I am trying to learn a bit of golang (although sometimes I think I should try to master python and bash first..) with this udemy course.
The same way I have pyenv/virtualenv to create python environments, I want to do the same for golang. So for that we have goenv:
Based on goenv install instructions and ex-collegue snipset, this is my goenv snipset in .bashrc:
########################
# Go configuration
########################
#
# git clone -b v0.0.4 https://github.com/wfarr/goenv.git $HOME/.goenv
if [ ! -d "$HOME/.goenv" ]; then
git clone https://github.com/syndbg/goenv.git $HOME/.goenv
fi
if [ -d "$HOME/.goenv" ]
then
export GOENV_ROOT="$HOME/.goenv"
export PATH="$GOENV_ROOT/bin:$PATH"
if type "goenv" &> /dev/null; then
eval "$(goenv init -)"
# Add the version to my prompt
__goversion (){
if type "goenv" &> /dev/null; then
goenv_go_version=$(goenv version | sed -e 's/ .*//')
printf $goenv_go_version
fi
}
#PS1_GO="go:\$(__goversion) "
export PS1="go:\$(__goversion)|$PS1"
export PATH="$GOROOT/bin:$PATH"
export PATH="$PATH:$GOPATH/bin"
fi
fi
################## End GoLang #####################
From time to time, remember to go to ~.goenv and do a “git pull” to get the latest versions of golang.
Ok, once we can install any golang version, I was thinking about the equivalent to python virtualenv, but it seems it is not really needed in golang. At the moment, I am super beginner so no rush about this.
And finally, as I try to use VIM for everything so I can keep learning, I want to use similar python plugins for golang. So I searched and this one looks quite good: vim-go
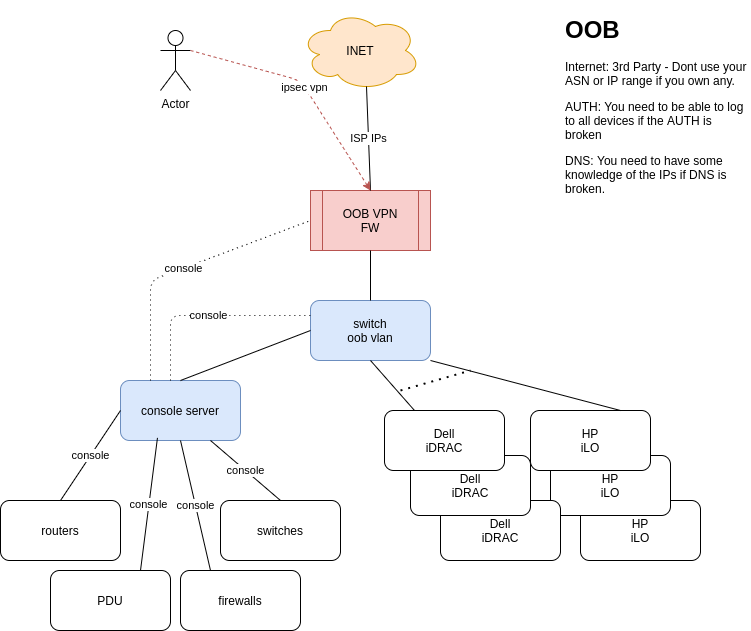
I was reading this blog and realised that OOB is something is not talked about very often. Based on what I have seen in my career:
Design
You need to sell the idea that this is a must. Then you need to secure some budget. You dont need much:
1x switch
1x firewall
1x Internet access (if you have your ASN and IP range, dont use it)
Keep it simple..
Most network kit (firewalls, routers, switches, pdus, console servers, etc) have 1xmgmt port and 1xconsole port. So all those need to go to the console server. I guess most server vendors offer some OOB access (I just know Dell and HP). So all those go to the oob switch.
If you have a massive network with hundreds of devices/servers, then you will need more oob switches and console servers. You still need just one firewall and 1 internet connection. The blog comments about the spine-leaf oob network. I guess this is the way for a massive network/DC.
Access to OOB
You need to be able to access it via your corporate network and from anywhere in the internet.
You need to be sure linux/windows/macs can VPN.
Use very strong passwords and keys.
You need to be sure the oob firewall is quite tight in access. At the end of the day you only want to allow ssh to the console server and https to the ILO/iDRACS. Nothing initiated internally can go to the internet.
Dependencies
Think in the worse scenario. Your DNS server is down. Your authentication is down.
You need to be sure you have local auth enabled in all devices for emergency
You need to work out some DNS service. Write the key IPs in the documentation?
You IP transit has to be reliable. You dont need a massive pipe but you need to be sure it is up.
Monitoring
You dont want to be in the middle of the outage and realise that your OOB is not functional. You need to be sure the ISP for the OOB is up and the devices (oob switch and oob firewall) are functional all the time.
Another point frequently lost. You need to be sure people can find info about the OOB: how is built and how to access it.
Training
At the end of the day, if you have a super OOB network but then nobody knows how to connect and use it, then it is useful. Schedule routine checkups with the team to be sure everybody can OOB. This is useful when you get a call at 3am.
Diagram
Update
Funny enough, I was watching today NLNOG live and there was a presentation about OOB with too different approaches: in-band out-of-band and pure out-of-band.
From the NTT side, I liked the comment about conserver.com to manage your serial connections. I will try to use it once I have access to a new network.
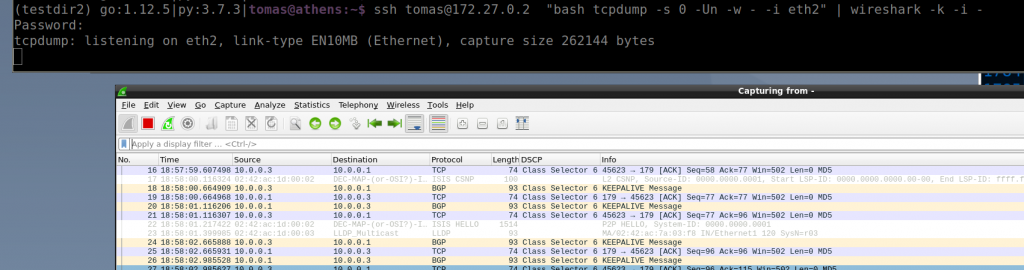
Reading this blog entry I realised that very likely I have never tried forward tcpdump to a wireshark. How many times I have taken a pcap in a switch and then I need to download to see the details in wireshark…
I guess you can find some blocking points in firewalls (at least for 2-steps option)
So I tried the single command with a switch in my ceoslab and it works!
The ssh command is actually executing the “bash tcpdump…” remotely. But the key is the “-U” and “-w -” flags. “-U” in conjunction with “-w” sends the packet without waiting for the buffer to fill. Then “-w -” says that it writes the output to stdout instead of a file. If you run the command without -U, it would work but it will update a bit slower as it needs to fill the buffers.
From tcpdump manual:
-U
--packet-buffered
If the -w option is not specified, make the printed packet output ``packet-buffered''; i.e., as the description of the contents of each packet is printed, it will be written to the standard output, rather than, when not writing to a terminal, being written only when the output buffer fills.
If the -w option is specified, make the saved raw packet output ``packet-buffered''; i.e., as each packet is saved, it will be written to the output file, rather than being written only when the output buffer fills.
The -U flag will not be supported if tcpdump was built with an older version of libpcap that lacks the pcap_dump_flush() function.
......
-w file
Write the raw packets to file rather than parsing and printing them out. They can later be printed with the -r option. Standard output is used if file is ``-''.
This output will be buffered if written to a file or pipe, so a program reading from the file or pipe may not see packets for an arbitrary amount of time after they are received. Use the -U flag to cause packets to be written as soon as they are received.
And the stdout of that process is the ssh command so we redirect that outout via a pipe “|” and it is sent as input for wireshark thanks to “-i -” that makes wireshark to read from stdin (that is the stdout from the tcpdump in the switch!)
The wireshark manual:
-i|--interface <capture interface>|-
Set the name of the network interface or pipe to use for live packet capture.
Network interface names should match one of the names listed in "wireshark -D" (described above); a number, as reported by "wireshark -D", can also be used. If you're using UNIX, "netstat -i", "ifconfig -a" or "ip link" might also work to list interface names, although not all versions of UNIX support the -a flag to ifconfig.
If no interface is specified, Wireshark searches the list of interfaces, choosing the first non-loopback interface if there are any non-loopback interfaces, and choosing the first loopback interface if there are no non-loopback interfaces. If there are no interfaces at all, Wireshark reports an error and doesn't start the capture.
Pipe names should be either the name of a FIFO (named pipe) or "-" to read data from the standard input. On Windows systems, pipe names must be of the form "\\pipe\.\pipename". Data read from pipes must be in standard pcapng or pcap format. Pcapng data must have the same endianness as the capturing host.
This option can occur multiple times. When capturing from multiple interfaces, the capture file will be saved in pcapng format.
....
-k Start the capture session immediately. If the -i flag was specified, the capture uses the specified interface. Otherwise, Wireshark searches the list of interfaces, choosing the first non-loopback interface if
there are any non-loopback interfaces, and choosing the first loopback interface if there are no non-loopback interfaces; if there are no interfaces, Wireshark reports an error and doesn't start the capture.
The two-steps option relies on “nc” to send/receive the data, but it is the same idea regarding the tcpdump/wireshark flags using “-“
$ sudo modprobe bonding
$ ip link help bond
$ sudo ip link add bond0 type bond mode 802.3ad
$ sudo ip link set eth0 master bond0
$ sudo ip link set eth1 master bond0
Bridging: vlans + trunks
ip neigh show // l2 table
ip route show // l3 table
ip route add default via 192.168.1.1 dev eth1
sudo modprobe 8021q
// create bridge and add links to bridge (switch)
sudo ip link add br0 type bridge vlan_filtering 1 // native vlan = 1
sudo ip link set eth1 master br0
sudo ip link set eth2 master br0
sudo ip link set eth3 master br0
// make eth1 access port for v11
sudo bridge vlan add dev eth1 vid 11 pvid untagged
// make eth3 access port for v12
sudo bridge vlan add dev eth3 vid 12 pvid untagged
// make eth2 trunk port for v11 and v12
sudo bridge vlan add dev eth2 vid 11
sudo bridge vlan add dev eth2 vid 12
// enable bridge and links
sudo ip link set up dev br0
sudo ip link set up dev eth1
sudo ip link set up dev eth2
sudo ip link set up dev eth3
bridge link show
bridge vlan show
bridge fdb show
VxLAN
I havent tried this yet:
Linux System 1
sudo ip link add br0 type bridge vlan_filtering 1
sudo ip link add vlan10 type vlan id 10 link bridge protocol none
sudo ip addr add 10.0.0.1/24 dev vlan10
sudo ip link add vtep10 type vxlan id 1010 local 10.1.0.1 remote 10.3.0.1 learning
sudo ip link set eth1 master br0
sudo bridge vlan add dev eth1 vid 10 pvid untagged
Linux System 2
sudo ip link add br0 type bridge vlan_filtering 1
sudo ip link add vlan10 type vlan id 10 link bridge protocol none
sudo ip addr add 10.0.0.2/24 dev vlan10
sudo ip link add vtep10 type vxlan id 1010 local 10.3.0.1 remote 10.1.0.1 learning
sudo ip link set eth1 master br0
sudo bridge vlan add dev eth1 vid 10 pvid untagged
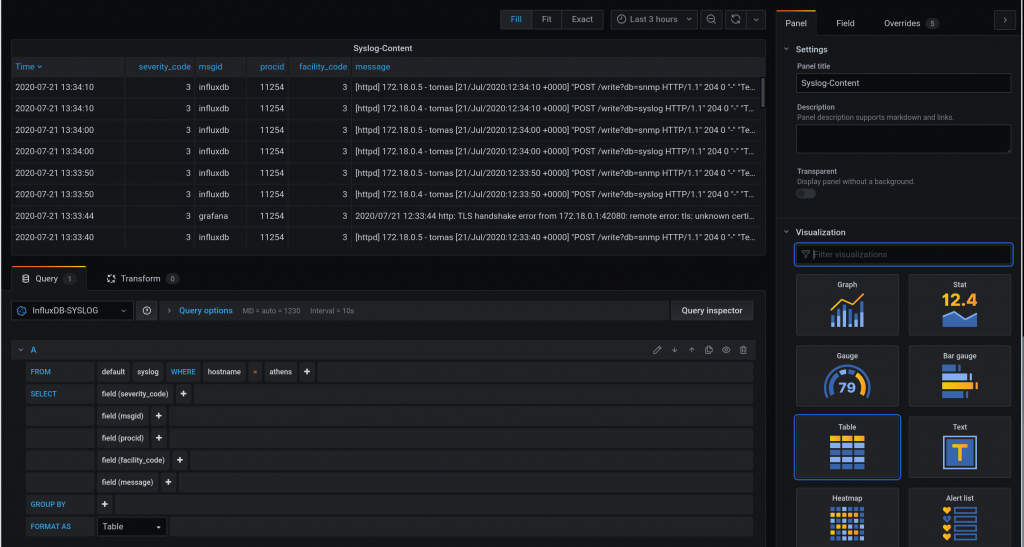
This a continuation of the last blog entry. This time we are going to gather syslog messages from the monitoring containers and it is going to be deployed by ansible!
As usual, all this is based on Anton’s Karneliuk blog post. All credits to him.
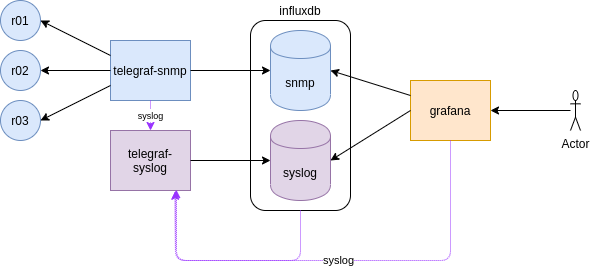
So initially we built a monitoring stack with InfluxDB, Telegraf and Grafana manually to gather and visualise SNMP infor form the Arista cEOS switches.
This time, we are going to send SYSLOG from the monitoring stack containers to a new Telegraf instance.
Ideally, we would like to send Syslog from the cEOS devices but as Anton mentions, the syslog rfc3164 that most network kit implements, it is not supported (yet) by telegraf, that supports rfc5424.
You can read more info about this in all these links:
The very first time, if you pay attention to the ansible logging, everything should success. If for any reason you have to make changes or troubleshoot, and execute again the full playbook, some tasks will fail, but not the playbook (this is done with ignore_errors: yes inside a task). For example, the docker network creation will fail as it is already there. The same if you try to create the user and dbs in a already running influx instance.
That playbook just calls the role “monitoring_stack“. The main playbook in that role will create the docker network where all containers will be attached, all the containers and do something hacky with iptables.
As the cEOS lab is built (using docker-topo) independently of this playbook, there are already some iptables rules in place, and somehow, when executing the role, the rules change and it blocks the new network for any outbound connectivity.
Before the iptables change in the playbook:
# iptables -t filter -S DOCKER-ISOLATION-STAGE-1
Warning: iptables-legacy tables present, use iptables-legacy to see them
-N DOCKER-ISOLATION-STAGE-1
-A DOCKER-ISOLATION-STAGE-1 -i br-4bd17cfa19a8 ! -o br-4bd17cfa19a8 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i br-94c1e813ad6f ! -o br-94c1e813ad6f -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-13ab2b6a0d1d ! -o br-13ab2b6a0d1d -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-00db5844bbb0 ! -o br-00db5844bbb0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-121978ca0282 ! -o br-121978ca0282 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
#
# iptables -t filter -S DOCKER-ISOLATION-STAGE-2
Warning: iptables-legacy tables present, use iptables-legacy to see them
-N DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-2 -o br-4bd17cfa19a8 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-94c1e813ad6f -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-13ab2b6a0d1d -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-00db5844bbb0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-121978ca0282 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
I want to avoid DOCKER-ISOLATION-STAGE-2 so I want the “-A DOCKER-ISOLATION-STAGE-1 -j ACCEPT” on top of that chain.
This is not the first (neither last) time that this issue bites me. I need to review carefully the docker-topo file and really get me head around the networking expectations from docker.
Another thing about docker networking that bites me very often. In my head, each monitoring has an IP. For example influxdb is 172.18.0.2 and telegraf-syslog is 172.18.0.4. We have configured influxdb to send syslog to telegraf-syslog container so I would expect the influxdb container to use its 0.2 and everything is local (no forwarding, no firewall, etc0. But not, it uses the host ip, 172.18.0.1.
Apart from that, there are several things that I had to review while adapting the role to my environment regarding docker and ansible.
docker documentation:
how to create network: https://docs.docker.com/engine/reference/commandline/network_create/
how to configure container logs: https://docs.docker.com/engine/reference/commandline/container_logs/
how to configure the logging driver in a container: https://docs.docker.com/config/containers/logging/configure/
how to configure syslog in a container: https://docs.docker.com/config/containers/logging/syslog/
how to run commands from a running container: https://docs.docker.com/engine/reference/commandline/exec/
ansible documentation:
become – run comamnds with sudo in a playbook: https://docs.ansible.com/ansible/latest/user_guide/become.html (–ask-become-pass, -K)
grafana data source module: https://docs.ansible.com/ansible/latest/modules/grafana_datasource_module.html
This is important because via ansible, I had to workout the meaning of become, how to add the syslog config in the containers and add grafana datasources via a module.
This is something I wanted to try for some time. Normally for networks monitoring you use a NMS tool. They can be expensive, free or cheap. I have seen/used Observium and LibreNMS. And many years ago Cacti. There are other tools that can do the job like Zabbix/Nagios/Icinga.
But it seems time-series-databases are the new standard. They give you more flexibility as you can create queries and graph them.
I decided for InfluxDB-Telegraf-Grafana stuck as I could find quickly info based on scenarios of networks.
What is the rule of eachc one:
Telegraf: collect data InfluxDB: store data Grafana: visualize
My main source is again Anton’s blog. All credits to him.
Environment
My network is just 3 Arista ceos containers via docker. All services will run as containers so you need docker installed. Everything is IPv4.
InfluxDB
Installation:
// Create directories
mkdir telemetry-example/influxdb
cd telemetry-example/influxdb
// Get influxdb config
docker run --rm influxdb influxd config > influxdb.conf
// Create local data folder for influxdb that we will map
mkdir data
ls -ltr
// Check docker status
docker images
docker ps -a
// Create docker instance for influxdb. Keep in mind that I am giving a name to the instance
docker run -d -p 8086:8086 -p 8088:8088 --name influxdb \
-v $PWD/influxdb.conf:/etc/influxdb/influxdb.conf:ro \
-v $PWD/data:/var/lib/influxdb \
influxdb -config /etc/influxdb/influxdb.conf
// Verify connectivity
curl -i http://localhost:8086/ping
// Create database "test" using http-query (link below for more details)
curl -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE test"
{"results":[{"statement_id":0}]} <-- command was ok!
// Create user/pass for your db.
curl -XPOST http://localhost:8086/query --data-urlencode "q=CREATE USER xxx WITH PASSWORD 'xxx123' WITH ALL PRIVILEGES"
{"results":[{"statement_id":0}]} <-- command was ok!
// Create SSL cert for influxdb
docker exec -it influxdb openssl req -x509 -nodes -newkey rsa:2048 -keyout /etc/ssl/influxdb-selfsigned.key -out /etc/ssl/influxdb-selfsigned.crt -days 365 -subj "/C=GB/ST=LDN/L=LDN/O=domain.com/CN=influxdb.domain.com"
// Update influxdb.conf for SSL
telemetry-example/influxdb$ vim influxdb.conf
…
https-enabled = true
https-certificate = "/etc/ssl/influxdb-selfsigned.crt"
https-private-key = "/etc/ssl/influxdb-selfsigned.key"
…
// Restart influxdb to take the changes
docker restart influxdb
// Get influxdb IP for using it later
docker container inspect influxdb --format='{{ .NetworkSettings.IPAddress }}'
172.17.0.2
// Verify connectivity via https
curl -i https://localhost:8086/ping --insecure
The verification for HTTPS was a bit more difficult because the result was always correct no matter what query I was running:
So I decided to see if there was cli/shell for the influxdb (like in mysql, etc). And yes, there is one. Keep in mind that you have to use “-ssl -unsafeSsl” at the same time! That confused me a lot.
$ docker exec -it influxdb influx -ssl -unsafeSsl
Connected to https://localhost:8086 version 1.8.1
InfluxDB shell version: 1.8.1
> show databases
name: databases
name
_internal
test
> use test
Using database test
> show series
key
cpu,cpu=cpu-total,host=5f7aa2c5550e
Links about influxdb that are good for the docker creation and the http queries:
// Create dir
mkdir telemetry-example/telegraf
cd telemetry-example/telegraf
// Get config file to be modified
docker run --rm telegraf telegraf config > telegraf.conf
// Add the details of influxdb in telegraf.conf. As well, you need to add the devices you want to poll. In my case 172.23.0.2/3/4.
vim telegraf.conf
....
[[outputs.influxdb]]
urls = ["https://172.17.0.2:8086"]
database = "test"
skip_database_creation = false
## Timeout for HTTP messages.
timeout = "5s"
## HTTP Basic Auth
username = "xxx"
password = "xxx123"
## Use TLS but skip chain & host verification
insecure_skip_verify = true
# Retrieves SNMP values from remote agents
[[inputs.snmp]]
## Agent addresses to retrieve values from.
## example: agents = ["udp://127.0.0.1:161"]
## agents = ["tcp://127.0.0.1:161"]
agents = ["udp://172.23.0.2:161","udp://172.23.0.3:161","udp://172.23.0.4:161"]
#
## Timeout for each request.
timeout = "5s"
#
## SNMP version; can be 1, 2, or 3.
version = 2
#
## SNMP community string.
community = "tomas123"
#
## Number of retries to attempt.
retries = 3
This is the SNMP config I added below the SNMPv3 options in [[inputs.snmp]]
# ## Add fields and tables defining the variables you wish to collect. This
# ## example collects the system uptime and interface variables. Reference the
# ## full plugin documentation for configuration details.
[[inputs.snmp.field]]
name = "hostname"
oid = "RFC1213-MIB::sysName.0"
is_tag = true
[[inputs.snmp.field]]
name = "uptime"
oid = "DISMAN-EVENT-MIB::sysUpTimeInstance"
# IF-MIB::ifTable contains counters on input and output traffic as well as errors and discards.
[[inputs.snmp.table]]
name = "interface"
inherit_tags = [ "hostname" ]
oid = "IF-MIB::ifTable"
# Interface tag - used to identify interface in metrics database
[[inputs.snmp.table.field]]
name = "ifDescr"
oid = "IF-MIB::ifDescr"
is_tag = true
# IF-MIB::ifXTable contains newer High Capacity (HC) counters that do not overflow as fast for a few of the ifTable counters
[[inputs.snmp.table]]
name = "interfaceX"
inherit_tags = [ "hostname" ]
oid = "IF-MIB::ifXTable"
# Interface tag - used to identify interface in metrics database
[[inputs.snmp.table.field]]
name = "ifDescr"
oid = "IF-MIB::ifDescr"
is_tag = true
# EtherLike-MIB::dot3StatsTable contains detailed ethernet-level information about what kind of errors have been logged on an interface (such as FCS error, frame too long, etc)
[[inputs.snmp.table]]
name = "interface"
inherit_tags = [ "hostname" ]
oid = "EtherLike-MIB::dot3StatsTable"
# Interface tag - used to identify interface in metrics database
[[inputs.snmp.table.field]]
name = "name"
oid = "IF-MIB::ifDescr"
is_tag = true
For more info about the SNMP config in telegraf. These are good links. This is the official github page. And this is the page for SNMP input plugin that explain the differences between “field” and “table”.
As well, the link below is really good too for explaining the SNMP config in telegraf:”Gathering Data via SNMP”
docker logs telegraf -f
...
2020-07-17T12:45:10Z E! [inputs.snmp] Error in plugin: initializing table interface: translating: exit status 2: MIB search path: /root/.snmp/mibs:/usr/share/snmp/mibs:/usr/share/snmp/mibs/iana:/usr/share/snmp/mibs/ietf:/usr/share/mibs/site:/usr/share/snmp/mibs:/usr/share/mibs/iana:/usr/share/mibs/ietf:/usr/share/mibs/netsnmp
Cannot find module (EtherLike-MIB): At line 0 in (none)
EtherLike-MIB::dot3StatsTable: Unknown Object Identifier
...
You will see errors about not able to find the MIB files! So I used Librenms mibs. I download the project and copied the MIBS I thought I needed (arista and some other that dont belong to a vendor). As well, this is noted by Anton’s in this link:
I have seen Grafana before but I have never used it so the configuration on queries was a bit of a challenge but I was lucky and I found very good blogs for that. The installation process is ok:
// Create folder for grafana and data
mkdir -p telemetry-example/grafana/data
cd telemetry-example/grafana
// Create docker instance
docker run -d -p 3000:3000 --name grafana \
--user root \
-v $PWD/data:/var/lib/grafana \
grafana/grafana
// Create SSL cert for grafana
docker exec -it grafana openssl req -x509 -nodes -newkey rsa:2048 -keyout /etc/ssl/grafana-selfsigned.key -out /etc/ssl/grafana-selfsigned.crt -days 365 -subj "/C=GB/ST=LDN/L=LDN/O=domain.com/CN=grafana.domain.com"
// Copy grafana config so we can update it
docker cp grafana:/etc/grafana/grafana.ini grafana.ini
// Update grafana config with SSL
vim grafana.ini
############################## Server
[server]
# Protocol (http, https, h2, socket)
protocol = https
…
# https certs & key file
cert_file = /etc/ssl/grafana-selfsigned.crt
cert_key = /etc/ssl/grafana-selfsigned.key
// Copy back the config to the container and restart
docker cp grafana.ini grafana:/etc/grafana/grafana.ini
docker container restart grafana
Now you can open in your browser to grafana “https://0.0.0.0:3000/ ” using admin/admin
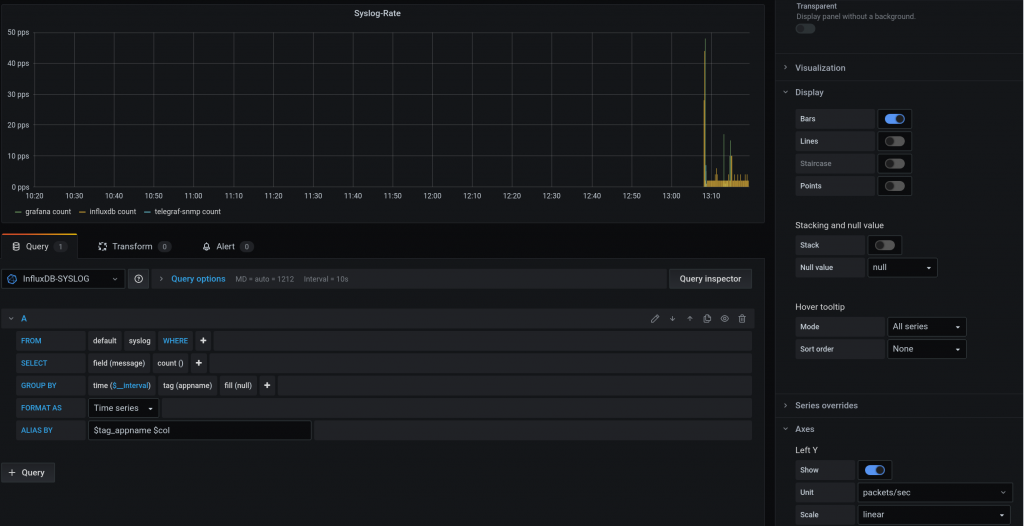
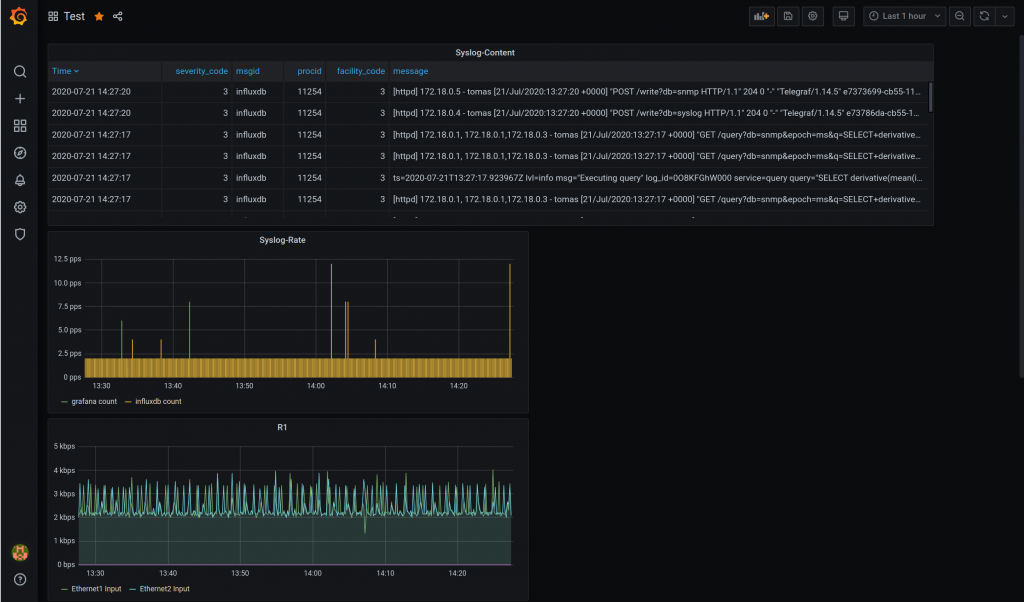
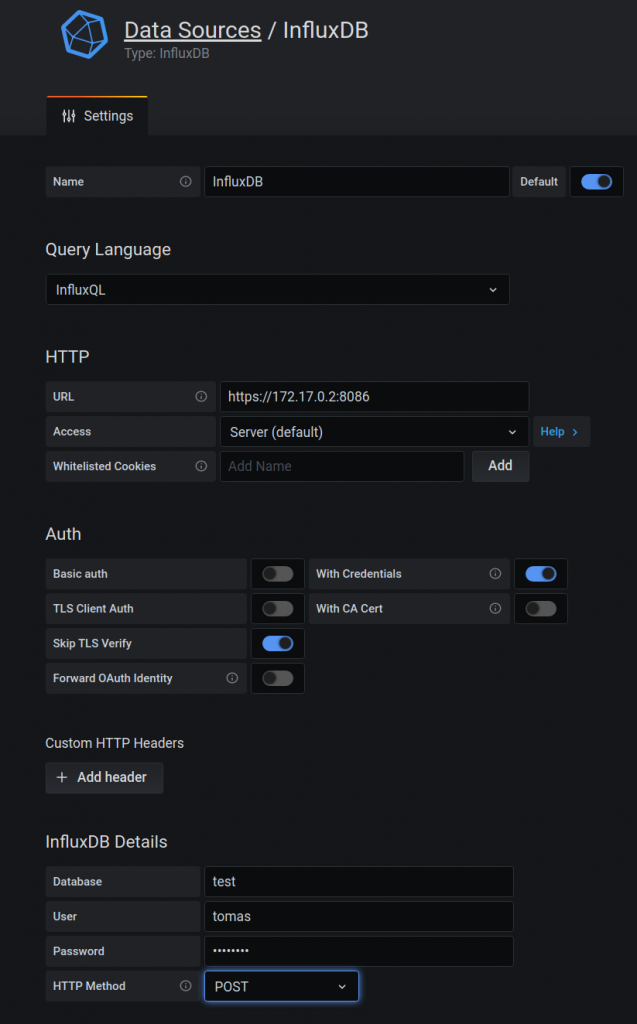
You need to add a data source that is our influxdb container. So you need to pick up the “influxdb” type and fill the values as per below.
Now, you need to create a dashboard with panel.
Links that I reviewed for creating the dasbord
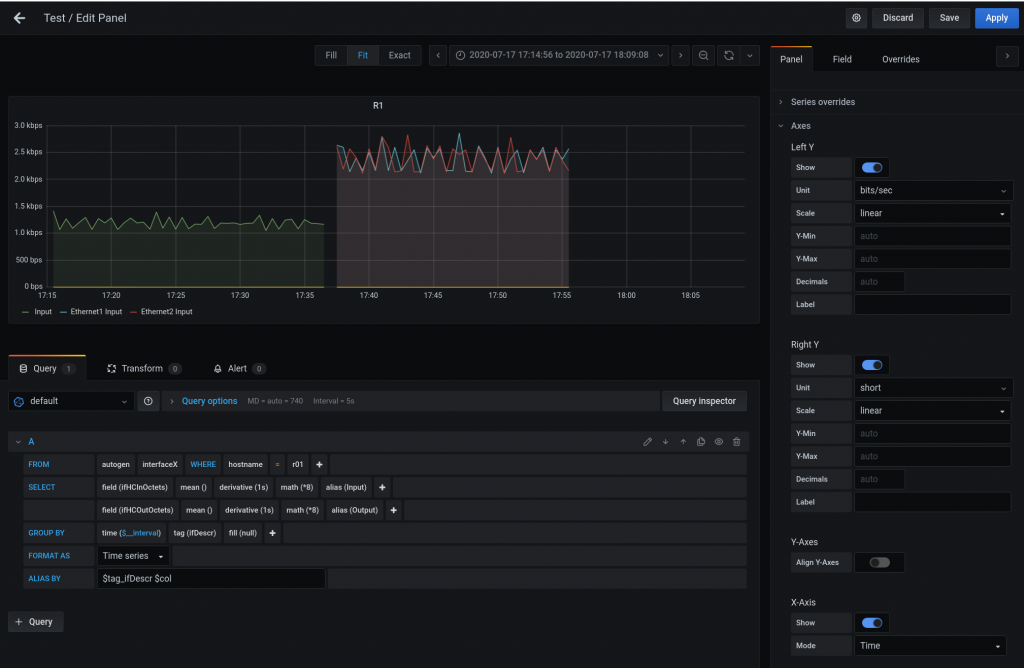
For creating a panel. The link below was the best on section “Interface Throughput”. Big thanks to the author.
BTW, you need to config SNMP in the switches so telegraf can poll it:
snmp-server location ceoslab
snmp-server community xxx123 ro
snmp-server host 172.17.0.1 version 2c xxx123
In my case, the stack of containers Influx-Telegraf-Grafana are running on the default bridge. Each container has its own IP but as the Arista containers are in the different docker network, it needs to “route” so the IP of telegraf container will be NAT-ed to 172.17.0.1 from the switches point of view.
Next
I would like to manage all this process via Ansible… Something like this.. but will take me time
In the past, I have had to use Centos systems a lot at work and there was something I really liked from rpm, it is “yum provides” that tells you which package you need to install based on the command you need.
I always struggle to do that in Debian. I hope I remember it for the next time. Based on this link:
# aptitude install apt-file
# apt-file update
# apt-file search snmpwalk
libnet-snmp-perl: /usr/share/doc/libnet-snmp-perl/examples/snmpwalk.pl
libsnmp-session-perl: /usr/share/doc/libsnmp-session-perl/examples/snmpwalkh.pl
python3-pysnmp4-apps: /usr/bin/pysnmpwalk
python3-pysnmp4-apps: /usr/share/man/man1/pysnmpwalk.1.gz
snmp: /usr/bin/snmpwalk <=== THIS IS WHAT I WANT !!!!
snmp: /usr/share/man/man1/snmpwalk.1.gz
snmpsim: /usr/share/doc/snmpsim/examples/data/foreignformats/linux.snmpwalk.gz
snmpsim: /usr/share/doc/snmpsim/examples/data/foreignformats/winxp1.snmpwalk.gz
# aptitude install snmp
Today I was trying to write a playbook to push config to Arista devices.
Initially I wanted to use napalm module to push the config (as I have done with nornir) but it seems the napalm-ansible module requires napalm3 and netmiko3 and that breaks my nornir2.4 ( that requires napalm<3) So I uninstalled napalm-ansible and restored the other packages. Good thing i chekced the version before hand.
So I had to check the eos_config module. I think the napalm-ansible module is more powerful as it uses diff and sessions provided by Arista. As far as I can see, there is no option to say to the module to just make a dry run.
At the end I managed to put everything together but the eos_config was failing:
So I had to find out where that task was looking for the file. It seems “assemble“, “template” and “file” tasks use as pwd where I am calling the script (xxx/testdir2/ceos-testing/ansible). But “eos_config” is using where the playbook is (xxx/testdir2/ceos-testing/ansible/playbook) based on my running command “…/ansible master$ ansible-playbook playbooks/gen-config.yaml“.
So I was searching for some help and I found the playbook path and ansible search paths. So now I needed to verify that. I found some ansible debugger and examples that were really useful!
So I used “debugger: on_failed” for my task 11. And could see the path:
So it is clear it was looking at the playbook dir.
So after fixing the path, I realised that I didn’t want to run everything and wanted to use tags so only the last part was executed.
/ansible master$ cat playbooks/gen-config.yaml
...
- name: 12- display result debug: msg: "Backup file is {{ load_config.shortname }} and result is: {{ load_config }}" tags: push_config
...
/ansible master$ ansible-playbook playbooks/gen-config.yaml --limit="r1" -vvv --tags "push_config"
One more thing, the output of ansible when you have dictionaries, it is not great. I checked this link and it is good for failures and with -vvvv. But for green outputs still not great: