This weekend I have tried something I had in mind of some time. Home-made marmalade!
I had done before membrillo! (quince) And it was great! Such a good memories came back. And you realize how is done the one you used to buy in shops…
I decided to try the same method with berries (strawberry, blueberries, rasberries, etc). The recipe is quite simple.
Ingredients
-1 kg of frozen berries (if you can get them fresh, even better)
– 100g sugar ( maybe you can add more)
– 1 glass recipient of 600ml. Disinfected with boiling water.
Process:
Heat up a big saucepan (middle heat), put the frozen berries and the sugar. Stir frequently.
The fruit will start to unfrozen. Once fruit is soft, reduce the heat a bit and keep stirring.
The fruits will release water so dont add any.
Once they are looking like a pure, taste with a spoon (dont burnt your tongue!!)
If you want to get rid of the big bits of fruit, use a hand blender.
Once you have the texture you want, it is done.
Let it cool off properly before transfer to the glass and then to the fridge.
Notes
– Dont add water!!!! If you do, the marmalade will be quite liquid.
– Sugar levels. This is quite personal. Most marmalades I have checked have at least 40% sugar. I have decided with a 10%. 1kg fruit, 100g sugar. To be honest, depending on the fruit, it can be still a bit acid and you can add more. In my next attempt I will try 150g sugar.
2nd Attempt:
I followed the same process but without adding water. Still it was very liquid so i used a cooking filter to drain the mix and the result was quite good! Now it is more solid and you can drink the liquid (nothing to waste), it is super tasty!!!
I finished this book yesterday. This was my first book from Cory Doctorow, I have heard about him for some time about his support for digital freedom and his blogging (never read it though). Somehow I decided to read something from I chose this book as it seemed the latest. And to be honest, I am glad I did it because I liked it. I didnt know what to expect the four novellas really hit the nail on the head in the main issues of our society:
1- Immigration – Digital freedom – Social connection – Social classes – Youth against injustice
2- Racism – even superpowers can “fix” it – America blind eye (and the whole world to be honest)
4- Clean water, Global instability, Violence, Social disconnection
I have the feeling that you can see the current work in each history. In one part you think we are doomed but there is always a spot of hope. And it is just “having hope”, it is taking action.
And I learned that the DMCA was signed by a Democrat…. good b-job Clinton…
And I want to use more often Tor more often. Just for browsing it is really easy.
I get mad whenever I hear “work hard” lately. What the f* that means? Do I need to stay in my desk for 16 hours every day? This is what I understand for working hard. I am subscribed to the SDN mail list of IPSpace and this week the email was about this topic and related to network automation. My former CTO told me one day “work smarter, not harder”. I am not very smart, but I try. And one key thing, it is focus.
To celebrate a new lockdown season, I wanted to cook an apple pie like my mum used to make and I think I found a recipe that looks like that.
Ingredients:
1- 150g of biscuits smashed (my tin was a bit bigger than the video)
2- 70g melted butter
3- 8 apples, peeled and core removed – 6 for the sauce and 2 for decoration
4- 1 glass of milk (around 250ml)
5- 1 glass of plain flour (same glass as above)
6- 1/2 glass of suggar (same glass as above)
7- a pintch of cinnamon
8- Some tbsp of marmalade (or maple syrup as I ran out)
Process
1- Use a bit of butter to cover the bottom of your tin. Mix your crashed biscuits with the butter and fill the bottom of the tin. Be sure it looks like a firm surface. Put the tin in the fridge to cool down.
2- Pre-heat oven at 180C
3- In a blender, put the 6 chopped apples, milk, flour, sugar and cinnamon. After a couple of minutes, check everything is fully combined and liquid-like.
4- Take the tin from the bridge, and pour the apple mix on the tin. Be sure it is level. Then cut the other two apples in slices and cover the apple mix.
5- Put the cake in the over for around 60 minutes. The top should be brown and if you push a knife in the cake should come out clean.
6- Once the cake is out of the oven. Use the marmalade to bright up the surface of the cake.
7- Let the cake to cool in the fridge (1h) and ready to eat!
I actually liked it and I think it is similar to the one I used to have as a kid. Good memories!
I was already playing with gNMI and protobuf a couple of months ago. But this week I received a summary from the last NANOG80 meeting and there was a presentation about it. Great job from Colin!
So I decided to give it a go as the demo was based on docker and I have already my Arista lab in cEOS and vEOS as targets.
Ok, the container is created and seems running but the gnmi-gateway can’t connect to my cEOS r01….
First thing, I had to check iptables. It is not the first time that when playing with docker and building different environments (vEOS vs gnmi-gateway) with different docker commands, iptables may be not configured properly.
And it was the case again:
# iptables -t filter -S DOCKER-ISOLATION-STAGE-1
Warning: iptables-legacy tables present, use iptables-legacy to see them
-N DOCKER-ISOLATION-STAGE-1
-A DOCKER-ISOLATION-STAGE-1 -i br-43481af25965 ! -o br-43481af25965 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-94c1e813ad6f ! -o br-94c1e813ad6f -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-4bd17cfa19a8 ! -o br-4bd17cfa19a8 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-13ab2b6a0d1d ! -o br-13ab2b6a0d1d -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-121978ca0282 ! -o br-121978ca0282 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-00db5844bbb0 ! -o br-00db5844bbb0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
So I moved the new docker bridge network for gnmi-gateway after “ACCEPT” and solved.
# iptables -t filter -D DOCKER-ISOLATION-STAGE-1 -j ACCEPT
# iptables -t filter -I DOCKER-ISOLATION-STAGE-1 -j ACCEPT
#
# iptables -t filter -S DOCKER-ISOLATION-STAGE-1
Warning: iptables-legacy tables present, use iptables-legacy to see them
-N DOCKER-ISOLATION-STAGE-1
-A DOCKER-ISOLATION-STAGE-1 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i br-43481af25965 ! -o br-43481af25965 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-94c1e813ad6f ! -o br-94c1e813ad6f -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-4bd17cfa19a8 ! -o br-4bd17cfa19a8 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-13ab2b6a0d1d ! -o br-13ab2b6a0d1d -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-121978ca0282 ! -o br-121978ca0282 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-00db5844bbb0 ! -o br-00db5844bbb0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
#
So, restarted gnmi-gateway, still same issue. Ok, I decided to check if the packets were actually hitting r01.
So at first sight, the tcp handshake is established but then there is TCP RST….
So I double checked that gnmi was runnig in my side:
r1#show management api gnmi
Enabled: Yes
Server: running on port 3333, in MGMT VRF
SSL Profile: none
QoS DSCP: none
r1#
At that moment, I thought that was an issue in cEOS… checking logs I couldnt see any confirmation but I decided to give it a go with vEOS that is more feature rich. So I turned up my GCP lab and followed the same steps with gnmi-gateway. I updated the targets.json with the details of one of my vEOS devices. And run again:
~/gnmi/gnmi-gateway release$ sudo docker run -it --rm -p 59100:59100 -v $(pwd)/examples/gnmi-prometheus/targets.json:/opt/gnmi-gateway/targets.json --name gnmi-gateway-01 --network gnmi-net gnmi-gateway:latest
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Starting GNMI Gateway."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Clustering is NOT enabled. No locking or cluster coordination will happen."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Starting connection manager."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Starting gNMI server on 0.0.0.0:9339."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Starting Prometheus exporter."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Connection manager received a target control message: 1 inserts 0 removes"}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Initializing target gcp-r1 ([192.168.249.4:3333]) map[NoTLS:yes]."}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Target gcp-r1: Connecting"}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Target gcp-r1: Subscribing"}
{"level":"info","time":"2020-11-07T19:22:20Z","message":"Starting Prometheus HTTP server."}
{"level":"info","time":"2020-11-07T19:22:30Z","message":"Target gcp-r1: Disconnected"}
E1107 19:22:30.048410 1 reconnect.go:114] client.Subscribe (target "gcp-r1") failed: client "gnmi" : client "gnmi" : Dialer(192.168.249.4:3333, 10s): context deadline exceeded; reconnecting in 552.330144ms
{"level":"info","time":"2020-11-07T19:22:40Z","message":"Target gcp-r1: Disconnected"}
E1107 19:22:40.603141 1 reconnect.go:114] client.Subscribe (target "gcp-r1") failed: client "gnmi" : client "gnmi" : Dialer(192.168.249.4:3333, 10s): context deadline exceeded; reconnecting in 1.080381816s
Again, same issue. Let’s see from vEOS perspective.
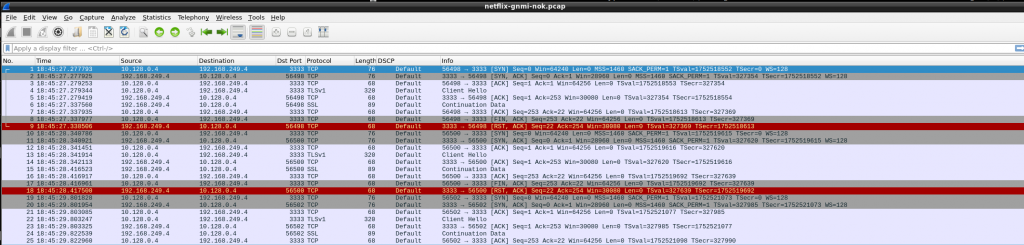
So again in GCP, tcp is established but then TCP RST. As vEOS is my last resort, I tried to dig into that TCP connection. I downloaded a pcap to analyze with wireshark so get a better visual clue…
So, somehow, gnmi-gateway is trying to negotiate TLS!!! As per my understanding, my targets.json was configured with “NoTLS”: “yes” so that should be avoid, shouldn’t be?
At that moment, I wanted to know how to identfiy TLS/SSL packets using tcpdump as it is not always that easy to get quickly a pcap in wireshark. So I found the answer here:
bash-4.2# tcpdump -i any "tcp port 3333 and (tcp[((tcp[12] & 0xf0) >> 2)] = 0x16)"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes
19:47:01.367197 In 1e:3d:5b:13:d8:fe (oui Unknown) ethertype IPv4 (0x0800), length 320: 10.128.0.4.50486 > 192.168.249.4.dec-notes: Flags [P.], seq 2715923852:2715924104, ack 2576249027, win 511, options [nop,nop,TS val 1194424180 ecr 1250876], length 252
19:47:02.405870 In 1e:3d:5b:13:d8:fe (oui Unknown) ethertype IPv4 (0x0800), length 320: 10.128.0.4.50488 > 192.168.249.4.dec-notes: Flags [P.], seq 680803294:680803546, ack 3839769659, win 511, options [nop,nop,TS val 1194425218 ecr 1251136], length 252
19:47:04.139458 In 1e:3d:5b:13:d8:fe (oui Unknown) ethertype IPv4 (0x0800), length 320: 10.128.0.4.50490 > 192.168.249.4.dec-notes: Flags [P.], seq 3963338234:3963338486, ack 1760248652, win 511, options [nop,nop,TS val 1194426952 ecr 1251569], length 252
Not something easy to remember 🙁
Ok, I wanted to be sure that gnmi was functional in vEOS and by a quick internet look up, I found this project gnmic! Great job by the author!
So I configured the tool and tested with my vEOS. And worked (without needing TLS)
So, I kind of I was sure that my issue was configuring gnmi-gateway. I tried to troubleshoot it: removed the NoTLS, using the debugging mode, build the code, read the Go code for Target (too complex for my Goland knowledge 🙁 )
So at the end, I gave up and opened an issue with gnmi-gateway author. And he answered super quick with the solution!!! I misunderstood the meaning of “NoTLS” 🙁
So I followed his instructions to configure TLS in my gnmi cEOS config
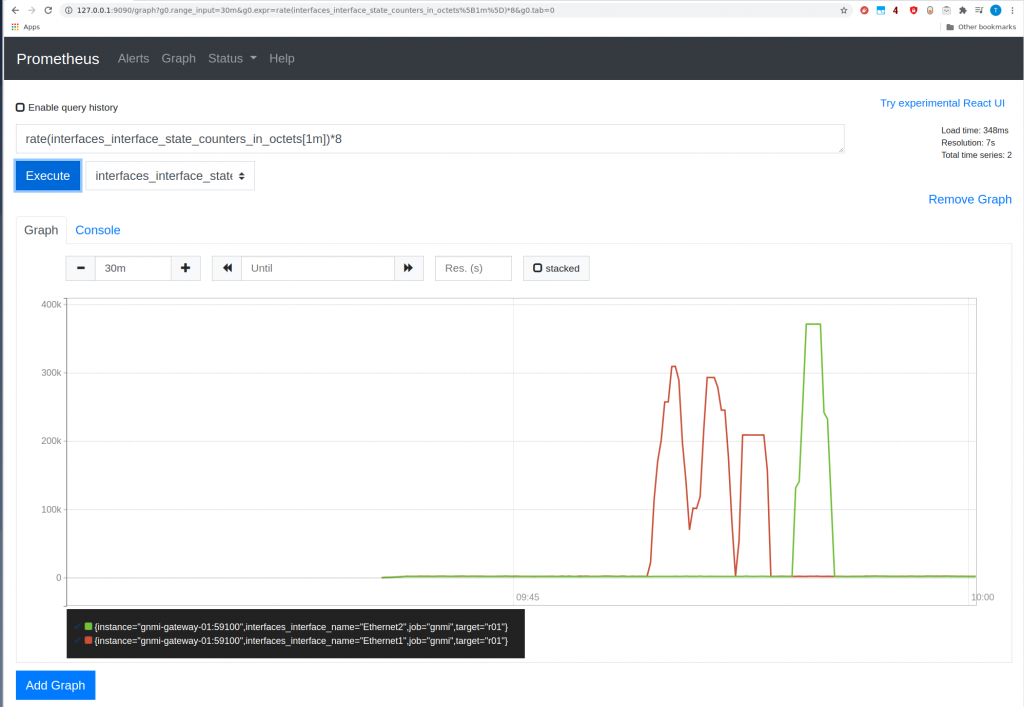
Now we can open prometheus UI and verify if we are consuming data from cEOS r01.
Yeah! it is there.
So all working at then. It has a nice experience. At the end of the day, I want to know more about gNMI/protobuffer, etc. The cold thing here is you can get telemetry and configuration management of your devices. So using gnmi-gateway (that is more for a high availability env like Netflix) and gnmic are great tools to get your head around.
Another dish I wanted to try for some time has been pisto. I had to be a teenager since last time. I found several good videos like this. But I tried to do it my way.
Ingredients:
1 courgette
1 big potato
1 big onion
2-3 garlic cloves
3 peppers (red, green, whatever)
Salt, olive oil, any spice you fancy
1 can tomato sauce
Process
1- Preheat oven at 200C
2- Chop your vegetables, put everything in a tray. Add salt, spices and coat in oil everything.
3- Put the tray in the oven, kind of 30 minutes. Be sure, they dont burn!
4- Heat up a frying pan. Add some oil, add the can of tomato sauce. Stir, add a bit of salt, and sugar (optional). It should thicken up a bit.
5- Once your vegs are grilled, add them to the tomate sauce (dont throw the liquid from the tray). Stir everything for some minutes and ready to serve.
6- Optional, you can fry an egg and add it on top!
I am not good at cooking curry dishes but there is one I wanted to try. I found a video that I liked and gave it a try.
Curry Sauce:
a bit of olive oil to fry (2tsp)
2 onions
2 carrots
5 garlic cloves
1 apple
1 tsp honey
2 tsp flour
4 tsp curry mild powder
2 tsp garam masala
4 tp soy sauce
500ml water + 2 chicken stock cubes
1/2 can coconut milk
Chicken:
2 big chicken breasts
bread crumbs
1 egg
flour
olive oil for frying
Rice
1 cup of rice + 1 1/2 cup of water
1/2 can coconut milk
Process for curry
1- Fry in a pan the chopped onions, carrots, apple and garlic. Stir for 4-5 minutes. Onions should soft a bit.
2- Add the flour, curry, garam masala, coconut milk, honey, soy sauce. Stir everything properly. It should be like a paste. Start adding the chicken stock. Leave it simmer for kind of 30 minutes, while you prepare the chicken and rice.
3- Heat another pan with the olive oil (you are not deep frying…)
4- Prepare the chicken breast. I pounce the chicken breast to make a bit flat. Then pass the chicken first via the flour, properly coated, then pass via the egg, properly coated,then finally via the bread crumbs, properly coated.
5- Fry the chicken, golden in both sides.
6- Boil your 1 1/2 water, put it in another pan, add the rice and the 1/2 can of coconut. Let it cook at middle heat.
7- Once the chicken is fried, the rice ready. It is time to finalize the sauce. I pass the sauce with a hand blender, I dont want to waste all ingredients and take only the liquid. I dont like to waste food.
The result was really good! I have good for a week!
Today finally I have managed to get a very basic cumulus setup. It is annoying because I tried several months ago and found some issues with libvirt (and I opened a ticket but didnt follow up) and gave up.
Now it works. I just want to use KVM-QEMU and Vagrant, that I have already installed in my system. So based on the link, I just created a folder and copied the vagrant file. Then “vagrant up” and wait.
/cumulus/1s2l$ vagrant up
Bringing machine 'spine01' up with 'libvirt' provider…
Bringing machine 'leaf01' up with 'libvirt' provider…
Bringing machine 'leaf02' up with 'libvirt' provider…
==> leaf01: Box 'CumulusCommunity/cumulus-vx' could not be found. Attempting to find and install…
leaf01: Box Provider: libvirt
leaf01: Box Version: 4.2.0
==> leaf01: Loading metadata for box 'CumulusCommunity/cumulus-vx'
leaf01: URL: https://vagrantcloud.com/CumulusCommunity/cumulus-vx
==> leaf01: Adding box 'CumulusCommunity/cumulus-vx' (v4.2.0) for provider: libvirt
leaf01: Downloading: https://vagrantcloud.com/CumulusCommunity/boxes/cumulus-vx/versions/4.2.0/providers/libvirt.box
Download redirected to host: d2cd9e7ca6hntp.cloudfront.net
==> leaf01: Successfully added box 'CumulusCommunity/cumulus-vx' (v4.2.0) for 'libvirt'!
==> spine01: Box 'CumulusCommunity/cumulus-vx' could not be found. Attempting to find and install…
spine01: Box Provider: libvirt
spine01: Box Version: 4.2.0
==> leaf01: Uploading base box image as volume into Libvirt storage…
==> spine01: Loading metadata for box 'CumulusCommunity/cumulus-vx'
spine01: URL: https://vagrantcloud.com/CumulusCommunity/cumulus-vx
Progress: 0%==> spine01: Adding box 'CumulusCommunity/cumulus-vx' (v4.2.0) for provider: libvirt
Progress: 0%==> leaf02: Box 'CumulusCommunity/cumulus-vx' could not be found. Attempting to find and install…
leaf02: Box Provider: libvirt
leaf02: Box Version: 4.2.0
Progress: 1%==> leaf02: Loading metadata for box 'CumulusCommunity/cumulus-vx'
leaf02: URL: https://vagrantcloud.com/CumulusCommunity/cumulus-vx
==> leaf02: Adding box 'CumulusCommunity/cumulus-vx' (v4.2.0) for provider: libvirt
==> leaf01: Creating image (snapshot of base box volume).
==> spine01: Creating image (snapshot of base box volume).
==> leaf02: Creating image (snapshot of base box volume).
==> leaf01: Creating domain with the following settings…
==> leaf01: -- Name: 1s2l_leaf01
==> leaf02: Creating domain with the following settings…
==> spine01: Creating domain with the following settings…
==> leaf02: -- Name: 1s2l_leaf02
==> spine01: -- Name: 1s2l_spine01
==> leaf01: -- Domain type: kvm
==> leaf02: -- Domain type: kvm
==> spine01: -- Domain type: kvm
==> leaf01: -- Cpus: 1
==> leaf02: -- Cpus: 1
==> spine01: -- Cpus: 1
==> leaf01: -- Feature: acpi
==> leaf02: -- Feature: acpi
==> spine01: -- Feature: acpi
==> leaf01: -- Feature: apic
==> leaf01: -- Feature: pae
==> leaf01: -- Memory: 768M
==> leaf02: -- Feature: apic
==> spine01: -- Feature: apic
==> spine01: -- Feature: pae
....
....
You can check the VMs are up:
/cumulus/1s2l$ vagrant status
Current machine states:
spine01 running (libvirt)
leaf01 running (libvirt)
leaf02 running (libvirt)
This environment represents multiple VMs. The VMs are all listed
above with their current state. For more information about a specific
VM, run vagrant status NAME.
/cumulus/1s2l$
And we can login and create some network interfaces as per documentation:
/cumulus/1s2l$ vagrant ssh leaf01
Linux leaf01 4.19.0-cl-1-amd64 #1 SMP Cumulus 4.19.94-1+cl4u5 (2020-07-10) x86_64
Welcome to Cumulus VX (TM)
Cumulus VX (TM) is a community supported virtual appliance designed for
experiencing, testing and prototyping Cumulus Networks' latest technology.
For any questions or technical support, visit our community site at:
http://community.cumulusnetworks.com
The registered trademark Linux (R) is used pursuant to a sublicense from LMI,
the exclusive licensee of Linus Torvalds, owner of the mark on a world-wide
basis.
vagrant@leaf01:mgmt:~$ net add interface swp1,swp2,swp3
vagrant@leaf01:mgmt:~$ net commit
--- /etc/network/interfaces 2020-07-15 01:15:58.000000000 +0000
+++ /run/nclu/ifupdown2/interfaces.tmp 2020-10-31 14:12:30.826000000 +0000
@@ -5,15 +5,24 @@
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet dhcp
vrf mgmt
+auto swp1
+iface swp1
+
+auto swp2
+iface swp2
+
+auto swp3
+iface swp3
+
auto mgmt
iface mgmt
address 127.0.0.1/8
address ::1/128
vrf-table auto
net add/del commands since the last "net commit"
User Timestamp Command
------- -------------------------- --------------------------------
vagrant 2020-10-31 14:12:27.070219 net add interface swp1,swp2,swp3
vagrant@leaf01:mgmt:~$
And after configuring the interfaces in the three VMs, we have LLDP working:
/cumulus/1s2l$ vagrant ssh leaf01
Linux leaf01 4.19.0-cl-1-amd64 #1 SMP Cumulus 4.19.94-1+cl4u5 (2020-07-10) x86_64
Welcome to Cumulus VX (TM)
Cumulus VX (TM) is a community supported virtual appliance designed for
experiencing, testing and prototyping Cumulus Networks' latest technology.
For any questions or technical support, visit our community site at:
http://community.cumulusnetworks.com
The registered trademark Linux (R) is used pursuant to a sublicense from LMI,
the exclusive licensee of Linus Torvalds, owner of the mark on a world-wide
basis.
Last login: Sat Oct 31 14:12:04 2020 from 10.255.1.1
vagrant@leaf01:mgmt:~$
vagrant@leaf01:mgmt:~$
vagrant@leaf01:mgmt:~$
vagrant@leaf01:mgmt:~$ net show lldp
LocalPort Speed Mode RemoteHost RemotePort
--------- ----- ------- ---------- ----------
swp1 1G Default spine01 swp1
swp2 1G Default leaf02 swp2
swp3 1G Default leaf02 swp3
vagrant@leaf01:mgmt:~$
vagrant@leaf01:mgmt:~$ net show system
Hostname……… leaf01
Build………… Cumulus Linux 4.2.0
Uptime……….. 0:06:09.180000
Model………… Cumulus VX
Memory……….. 669MB
Vendor Name…… Cumulus Networks
Part Number…… 4.2.0
Base MAC Address. 52:54:00:17:87:07
Serial Number…. 52:54:00:17:87:07
Product Name….. VX
vagrant@leaf01:mgmt:~$ exit
So I am happy because now I have something to play with and try to build an MPLS lab with cumulus. At some point I would like to try some quaga/frr lab.
I am pretty sure that in the past, I didnt have to type my password every single time I run a vagrant command….
Ok, we can shutdown the VMs and start the work for the next time:
/cumulus/1s2l$ vagrant halt spine01 leaf01 leaf02
==> leaf02: Halting domain…
==> leaf01: Halting domain…
==> spine01: Halting domain…
/cumulus/1s2l$
/cumulus/1s2l$
/cumulus/1s2l$ vagrant status
Current machine states:
spine01 shutoff (libvirt)
leaf01 shutoff (libvirt)
leaf02 shutoff (libvirt)
This environment represents multiple VMs. The VMs are all listed
above with their current state. For more information about a specific
VM, run vagrant status NAME.
/cumulus/1s2l$
I finished reading this book last night. To be honest, it has been hard to read and digest. Very hardcore philosophical for my level. To put things a bit on perspective, the book was written on 1954… and half way the book you realize that things he talks about are still pretty valid nowadays. Without noticing, he is taking a approach to Easter philosophy (Buddhism) in contrast to the Western one. We are very focus in the “I”, in the material world, etc. We try to get things defined as something static and we need that for security. Our brain is the one leading the shots but taking a different approach, accepting the insecurity (you can’t control everything, you can’t know everything) you can live a less stressful and meaningful life.
Again, this is the typical book I should read 30 times to get really a full understanding.
Today I came across a video (not recent) about Cristian Varela (strange there is no Wikipedia entry about him). He is one of my favourite techno DJs and a legend in the Spanish Techno scene. I learnt a couple of things from that video, he is the son of a famous Spanish actor, he is working in different projects apart from “just” techno gigs and production, and he went through a sharp drop in his career but he is back (how important is to have good people around…)
As somebody very wise told me: “Techno always makes friends”