shouldn’t happen:
So how I can curl and ipv6 anycast address from MS as it were a host??
This was my standard bread for several years in London. I learnt it in BreadAhead.
75g water room temperature
75g rye flour
Mix all well, and let it at room temperature covered with a lid but not airtight. 24h in winter, 12h in summer
Starter should be active. Kind of double in size. Best test, it is take a tea spoon of starter and check if it floats in a glass of water
500g strong white flour
320g water room temperature
10g salt
150g starter
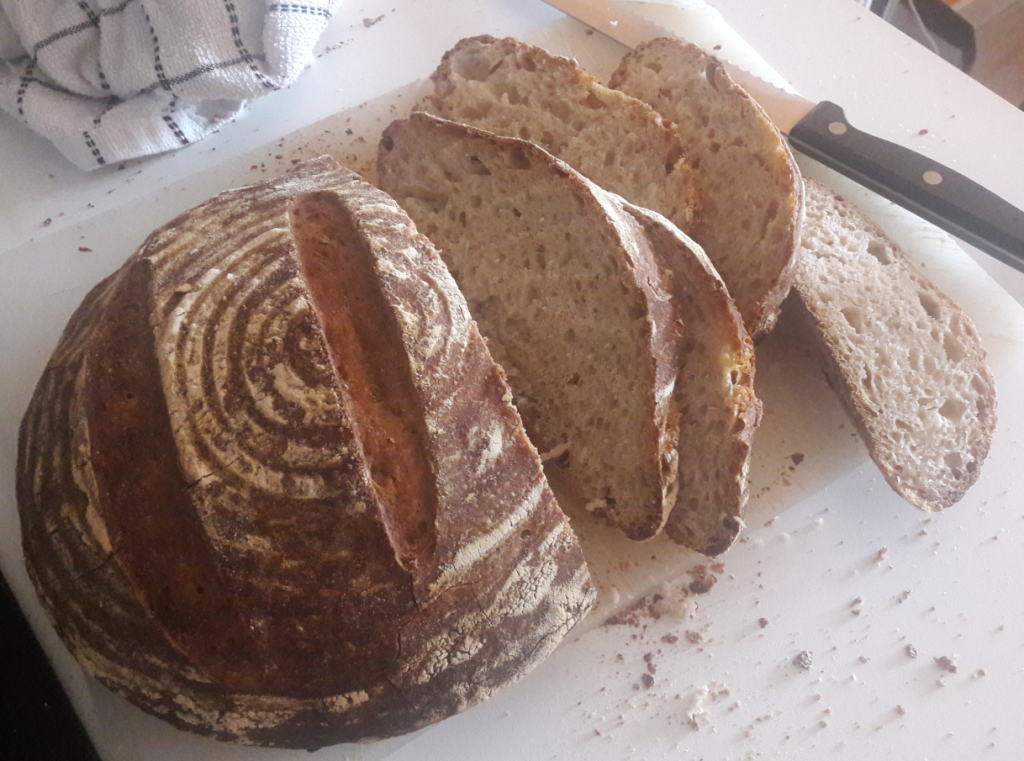
It was a good bread. I liked it and people who tried it always said good things. But never had the open spring I saw in other breads in bakeries, books and videos.
I finished this ebook yesterday. With ebooks can’t hardly take notes so in this case was a pitty but as well a bit of a relief.
Really good and better than I expected. As the title says, it is about having range, being generalist and not ultra specialized.
It gives examples where specialized (at early age) is good because it is inside a domain of well-known rules and immediate feedback like golf (Tiger Woods) and chess. It was int
But provide example of exceptional sports figures (Federer) who didnt commit to one sport to late age.
And that affects not only to sport but to your career and the research. Teams with members from different backgrounds and knowledge produce more than specialized team. It provides examples from investing to solving science problems. So it is quite shocking.
Although an early specialization will give you a head start, the general view will win in the long run. It is not bad to be very good at something, but trying different things can bring extra benefits. That’s the summary of the book.
Personally, I buy it. I like networks, but I have interests in linux, automation, hardware, baking, etc. I will never win a Nobel prize (and I dont need it) but I think it gives me from options at the end of the day. You just need to see the job descriptions where they ask for everything.
Really good book. Easy to digest and even easier to take home. And need to watch this video too. And funny enough, I was watching a bit this video too (that is quite related – interesting the investing fund points, I need to review)
I highlighted a lot of sentences in the book and I think the summary below is too long but I still take the following as basic: save, get room from error, define what you want, get your freedom.
I think he is the summary of the whole book. He was a gast station attendant, janitor and investor who was over 8m$ worth when he died.
Financial success is not a hard science. it is a soft skill, where how you behave is more important than what you know.
Finance is overwhelmingly taught as a math-based field. But knowing what to do tells you nothing about what happens in your head when you try to do it.
We think Finance follows laws like Physics but it is actually guide by people’s behaviour. And that follows to next point, how I behave may be sane for me but crazy to you.
It is easy to say a investment decision was good/bad looking back. We make money decisions based on the information we have in the moment and plugged into the unique mental model of how the world works at that moment. So yes, it can look crazy. And investing for the masses, it is actually something very new… so we are newbies, we like it or not.
Some lessons have to be experienced before they can be understood. So that can explain why looks like crazy if you haven’t gone through it.
Bill Gates won the lottery attending one of the few schools in the world with a computer.. his friend Kent Evans died in a mountaineering accident. Both sides of the same coin.
Robert Shiller (Economy Nobel Prize): What do you want to know about investing that we can’t know? The exact role of luck in successful outcomes.
So we always read about the successful people/companies (extreme cases). What proportion of these outcomes were caused by actions that are repeatable vs the role of random risk and luck? So the questions is how to identify luck and skill.
So focus less on specific individuals and case studies and more on broad patterns.
To deal with failure, arrange your financial life in a way that those situations will not wipe you out you can keep playing until the odds fall in your side (room for error…) And be able to forgive yourself when judging failures.
Nothing is as good as bad as it seems
Enough: “Yes, but I have something he will never have… enough.”
I think that is another key about “wealth”.
The hardest financial skill is getting the goalpost to stop moving.
Social comparison is the problem here.
Enough is not too little: is realizing that the opposite, an insatiable appetite for more, will make you no good.
There are many things never worth risking
There are over 2000 books written about Warren Buffer. But his success came from investing for over 75 years… His secret is time. That’s how compounding works.
Compounding is not intuitive so it is easy to ignore.
So good investment is about earning pretty good returns for the longest period of time.
Million ways to get wealthy. But just one to stay wealthy: some combination of frugality and paranoia (a.k.a survival). So getting money and keeping money are two totally different skills.
I like the note about Jesse Livermore (I read that book some time ago). He made the biggest fortune ever during the crash of 1929.
And another quote from Nassim Taleb: Having an edge and surviving are two different things: the first requires the second. You need to avoid ruin. At all costs.
Be financially unbreakable: you will get the biggest returns, because you will be able to stick around long enough for compounding to run its magic.
The most important part of every plan is to plan on the plan not going according to plan (a.k.a backup plan or room for error). A plan is only useful if it can survive reality. And a future filled with unknowns is everybody’s reality. So it is anything that lets you live happily with a range of outcomes.
Conservative is avoiding a certain level of risk. Room of error or margin of safety is raising the odds of success at a given level of risk by increasing your chances of survival. This is something I think I understand but I need some clear examples in my head.
Optimistic about the future but paranoid about what will prevent you from getting to the future is vital: Being pessimistic is too easy.
Another interesting notes about Heinz Berggruen. The great investors bought vast quantities of art. A subset of the collections turned out to be great investments, and they were held for a sufficiently long period of time to allow the portfolio return to converge on the return of the best elements. That’s all that happens.
Anything that is huge, profitable, famous or influential, is the result of a tail event (Walt Disney, Brad Pitt winning an award, Venture Capitals, AWS, iPhone, MicroSoft, etc). Tails drive everything.
Same in different ways: Few things account for most results (I think this is the easiest one to understand)
Military genius based on Napoleon: The man who can do the average thing when all those around him are going crazy. So that applied to investing is, most of the time today is not that important. What matters are those number of days where everybody is going crazy… so what do you do???
George Soros: It is not whether you are right or wrong that’s important, but how much money you make when you are right and how much you lose when you are wrong. You can be wrong halt of the time and still make a fortune.
Controlling your time is the highest dividend money pays: control over doing what you want, when you want, with the people you want to, is the broadest lifestyle variable that makes people happy. Using your money to buy time and options has a lifestyle benefit that few luxury good can compete with. Most stuff we buy, means giving away most control of our time.
Most workforce today are not “labored” so we need to use our head, and it is not that easy to switch off, so we are constantly working with our heads, and then we are losing control over our time.
No one is impressed with your possessions as much as you are. Humility, kindness and empathy will bring you more respect than a Ferrari.
Spending money to show off, it is the fastest way to have less money. Wealth is an option not yet taken to buy something later. It requires self-control. And because it is hidden, we have few models to learn from. It is much easier to follow the instagram show-off.
For me this is they key of everything, without savings few things you can do.
Building wealth is more related to your saving rate than income or investment returns.
The value of wealth is relative to what you need: high savings rate -> having lower expenses.
One of the most powerful ways to increase your savings is not to raise your income, it is to raise your humility: what you need is just what sits below you ego. Dont care about what others thing about you (and not just about money!)
You spend less, if you desire less, then you care less about others -> so that goes back to the title of the book… money relies more on psychology than finance.
You dont need any specific reason to save (car, house, holidays, etc): Savings without a spending goal gives you options and flexibility: ability to wait and opportunity to act = time for thinking. And that flexibility and control over your time is an unseen return on wealth. Savings at 0% earn rate can give you more in the sense of taking a lower pay and more satisfying job than you can think.
Intelligence is no longer a sustainable advantage (software eats the world). Competitive advantages tilt toward nuanced and soft skills: flexibility is a main one. Again, it is being able to wait for a good opportunity (career, investment, etc). So having more control over your time and options is one of the most valuable currencies in the world: Just Save it.
Aiming to be mostly reasonable works better than trying to be coldly rational. Reasonable is more realistic and you have a better chance of sticking with it for the long run, which is what matters at investing. Think of the fever. It is beneficial, but we fight it because it hurts! Minimizing future regret is hard to rationalize on paper but easy to justify in real life.
History is the study of change, is not a map of the future.
Scott Sagan: Things that have never happened before happen all the time.
Investing is a hard science. People making imperfect decisions with limited information.
The majority of what’s happening at any given moment in the global economy can be tied back to a handful of past events that were nearly impossible to predict.
History can be a misleading guide to the future of the economy and investment because it doesnt take into account the structural changes of today. For example, when did venture capital start? Before there was only (if lucky) risk aversed bankers.
Historians are not prophets. Things change.
The most important part of every plan is planning on your plan not going according to plan. This similar to an earlier point.
Kevin Lewis from Bringing Down the House: We have enough money to withstand any swings of bad luck (so you can fight another day)
Benjamin Graham: The purpose o the margin of safety is to render the forecast unnecessary.
Unknowns are always part of life.
Having a gap between what you can technically endure versus what you can emotionally endure is an overlooked version of room for error. Use room for error when estimating your future returns.
Charlie Munger: The best way to achieve felicity is to aim low. (and a paper)
Nassim Taleb: You can be risk loving and yet completely averse to ruin. If you have 95% chance to be right, be sure that the other 5% is not going to wipe you out.
Back to an earlier chapter, it is important to safe for the sake of it, for the unknowns.
Long-term planning is harder than it seems because people’s goals and desires change over time. We are poor forecasters of our future selves. We really underestimate how much we will change.
So avoid the extreme ends of financial planning (expending everything vs saving everything)
Accept the reality of change and move on as soon as possible.
Charlie Munger first rule of compounding is to never interrupt it unnecessarily.
End of History Illusion: is a psychological illusion in which individuals of all ages believe that they have experienced significant personal growth and changes in tastes up to the present moment, but will not substantially grow or mature in the future.[1] Despite recognizing that their perceptions have evolved, individuals predict that their perceptions will remain roughly the same in the future.
Daniel Kahneman: “I have no sunk costs”. book
Everything has a price even if you don’t see it.
You usually get what you pay for. Same for markets. The volatility/uncertainty fee (the price of returns) is the cost of admission to get returns greater than low-fee investments (ie: money in the bank, etc). Ticket to Disneyland vs local fair. You need to convince yourself the market’s fee is worth it. So find the price, then pay it.
This relates to point 1 “Nobody is crazy”. This relates to economy bubbles too. The assets have one rational prize in a world where investors have different goals and time horizons. And that can trigger bubbles, when the momentum of short-term returns attracts enough money that the makeup of investors shifts from mostly long term to mostly short term. Then the process feeds itself on and on until it can’t be maintained. So find which game you are playing.
Optimism is the best bet for most people because the world tends to get better for most people most of the time.
Optimism is a belief that the odds of a good outcome are in your favor over time, even when there will be setbacks along the way.
But Pessimism sounds smarter and gets more attention. why?
Based on Daniel Kahneman: It is the asymmetric aversion to loss in the evolution: losses loom larger than gains. Organisms that treat threats as more urgent than opportunities have a better chance to survive and reproduce.
And again relates to point 1 “nobody’s crazy”.
As well, bad news about economy can affects everybody so you pay attention.
Progress happens too slowly to notice but setbacks happen too quickly to ignore.
And finally, expecting things to be bad is the best way to be pleasantly surprised when they are not.
Stories are the most powerful force in the economy. Imagine venture capitalist that put money in things dont exist…. Another example in 2009, when we stopped believing house prices would keep rising.
The more you want something to be true, the more likely you are to believe a story that overestimates the odds of it being true. For protecting you about that, you need a bigger gap between what you want to be true and what you need to be true to have an acceptable outcome.
Everyone has an incomplete view of the world. But we form a complete narrative to fill the gapgs.
Daniel Kahneman: The ability to explain the past, gives us the illusion that the world is understandable. It gives the illusion that the world makes sense, even when it doesnt. And that produces big mistakes.
To be h
I wanted to cook risotto and i noticed that i didnt remember how to do it /o\ although I had the ingredients…
Found this video, looked nice, so went for it.
This is my result:

Some years ago, I tried an amazing roasted cauliflower in a roof top, and wanted to try one day. I watched this video and then I had to do it.
INGREDIENTS
Whole cauliflower head
Cooking liquid
2 cups cheat white wine
2 cups veggoe stock
3 tbsp olive oil
2 tsp white wine vinegar
2 tbsp brown sugar
5 cloves garlic, slightly crushed
2 bay leaves
1 onion, in quarters
salt and pepper
Flavor Paste
Garnish
DIRECTIONS
– Mix Cooking Liquid ingredients in a large stockpot and bring to a boil
– Once boiling, reduce heat to medium low and place cauliflower head in the pot and baste with a ladle once or twice as it cooks covered for 10-15 min.
– Preheat oven to 180C. Convection setting on if you have that option.
– While cauliflower is steaming in the stockpot, mix Flavor Paste ingredients in a small bowl.
– After cauliflower has cooked in the stockpot for 10-15 min, remove and transfer to a baking sheet with a raised grate.
– Spoon and spread Flavor Paste all over cauliflower head. Spray lightly with olive oil.
– Place cauliflower in preheated oven for about 30 min.
– Remove from oven and grate parmesan cheese all over and spray again lightly with olive oil
– Place in oven for another 15-20 min or until deep golden brown.
– Transfer to serving platter and garnish with fresh chopped parsley and enjoy!
And this is my result:

My coating wasnt great and I had it for lunch next day so it wasn’t the same, but still it was good. And as usual, room for improvement!
Still It is not the same roasted cauliflower I had that time…. need to do proper research.