SoO is something that I have read and I forget often so trying to stick it in my mind here. Found this link that I think it is quite good.
Definition:
Ensuring a loop-free network in particular multi-homed MPLS Layer 3 VPN sites. BGP SoO is a tag that is appended on BGP updates to allow a peer (PE) to mark a particular prefix as belonging to a particular site. In certain MPLS L3 VPN configurations, the BGP AS-Path may not provide the granularity needed to prevent a loop in the control-plane. For example when your CPEs in a site peers with PEs (multisite) from the SP using the same ASN, that means you need to use "allow-as in" in your CPEs.
Scenario:
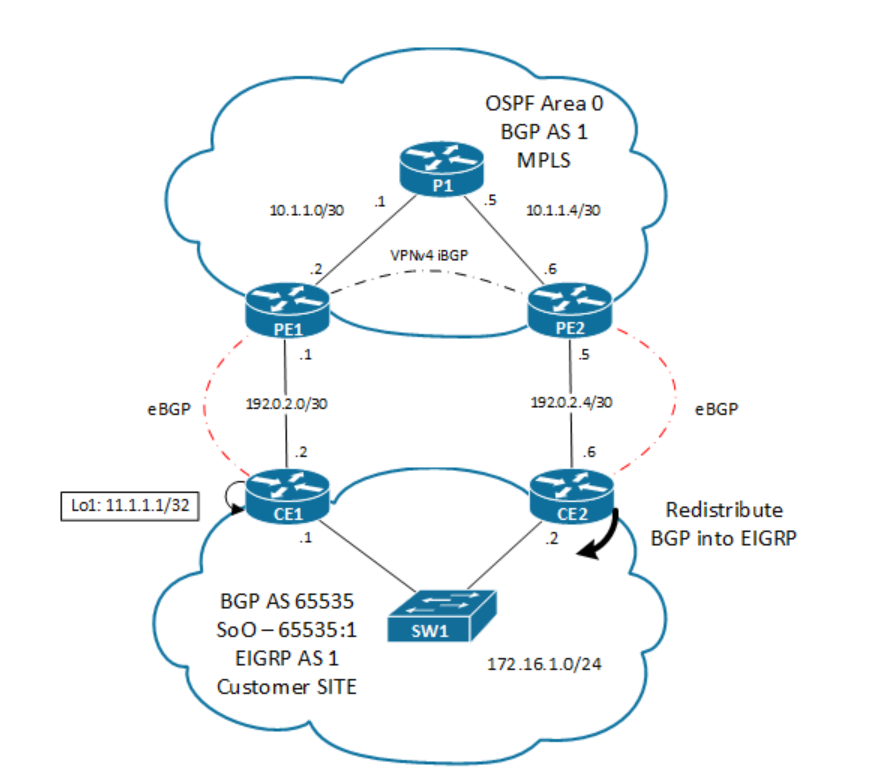
This scenario has two issues:
- Suboptimal routing
- Routing loop under failure.
Solution:
Configure a unique SoO code for each multihomed site on the PE routers.
This is just an intro as I want to create a lab with this.