I checked out this blog note from Google about Falcon. To be honest, I dont really understand the “implementation”. Is it purely software? Does it interact with merchant Ethernet silicon ASICs? There is so much happening trying to get Ethernet similar to Infiniband that I am wonder how this fits outside Google infra. At the end of the day, Ethernet has been successful because everybody could use it for nearly anything. Just my opinion.
Category: networks
Ring Memory
Reading this news I was surprised by the mentioned paper where LLM can take up to millions of tokens. My knowledge of LLM infrastucture is very little (and the paper is a bit beyond me…) but I thought the implementation of this models followed kind of “chain/waterfall” where the output of some GPUs fed other GPUs.
LLM: hardware connection
Good article about LLM from the hardware/networks perspective. I liked it wasnt a show-off from Juniper products, as I haven’t seen any mention of Juniper kit in deployments of LLM in cloud providers, hyperscalers, etc. The points about Infiniband (the comment at the end about the misconceptions of IB is funny) and ethernet were not new but I liked the VOQ reference.
Still as a network engineer, I feel I am missing something about how to make the best network deployment for training LLM.
Infiniband Essentials
NVIDIA provides this course for free. Although I surprised that there is no much “free” documentation about this technology. I wish they follow the same path as most networking vendors where they want you to learn their technology without much barriers. And it is quite pathetic that you can’t really find books about it…
The course is very very high level and very very short. So I didnt become an Infiniband CCIE…
- Intro to IB
— Elements of IB: IB switch, Subnet Manager (it is like a SDN controller), hosts (clients), adaptors (NICs), gateways (convert IB <> Ethernet) and IB routers.
- Key features
— Simplify mgmt: because of the Subnet Manager
— High bw: up to 400G)
— Cpu offload: RDMA, bypass OS.
— Ultra low latency: 1us host to host.
— Network scale-out: 48k nodes in a single subnet. You can connect subnets using IB router.
— QoS: achieve loss-less flows.
— Fabric resilience: Fast-ReRouting at switch level takes 1ms compared with 5s using Traffic Manager => Self-Healing
— Optimal load-balancing: using AR (adaptive routing). Rebalance packets and flows.
–MPI super performance (SHARP – scalable hierarchical aggregation and reduction protocol): off-load operations from cpu/gpu to switches -> decrease the retransmissions from end hosts -> less data sent. Dont really understand this.
— Variety of supported topologies: fat-tree, dragonfly+, torus, hypercurve and hyperx.
- Architecture:
— Similar layers as OSI model: application, transport, network, link and physical.
— In IB, applications connect to NIC, bypass OS.
— Upper layer protocol:
— MPI: Message Passing Interface
— NCCL: NVIDIA Collective Communication Library
— iSEB: RDMA storage protocols.
— IPoIB: IP over IB
— Transport Layer: diff from tcp/ip, it creates an end-to-end virtual channel between applications (source and destination), bypassing OS in both ends.
— Network Layer: This is mainly at IB routers to connect IB subnets. Routers use GID as identifier for source and destinations.
— Link Layer: each node is identified by a LID (local ID), managed by the Subnet Manager. Switch has a forwarding table with “port vs LID” <- generated by Subnet Manager. You have flow-control for providing loss-less connections.
— Physical Layer: Support for copper (DAC) and optical (AOC) connectors.
AI Supercomputer – NVLink
So NVIDIA has an AI supercomputer via this. Meta, Google and MS making comments about it. And based on this, it is a 24 racks setup using 900GBps NVLink-C2C interface, so no ethernet and no infiniband. Here, there is a bit more info about NVLink:
NVLink Switch System forms a two-level, non-blocking, fat-tree NVLink fabric to fully connect 256 Grace Hopper Superchips in a DGX GH200 system. Every GPU in DGX GH200 can access the memory of other GPUs and extended GPU memory of all NVIDIA Grace CPUs at 900 GBps.
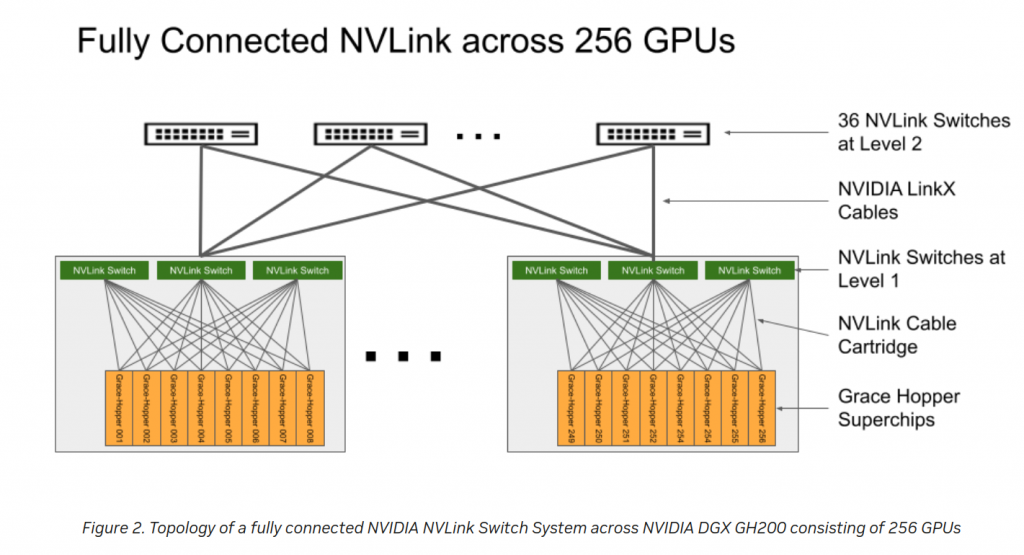
This is the official page for NVlink but only with the above I understood this is like a “new” switching infrastructure.
But looks like if you want to connect up those supercomputers, you need to use infiniband. And again power/cooling is a important subject.
Jericho3-vs-Infiniband
Jericho3 is the new chip from Broadcom to take into NVIDIA infiniband. From that article, I dont really understand the “Ramon3” fabric. It seems it can support 18 ports at 800G (based on 144 serdes at 100G). It has 160 SerDes (16Tbs) for uplink to Ramon3. The goal is to reduce the time the nodes wait on the network so it is not just (port to port) latency. Based on Broadcom testing swapping a 200Gb Infiniband switch with a Jericho3 is 10% better. As well, dont understand what they mean by “perfect load balancing” because the flow size matters (from my point of view) and “congestion free”. Having this working at scale… looks interesting…
But then we have the answer from NVIDIA: spectrum-X. So it is Spectrum-4 switches, with Bluefield3 DPU and software optimization. This is an Ethernet platform. Spectrum-4 looks very impressive definitely. But this sentence, puzzles me “The world’s top hyperscalers are adopting NVIDIA Spectrum-X, including industry-leading cloud innovators.” But most of links I have been reading lately are saying that Azure, Meta, Google are using Infiniband. Now NVIDIA says top hyperscales are adopting Spectrum-X, when Spectrum-4 started shipping this quarter?
And finally, why NVIDIA is pushing for Ethernet and Infiniband? I think this is a good link for that. Based on NVIDIA CEO, Infiniband is great and nearly “free” if you build for very specific application (supercomputers, etc). But for multi-tenant, you want Ethernet. So that kind of explains why hyperscalers likeAWS, GCP, Azure want at the end of the day Ethernet, at least for customers access. At the end of the day, if you have just one (commodity) network, it is cheaper and easier to run/maintain. You dont have a vendor lock like IB.
Will see what happens with all these crazy AI/LLM/ML etc.
AMD MI300 + Meta DC
Reading different articles: 1, 2, 3 I was made aware of this new architecture of CPU-GPU-HMB3 from AMD.
As well, Meta has a new DC design for ML/AI using Nvidia and Infiniband.
Now, Meta – working with Nvidia, Penguin Computing and Pure Storage – has completed the second phase of the RSC. The full system includes 2,000 DGX A100 systems, totaling a staggering 16,000 A100 GPUs. Each node has dual AMD Epyc “Rome” CPUs and 2TB of memory. The RSC has up to half an exabyte of storage and, according to Meta, one of the largest known flat InfiniBand fabrics in the world, with 48,000 links and 2,000 switches. (“AI training at scale is nothing if we cannot supply the data fast enough to the GPUs, right?” said Kalyan Saladi – a software engineer at Meta – in a presentation at the event.)
An again, cooling is critical.
Fat Tree – Drangonfly – OpenAI infra
I haven’t played much with ChatGPT but my first question was “how is the network infrastructure for building something like ChatGPT?” or similar. Obviously I didnt have the answer I was looking for and I think i think ask properly neither.
Today, I came to this video and at 3:30 starts something very interesting as this is an official video as says the OpenAI cluster built in 2020 for ChatGTP was actullay based on 285k AMD CPU “infinibad” plus 10k V100 GPU “infiniband” connected. They dont mention more lower level details but looks like two separated networks? And I have seen in several other pages/videos, M$ is hardcode in infiniband.
Then regarding the infiniband architectures, it seems the most common are “fat-tree” and “dragon-fly”. This video is quite good although I have to watch it again (or more) to fully understand.
These blog, pdf and wikipedia (high level) are good for learning about “Fat-Tree”.
Although most info I found is “old”, these technologies are not old. Frontier and looks like most of supercomputers use it.
Meta Chips – Colvore water-cooling – Google AI TPv4 – NCCL – PINS P4 – Slingshot – KUtrace
Read 1. Meta to build its own AI chips. Currently using 16k A100 GPU (Google using 26k H100 GPU). And it seems Graphcore had some issues in 2020.
Read 2. Didnt know Colovore, interesting to see how critical is actually power/cooling with all the hype in AI and power constrains in key regions (Ashburn VA…) And with proper water cooling you can have a 200kw rack! And seems they have the same power as a 6x bigger facility. Cost of cooling via water is cheaper than air-cooled.
Read 3. Google one of biggest NVIDIA GPU customer although they built TPUv4. MS uses 10k A100 GPU for training GPT4. 25k for GPT5 (mix of A100 and H100?) For customer, MS offers AI supercomputer based on H100, 400G infiniband quantum2 switches and ConnectX-7 NICs: 4k GPU. Google has A3 GPU instanced treated like supercomputers and uses “Apollo” optical circuit switching (OCS). “The OCS layer replaces the spine layer in a leaf/spine Clos topology” -> interesting to see what that means and looks like. As well, it uses NVSwitch for interconnect the GPUs memories to act like one. As well, they have their own (smart) NICS (DPU data processing units or infrastructure processing units IPU?) using P4. Google has its own “inter-server GPU communication stack” as well as NCCL optimizations (2016! post).
Read4: Via the P4 newletter. Since Intel bought Barefoot, I kind of assumed the product was nearly dead but visiting the page and checking this slides, it seems “alive”. Sonic+P4 are main players in Google SDN.
“Google has pioneered Software-Defined Networking (SDN) in data centers for over a decade. With the open sourcing of PINS (P4 Integrated Network Stack) two years ago, Google has ushered in a new model to remotely configure network switches. PINS brings in a P4Runtime application container to the SONiC architecture and supports extensions that make it easier for operators to realize the benefits of SDN. We look forward to enhancing the PINS capabilities and continue to support the P4 community in the future”
Read5: Slingshot is another switching technology coming from Cray supercomputers and trying to compete with Infiniband. A 2019 link that looks interesting too. Paper that I dont thik I will be able to read neither understand.
Read6: ISC High Performance 2023. I need to try to attend one of these events in the future. There are two interesting talks although I doubt they will provide any online video or slides.
– Talk1: Intro to Networking Technologies for HPC: “InfiniBand (IB), High-speed Ethernet (HSE), RoCE, Omni-Path, EFA, Tofu, and Slingshot technologies are generating a lot of excitement towards building next generation High-End Computing (HEC) systems including clusters, datacenters, file systems, storage, cloud computing and Big Data (Hadoop, Spark, HBase and Memcached) environments. This tutorial will provide an overview of these emerging technologies, their offered architectural features, their current market standing, and their suitability for designing HEC systems. It will start with a brief overview of IB, HSE, RoCE, Omni-Path, EFA, Tofu, and Slingshot. In-depth overview of the architectural features of IB, HSE (including iWARP and RoCE), and Omni-Path, their similarities and differences, and the associated protocols will be presented. An overview of the emerging NVLink, NVLink2, NVSwitch, Slingshot, Tofu architectures will also be given. Next, an overview of the OpenFabrics stack which encapsulates IB, HSE, and RoCE (v1/v2) in a unified manner will be presented. An overview of libfabrics stack will also be provided. Hardware/software solutions and the market trends behind these networking technologies will be highlighted. Sample performance numbers of these technologies and protocols for different environments will be presented. Finally, hands-on exercises will be carried out for the attendees to gain first-hand experience of running experiments with high-performance networks”
– Talk2: State-of-the-Art High Performance MPI Libraries and Slingshot Networking: “Many top supercomputers utilize InfiniBand networking across nodes to scale out performance. Underlying interconnect technology is a critical component in achieving high performance, low latency and high throughput, at scale on next-generation exascale systems. The deployment of Slingshot networking for new exascale systems such as Frontier at OLCF and the upcoming El-Capitan at LLNL pose several challenges. State-of-the-art MPI libraries for GPU-aware and CPU-based communication should adapt to be optimized for Slingshot networking, particularly with support for the underlying HPE Cray fabric and adapter to have functionality over the Slingshot-11 interconnect. This poses a need for a thorough evaluation and understanding of slingshot networking with regards to MPI-level performance in order to provide efficient performance and scalability on exascale systems. In this work, we delve into a comprehensive evaluation on Slingshot-10 and Slingshot-11 networking with state-of-the-art MPI libraries and delve into the challenges this newer ecosystem poses.”
Read7: Slides and Video. I was aware of Dtrace (although never used it) so not sure how to compare with KUtrace. I guess I will ask Chat-GPT 🙂
Read8: Python as programming of choice for AI, ML, etc.
Read9: M$ “buying” energy from fusion reactors.
VXLAN BGP EVPN Multisite
This is a video that explains high level about EVPN Multisite. There is no really config involved. The pdf for the session “BRKDCN-2913” is easy to find and download. Although this is NXOS based, Arista has similar feature called “EVPN Gateway”: https://www.arista.com/en/support/toi/eos-4-25-0f/14591-evpn-l3-gateway (needs registration….) Just one line really to add under the EVPN address family to change the next hop to the gateway’s address. The implementation looks much more simpler than NXOS….
This is a summary of the video:
RFC9014 … DCI EVPN Overlay defines the Layer-2 extension between two domains
section 3: decoupled gw. vland handoff with a WAN edge.
section 4: integrated gw: gw talk directly L2EVPN
multi-site (BESS version) draft-sharma-bess-multi-site-evpn. support extension of l2 and l3, uc and mc, vpns. BGW talk ebgp evpn AF.
gw mode: anycast vip (ecmp: underlay) or multipath vip (ecmp: under and overlay)
type5: re-originated.
RD: separate RD for vIP and PIP
RT: same for intra/inter dc
Border GW = EVPN GW
EVPN-IPVPN interop defines the Layer-3 extension between domains, currently lacks of EVPN to EVPN interconnects
Multisite draft combines RFC9014 and EVPN-IPVPN with EVPN to EVPN connection: https://datatracker.ietf.org/doc/html/draft-sharma-bess-multi-site-evpn-02
Use cases:
1- Compartmentalization:
- multiple fabrics, single DC
- control at BGW: allow extension l2,l3. Reduces remote VTEP count. Expands VTEP scale.
- BUM packet: LS replicated only in the fabric, then BGW to the BGW in the other fabric. In no multi-site, LS replicate to ALL VTEP in the fabric.
2- Scale
- control at BGW: Reduces remote VTEP count. Expands VTEP scale.
- scale thhrough hierarchy: multiply vtep with sites
up to 128 sites per multi-site domain. Up to 256 VTEP per fabric -> 32768 VTEPs
3- DC interconnect (DCI)
- IP reachability and MTU.
integration with legacy networks:
hybrid cloud connectivity: extends l3 with vrf awareness.
Deeper look:
HW support only important in BGW. LS is not important.
tunnels:
- stitched at BGW (no recirculation, hw rate)
- intra fabric tunnel goes LS to LS or LS to BFW
- inter fabric tunnel goes BGW to BGW
- only BGW IP must be unique.. Fabrics are “separated”.
BGW deployment considerations:
- 1) anycast bgw
- – up to 6 nodes. They are not interconnected, just share ASN nothing else.. In LS or SS
- – VIP mode: vip for tunnel stitching. foucs on scale and convergence. overlay ecpm
- – PIP mode: for 3rd party interop. Uses PIP for tunnel stitching. Uses under and overlay Ecmp.
- 2) vpc bgw:
- – only 2 (because vpc, peer link). Only in LS
– legacy network integration, attachment of fw and adcs.
NOTE: anycast and vpc must have a multi-site vip and PIP. only vpc needs an extra IP for VPC IP.
PIP needed for establishing BGP and for Designated Forwarding election (only one BGW forwards per vlan.
CP and DP:
- As eBGP uses betweem multi-sites -> ebgp changes NH => vxlan tunnel termination and re-origination + loop prevention (as-path). Full mesh ebgp evpn between sites.
- underlay/overlay CP deployemnt: recommended IEI (recommended) within fabric: IGP as underlay, iBGP as overlay.
- full mesh ebgp evpn between site OR deploy RS (route-server) -> RS is in a separate AS and only does CP = eBGP RR (RFC 7947): evpn routes reflection, NH unchanged, RT rewrite!
I think this is the white paper mentioned: https://www.cisco.com/c/en/us/products/collateral/switches/nexus-9000-series-switches/white-paper-c11-739942.html
Another thing, I wish it wouldnt be that painful to simulate NXOS. It is so easy spin up a lab with cEOS…..in a standard laptop..